Promptlar bilan tanishuv
Prompt — bu modelga biror vazifani bajarish uchun beriladigan ko'rsatma. Vazifa "Nol raqamini kim ixtiro qilgan?" kabi oddiy savolga javob berish bo'lishi mumkin. Yoki u mahsulot g'oyangiz uchun raqobatchilarni o'rganish, noldan veb-sayt yaratish yoki ma'lumotlaringizni tahlil qilish kabi ancha murakkabroq ham bo'lishi mumkin.
Prompt odatda quyidagi qismlarning bir yoki bir nechtasidan iborat bo'ladi:
-
Vazifa tavsifi: Modeldan nima qilishni xohlayotganingiz, jumladan, model qanday rol o'ynashi kerakligi va natija qanday formatda bo'lishi kerakligi.
-
Ushbu vazifani qanday bajarishga doir misol(lar): Masalan, agar siz modeldan matndagi toksiklikni aniqlashni xohlasangiz, toksiklik va toksik bo'lmagan holatlar qanday ko'rinishda bo'lishiga bir nechta misollar keltirishingiz mumkin.
-
Vazifaning o'zi: Model bajarishi kerak bo'lgan aniq vazifa, masalan, javob berilishi kerak bo'lgan savol yoki qisqartirilishi kerak bo'lgan kitob.
5-1-rasmda NER (nomlangan obyektlarni aniqlash) vazifasi uchun ishlatilishi mumkin bo'lgan juda oddiy prompt ko'rsatilgan.

Promptlash ishlashi uchun model ko'rsatmalarga amal qila olishi kerak. Agar model bu borada yomon ishlasa, promptingiz qanchalik yaxshi bo'lishidan qat'i nazar, model unga amal qila olmaydi. Modelning ko'rsatmalarga amal qilish qobiliyatini qanday baholash 4-bobda muhokama qilingan.
Qancha prompt muhandisligi kerakligi modelning prompt o'zgarishlariga (perturbation) qanchalik chidamli ekanligiga bog'liq. Agar prompt biroz o'zgarsa — masalan, "besh" o'rniga "5" deb yozilsa, yangi qator qo'shilsa yoki harflar kattaligi o'zgartirilsa — modelning javobi keskin o'zgaradimi? Model qanchalik chidamsiz bo'lsa, shunchalik ko'p sinab ko'rish talab etiladi.
Modelning chidamliligini o'lchash uchun natija qanday o'zgarishini ko'rish maqsadida promptlarni tasodifiy ravishda o'zgartirib ko'rishingiz mumkin. Xuddi ko'rsatmalarga amal qilish qobiliyati kabi, modelning chidamliligi ham uning umumiy imkoniyatlari bilan chambarchas bog'liq. Modellar kuchaygani sari, ular ham chidamliroq bo'lib boradi. Bu mantiqan to'g'ri, chunki aqlli model "5" va "besh" bir xil ma'noni anglatishini tushunishi kerak.1 Shu sababli, kuchliroq modellar bilan ishlash ko'pincha sizni bosh og'rig'idan xalos qilishi va turli variantlarni sinab ko'rishga sarflanadigan vaqtni kamaytirishi mumkin.
Maslahat
Siz uchun qaysi biri eng yaxshi ishlashini aniqlash uchun turli xil prompt strukturalari bilan tajriba qilib ko'ring. Aksariyat modellar, jumladan
GPT-4ham, vazifa tavsifi promptning boshida kelganda tajribaga ko'ra yaxshiroq ishlaydi. Biroq, ba'zi modellar, masalanLlama 3, vazifa tavsifi promptning oxirida kelganda yaxshiroq ishlaydigandek tuyuladi.
Kontekstual o'rganish: Nol misolli va Kam misolli yondashuvlar
Modellarga promptlar orqali nima qilishni o'rgatish, shuningdek, kontekstual o'rganish (in-context learning) deb ham ataladi. Bu atama Brown va boshqalar (2020) tomonidan GPT-3 haqidagi “Til Modellari — Kam Misolli O'rganuvchilardir” (“Language Models Are Few-shot Learners”) nomli maqolada ilk bor qo'llanilgan. An'anaviy usulda, model kerakli xatti-harakatni o'qitish — jumladan, dastlabki o'qitish, yakuniy o'qitish va finetuning — davomida o'rganadi, bu esa model og'irliklarini (weights) yangilashni o'z ichiga oladi. GPT-3 haqidagi maqolada esa til modellari kerakli xatti-harakatni promptdagi misollardan o'rgana olishi namoyish etilgan, hatto bu xatti-harakat model dastlab o'qitilgan vazifadan farq qilsa ham. Bunda og'irliklarni yangilash talab etilmaydi. Aniqroq aytganda, GPT-3 keyingi tokenni bashorat qilish uchun o'qitilgan, lekin maqolada GPT-3 kontekstdan foydalanib tarjima qilishni, o'qib tushunishni, oddiy matematik amallarni bajarishni va hatto SAT imtihoni savollariga javob berishni o'rgana olishi ko'rsatilgan.
Kontekstual o'rganish modelga qaror qabul qilish uchun doimiy ravishda yangi ma'lumotlarni o'zlashtirish imkonini beradi va bu uning eskirib qolishining oldini oladi. Tasavvur qiling, sizda eski JavaScript dokumentatsiyasida o'qitilgan model bor. Kontekstual o'rganish bo'lmaganda, bu modeldan yangi JavaScript versiyasi haqidagi savollarga javob olish uchun uni qayta o'qitishingiz kerak bo'lardi. Kontekstual o'rganish yordamida esa siz yangi JavaScript o'zgarishlarini modelning kontekstiga kiritishingiz mumkin, bu esa modelga o'zining ma'lumotlarining so'nggi sanasidan keyingi so'rovlarga ham javob berish imkonini beradi. Bu kontekstual o'rganishni uzluksiz o'rganishning (continual learning) bir shakliga aylantiradi.
Promptda keltirilgan har bir misol shot deb ataladi. Modelni promptdagi misollardan o'rganishga o'rgatish kam misolli o'rganish (few-shot learning) deb ham yuritiladi. Beshta misol bo'lsa, bu 5 misolli o'rganish bo'ladi. Hech qanday misol keltirilmaganda esa, bu nol misolli o'rganish (zero-shot learning) deyiladi.
Aynan qancha misol kerakligi model va ilovaga bog'liq. Ilovalaringiz uchun optimal misollar sonini aniqlash uchun tajriba qilib ko'rishingiz kerak bo'ladi. Umuman olganda, modelga qancha ko'p misol ko'rsatsangiz, u shuncha yaxshi o'rganadi. Misollar soni modelning maksimal kontekst uzunligi bilan cheklangan. Misollar qancha ko'p bo'lsa, promptingiz shuncha uzun bo'ladi va bu inference xarajatini oshiradi.
GPT-3 uchun kam misolli o'rganish nol misolli o'rganishga qaraganda sezilarli yaxshilanishni ko'rsatgan. Biroq, Microsoft'ning 2023-yilgi tahlilidagi amaliy vaziyatlarda, GPT-4 va bir nechta boshqa modellar uchun kam misolli o'rganish nol misolli o'rganishga nisbatan faqat cheklangan darajada yaxshilanishga olib kelgan. Bu natija shuni ko'rsatadiki, modellar kuchaygani sari, ular ko'rsatmalarni tushunish va ularga amal qilishda yaxshilanib boradi, bu esa kamroq misollar bilan ham yuqori samaradorlikka erishishga olib keladi. Ammo, tadqiqot kam misolli yondashuvning sohaga xos amaliy vaziyatlardagi ta'sirini yetarlicha baholamagan bo'lishi mumkin. Masalan, agar model o'zining o'qitish ma'lumotlarida Ibis dataframe API'siga oid ko'p misollarni ko'rmagan bo'lsa, promptga Ibis misollarini kiritish baribir katta farq yaratishi mumkin.
Atamalardagi noaniqlik: Prompt va Kontekst
Ba'zan, prompt va kontekst atamalari bir-birining o'rnida ishlatiladi.
GPT-3haqidagi maqolada (Brown va boshq., 2020), "kontekst" atamasi modelga kiritiladigan butun ma'lumotni anglatish uchun ishlatilgan. Bu ma'noda, kontekst va prompt mutlaqo bir xil narsadir.Biroq, mening Discord'imdagi uzoq bir muhokamada, ba'zilar kontekst promptning bir qismi ekanligini ta'kidlashdi. Unga ko'ra, kontekst — bu modelga promptda so'ralgan vazifani bajarishi uchun kerak bo'ladigan ma'lumotdir. Bu ma'noda, kontekst — bu kontekstual axborotdir.
Vaziyatni yanada chigallashtirib, Google'ning
PALM 2dokumentatsiyasida kontekst "modelning butun suhbat davomida qanday javob berishini shakllantiradigan tavsif. Masalan, siz kontekstdan foydalanib model ishlatishi mumkin bo'lgan yoki mumkin bo'lmagan so'zlarni, e'tibor qaratishi yoki chetlab o'tishi kerak bo'lgan mavzularni, yoki javob formati va uslubini belgilashingiz mumkin" deb ta'riflanadi. Bu esa kontekstni vazifa tavsifi bilan bir xil qilib qo'yadi.Ushbu kitobda men prompt deganda modelga kiritiladigan butun ma'lumotni, kontekst deganda esa modelga berilgan vazifani bajarishi uchun taqdim etilgan ma'lumotni nazarda tutaman.
Bugungi kunda kontekstual o'rganish odatiy holdek qabul qilinadi. Fundamental model ulkan hajmdagi ma'lumotlardan o'rganadi va ko'p narsalarni qila olishi kerak. Biroq, GPT-3'dan oldin, ML modellar faqat o'zlari o'qitilgan vazifalarnigina bajara olar edi, shu sababli kontekstual o'rganish sehrgarlikdek tuyulgan. Ko'plab aqlli insonlar kontekstual o'rganish nima uchun va qanday ishlashi haqida uzoq vaqt bosh qotirishgan (Stanford SI Laboratoriyasining “Kontekstual o'rganish qanday ishlaydi?” (“How Does In-context Learning Work?”) maqolasiga qarang). ML freymvorki Keras'ning yaratuvchisi François Chollet fundamental modelni ko'plab turli dasturlardan iborat kutubxonaga qiyoslagan. Masalan, unda hayku yoza oladigan bir dastur va limerik yoza oladigan boshqa bir dastur bo'lishi mumkin. Har bir dasturni ma'lum bir promptlar yordamida faollashtirish mumkin. Bu nuqtai nazardan qaraganda, prompt muhandisligi — bu siz xohlagan dasturni faollashtira oladigan to'g'ri promptni topish jarayonidir.
Tizim prompti va Foydalanuvchi prompti
Ko'pgina model API'lari sizga promptni tizim prompti va foydalanuvchi promptiga ajratish imkoniyatini beradi. Tizim promptini vazifa tavsifi, foydalanuvchi promptini esa vazifaning o'zi deb hisoblash mumkin. Keling, buning qanday ko'rinishda ekanligini bir misol orqali ko'rib chiqamiz.
Tasavvur qiling, siz xaridorlarga uy-joy haqidagi ma'lumotnomalarni tushunishga yordam beradigan chatbot yaratmoqchisiz. Foydalanuvchi ma'lumotnomani yuklab, "Tomning yoshi nechada?" yoki "Bu uy-joyning qanday g'ayrioddiy jihatlari bor?" kabi savollar berishi mumkin. Siz bu chatbotning tajribali rieltor rolini o'ynashini xohlaysiz. Siz bu rol o'ynash ko'rsatmasini tizim promptiga, foydalanuvchi savoli va yuklangan ma'lumotnomani esa foydalanuvchi promptiga joylashtirishingiz mumkin.
Deyarli barcha generativ SI ilovalari, jumladan ChatGPT ham, tizim promptlariga ega. Odatda, ilova ishlab chiquvchilari tomonidan berilgan ko'rsatmalar tizim promptiga, foydalanuvchilar tomonidan berilgan ko'rsatmalar esa foydalanuvchi promptiga joylashtiriladi. Lekin siz ijodiy yondashib, ko'rsatmalarning o'rnini almashtirishingiz ham mumkin, masalan, hamma narsani tizim promptiga yoki foydalanuvchi promptiga joylashtirib. Qaysi biri eng yaxshi ishlashini bilish uchun promptlaringizni turli usullarda strukturalash bilan tajriba qilib ko'rishingiz mumkin.
Tizim prompti va foydalanuvchi prompti berilganda, model ularni bitta yaxlit promptga birlashtiradi va bu odatda ma'lum bir shablon asosida amalga oshiriladi. Misol tariqasida, Llama 2 chat modeli uchun shablon quyidagicha:
Agar tizim prompti "Quyidagi matnni fransuz tiliga tarjima qiling" va foydalanuvchi prompti "Qalaysiz?" bo'lsa, Llama 2 modeliga kiritiladigan yakuniy prompt quyidagicha bo'lishi kerak:
Ogohlantirish
Ushbu bo'limda muhokama qilingan modelning chat shabloni, ilova ishlab chiquvchilari tomonidan o'z promptlarini aniq ma'lumotlar bilan to'ldirish (populate yoki hydrate qilish) uchun ishlatiladigan prompt shablonidan farq qiladi. Modelning chat shabloni model ishlab chiquvchilari tomonidan belgilanadi va odatda modelning dokumentatsiyasida topilishi mumkin. Prompt shablonini esa istalgan ilova ishlab chiquvchisi belgilashi mumkin.
Turli modellar turli xil chat shablonlaridan foydalanadi. Bir xil model ishlab chiquvchisi model versiyalari o'rtasida shablonni o'zgartirishi mumkin. Masalan, Llama 3 chat modeli uchun Meta shablonni quyidagicha o'zgartirdi:
<| va |> orasidagi har bir matn qismi, masalan, <|begin_of_text|> va <|start_header_id|>, model tomonidan bitta token sifatida qabul qilinadi.
Bexosdan noto'g'ri shablondan foydalanish samaradorlikda kutilmagan va tushunarsiz muammolarga olib kelishi mumkin. Shablonni ishlatishdagi kichik xatolar, masalan, ortiqcha yangi qator qo'shish, modelning xatti-harakatlarini sezilarli darajada o'zgartirib yuborishi ham mumkin.2
Maslahat
Shablonlarning mos kelmasligi bilan bog'liq muammolarning oldini olish uchun quyidagi bir nechta yaxshi amaliyotlarga rioya qilish kerak:
- Fundamental model uchun kiritiladigan ma'lumotlarni tuzayotganda, ularning modelning chat shabloniga to'liq mos kelishiga ishonch hosil qiling.
- Agar promptlarni tuzish uchun uchinchi tomon vositasidan foydalansangiz, ushbu vosita to'g'ri chat shablonidan foydalanayotganini tekshiring. Shablonlardagi xatolar, afsuski, juda keng tarqalgan.3 Bu xatolarni payqash qiyin, chunki ular yashirin nosozliklarga olib keladi — shablon noto'g'ri bo'lsa ham, model baribir qandaydir mantiqli javob qaytaradi.4
- Modelga so'rov yuborishdan oldin, yakuniy promptni ekranga chiqarib, uning kutilgan shablonga mos kelishini qayta tekshirib ko'ring.
Ko'pgina model ishlab chiquvchilari puxta ishlab chiqilgan tizim promptlari samaradorlikni oshirishi mumkinligini ta'kidlaydilar. Masalan, Anthropic dokumentatsiyasida shunday deyilgan: "Claude'ga tizim prompti orqali ma'lum bir rol yoki personaj yuklanganda, u butun suhbat davomida o'sha obrazni samaraliroq saqlab qoladi, o'z rolida qolgan holda tabiiyroq va ijodiyroq javoblar namoyon etadi."
Ammo nima uchun tizim promptlari foydalanuvchi promptlariga qaraganda samaradorlikni oshiradi? Aslida, tizim prompti va foydalanuvchi prompti modelga uzatilishidan oldin bitta yakuniy promptga birlashtiriladi. Model nuqtai nazaridan, tizim promptlari va foydalanuvchi promptlari bir xil tarzda qayta ishlanadi. Tizim prompti ta'minlashi mumkin bo'lgan har qanday samaradorlikning oshishi, ehtimol, quyidagi omillarning biri yoki har ikkisi bilan bog'liq:
- Tizim prompti yakuniy promptda birinchi bo'lib keladi va model shunchaki birinchi kelgan ko'rsatmalarni qayta ishlashga ustaroq bo'lishi mumkin.
- Model, OpenAI'ning “Ko'rsatmalar Ierarxiyasi: Imtiyozli Ko'rsatmalarga Ustunlik Berishga LLM'larni O'qitish” (“The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions”) (Wallace va boshq., 2024) nomli maqolasida aytilganidek, tizim promptiga ko'proq e'tibor qaratishga yakuniy o'qitilgan (post-training) bo'lishi mumkin. Modelni tizim promptlariga ustunlik berishga o'qitish, shuningdek, ushbu bobning keyingi qismida muhokama qilinganidek, prompt hujumlarini yumshatishga ham yordam beradi.
Kontekst hajmi va undan foydalanish samaradorligi
Promptga qancha ma'lumot sig'dirish mumkinligi modelning kontekst hajmi chegarasiga bog'liq. So'nggi yillarda modellarning maksimal kontekst hajmi shiddat bilan o'sib bormoqda. GPT'ning dastlabki uch avlodi mos ravishda 1K (1000 token), 2K va 4K tokenlik kontekst hajmiga ega edi. Bu hajm talabaning inshosi uchun bazo'r yetsa-da, aksariyat yuridik hujjatlar yoki ilmiy maqolalar uchun juda kichiklik qiladi.
Ko'p o'tmay, kontekst hajmini kengaytirish model ishlab chiquvchilari va amaliyotchi mutaxassislar o'rtasidagi poygaga aylanib ketdi. 5-2-rasmda kontekst hajmi chegarasi qanchalik tez kengayib borayotgani ko'rsatilgan. Besh yil ichida u GPT-2'ning 1K tokenlik kontekst hajmidan Gemini-1.5 Pro'ning 2M (2 million) tokenlik kontekst hajmiga qadar 2000 barobar o'sdi. 100K tokenlik kontekstga o'rtacha hajmdagi kitob sig'ishi mumkin. Ma'lumot uchun, ushbu kitob taxminan 120 000 ta so'zdan yoki 160 000 ta tokendan iborat. 2M tokenlik kontekstga esa taxminan 2000 ta Vikipediya sahifasi va PyTorch kabi ancha murakkab kod bazasi sig'ishi mumkin.
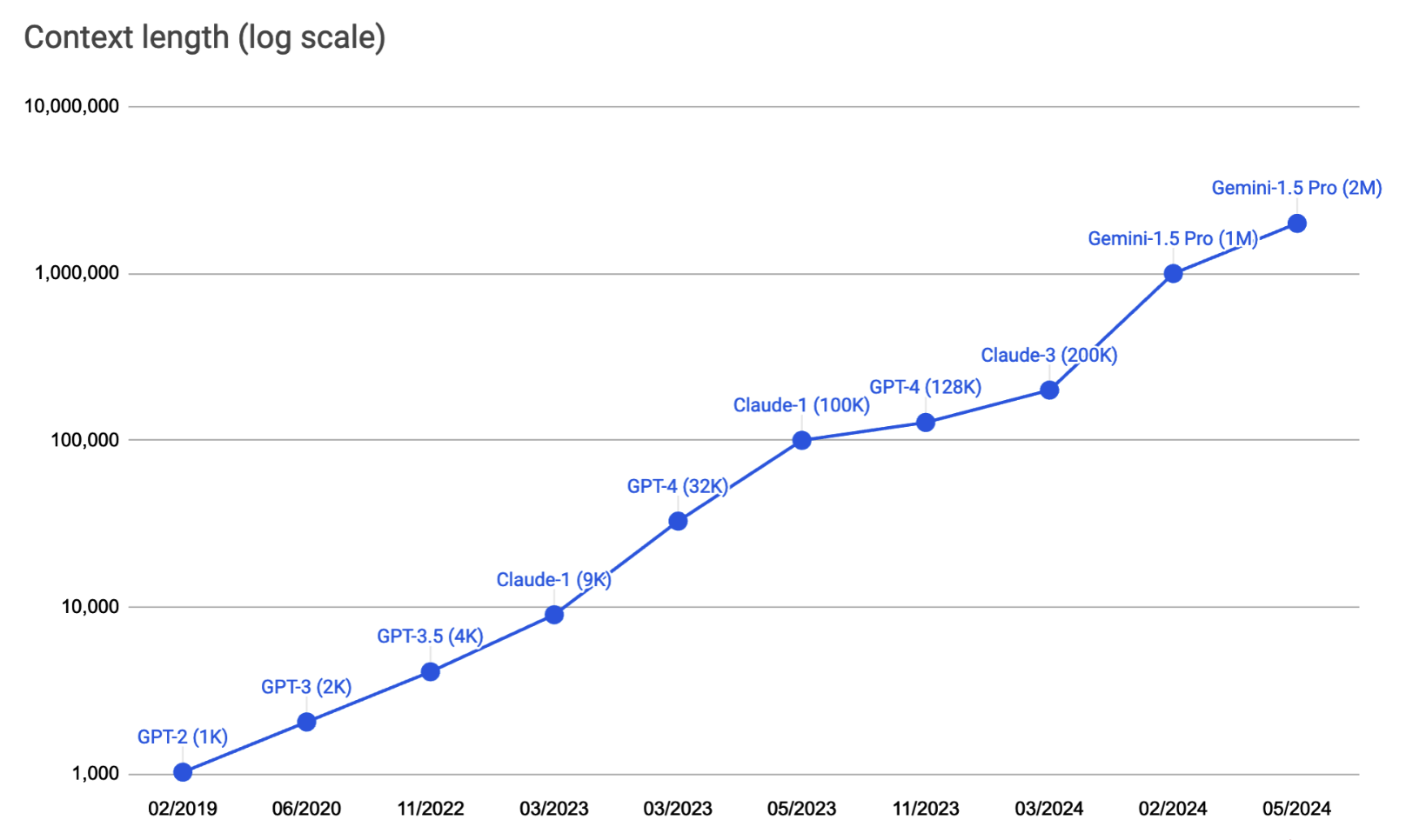 Kontekst hajmi 2019-yil fevralidan 2024-yil mayigacha 1K dan 2M gacha kengaydi.5
Kontekst hajmi 2019-yil fevralidan 2024-yil mayigacha 1K dan 2M gacha kengaydi.5
Kontekstdan foydalanish samaradorligi: "Somon orasidan igna qidirish" sinovi
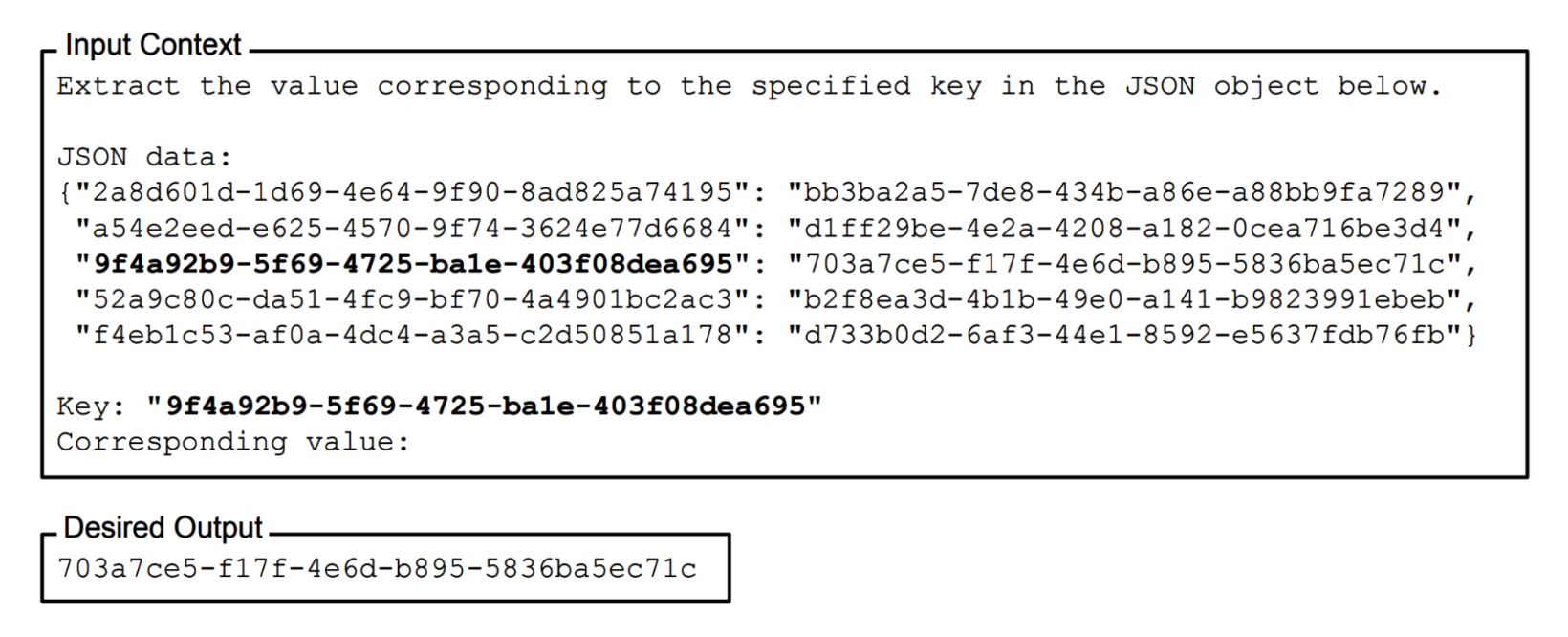
Promptning barcha qismlari bir xil ahamiyatga ega emas. Tadqiqotlar shuni ko'rsatdiki, model promptning o'rtasiga qaraganda uning boshi va oxirida berilgan ko'rsatmalarni ancha yaxshi tushunadi (Liu va boshq., 2023). Promptning turli qismlari samaradorligini baholash usullaridan biri — bu "Somon orasidan igna qidirish" (Needle in a Haystack yoki NIAH) nomi bilan tanilgan keng tarqalgan sinovdan foydalanishdir. Uning g'oyasi promptning (go'yoki "somon uyumi") turli joylariga tasodifiy bir ma'lumot qismini ("igna") joylashtirish va modeldan uni topishni so'rashdan iborat. 5-3-rasmda Liu va boshqalarning maqolasida qo'llanilgan ma'lumot qismiga misol keltirilgan.
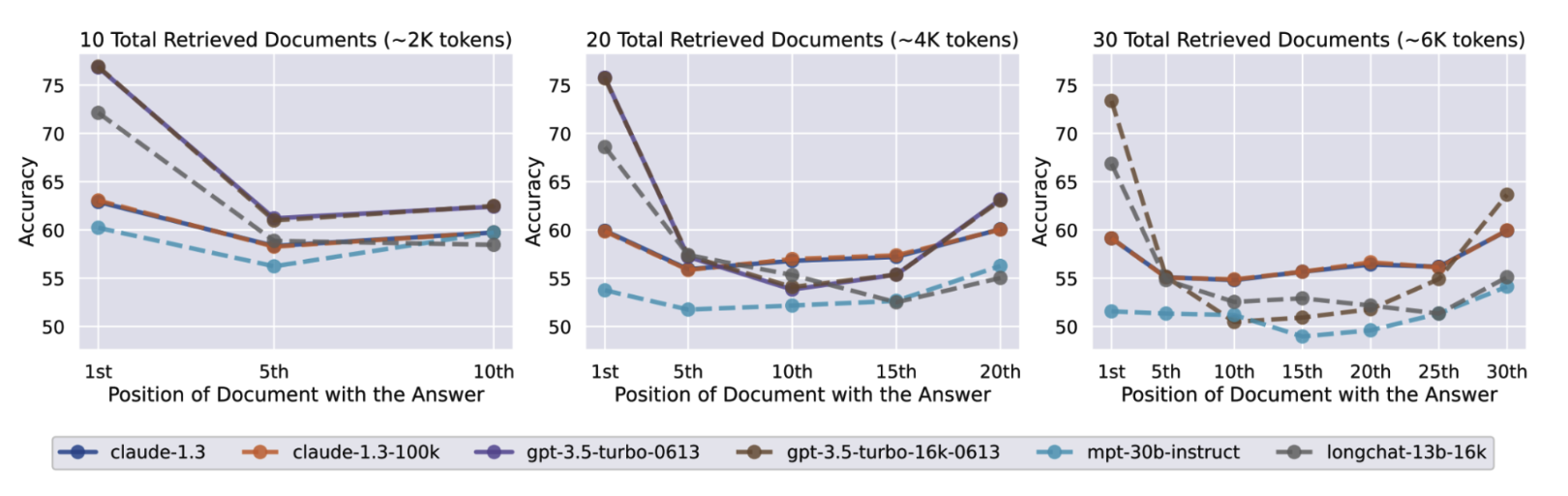
5-4-rasmda ushbu maqoladan olingan natija ko'rsatilgan. Sinovdan o'tkazilgan barcha modellar ma'lumotni promptning o'rtasiga qaraganda uning boshi va oxiriga yaqinroq bo'lganda ancha yaxshi topa olgan.
Maqolada tasodifiy yaratilgan belgilar ketma-ketligidan foydalanilgan, lekin siz haqiqiy savollar va haqiqiy javoblardan ham foydalanishingiz mumkin. Masalan, agar sizda shifokor qabulining uzun transkripti bo'lsa, modeldan uchrashuv davomida aytib o'tilgan ma'lumotlarni, masalan, bemor qabul qilayotgan dori yoki uning qon guruhini qaytarishni so'rashingiz mumkin.6 Sinov uchun ishlatadigan ma'lumotlaringiz maxfiy ekanligiga ishonch hosil qiling, bu uning modelning o'qitish ma'lumotlariga kirib qolish ehtimolining oldini oladi. Agar shunday bo'lib qolsa, model savolga javob berish uchun kontekstga emas, balki o'zining ichki bilimiga tayanishi mumkin.
RULER (Hsieh va boshq., 2024) kabi shunga o'xshash sinovlar, shuningdek, modelning uzun promptlarni qayta ishlashda qanchalik usta ekanligini baholash uchun ham ishlatilishi mumkin. Agar kontekst uzaygani sari modelning samaradorligi tobora yomonlashib borsa, unda siz promptlaringizni qisqartirish yo'lini topishingiz kerak bo'ladi.
Tizim prompti, foydalanuvchi prompti, misollar va kontekst — bular promptning asosiy tarkibiy qismlaridir. Endi biz prompt nima ekanligi va promptlash nima uchun ishlashini muhokama qilib bo'lganimizdan so'ng, keling, samarali promptlar yozishning eng yaxshi amaliyotlarini ko'rib chiqamiz.
Izohlar
-
2023-yil oxirida Stanford o'zining
HELM Litebenchmarkidan chidamlilik metrikasini olib tashladi. ↩ -
Odatda, kutilgan chat shablonidan chetga chiqishlar modelning ishlash samaradorligi yomonlashishiga olib keladi. Biroq, kamdan-kam hollarda bo'lsa-da, bu holat modelning yaxshiroq ishlashiga ham sabab bo'lishi mumkin, bu haqda Reddit'dagi bir muhokamada aytib o'tilgan. ↩
-
Agar GitHub va Reddit'da yetarlicha vaqt o'tkazsangiz, chat shablonlarining mos kelmasligi bilan bog'liq ko'plab muammolarga duch kelasiz, masalan, mana bu holat kabi. Bir safar finetuning bilan bog'liq muammoni tuzatishga bir kunimni sarflaganman va yakunda anglab yetgandimki, bunga men ishlatgan kutubxona modelning yangi versiyasi uchun chat shablonini yangilamagani sabab bo'lgan ekan. ↩
-
Foydalanuvchilar shablon bilan bog'liq xatolarga yo'l qo'ymasligi uchun ko'plab model API'lari shunday loyihalashtirilganki, foydalanuvchilarning o'zlari maxsus shablon tokenlarini yozishiga hojat qolmaydi. ↩
-
Garchi Google 2024-yil fevral oyida 10 million tokenlik kontekst uzunligi bilan tajribalar o'tkazayotganini e'lon qilgan bo'lsa-da, bu raqam hali ommaga taqdim etilmagani uchun uni jadvalga kiritmadim. ↩
-
Shreya Shankar shifokor qabuliga borish uchun o'tkazgan amaliy NIAH sinovi haqida ajoyib maqola yozgan (2024). ↩