SI muhandislik steki (texnologiyalar to'plami)
SI muhandisligining jadal o'sishi, shuningdek, aql bovar qilmas darajada shov-shuv va FOMO (imkoniyatni qo'ldan boy berish qo'rquvi)ni keltirib chiqardi. Har kuni taqdim etilayotgan yangi vositalar, texnikalar, modellar va ilovalarning soni odamni shunchaki shoshirib qo'yishi mumkin. Poydevori mustahkam bo'lmagan, doimiy o'zgarib turadigan bu "ko'chma qumlar" ortidan quvish o'rniga, keling, SI muhandisligining fundamental qurilish bloklarini ko'rib chiqamiz.
SI muhandisligini tushunish uchun uning ML muhandisligidan kelib chiqqanini anglash muhimdir. Biror kompaniya fundamental modellar bilan tajriba o'tkazishni boshlaganda, bu sa'y-harakatlarga uning mavjud ML jamoasi boshchilik qilishi tabiiydir. Ba'zi kompaniyalar SI muhandisligiga ML muhandisligi bilan bir xil munosabatda bo'lishadi (1-12-rasm).
Ba'zi kompaniyalarda esa SI muhandisligi uchun alohida ish e'lonlari mavjud (1-13-rasm).
Tashkilotlar SI muhandislari va ML muhandislarini qanday joylashtirishidan qat'i nazar, ularning rollari sezilarli darajada bir-biriga mos keladi. Mavjud ML muhandislari o'zlarining ish imkoniyatlarini kengaytirish uchun SI muhandisligini o'z ko'nikmalari ro'yxatiga qo'shishlari mumkin. Shu bilan birga, oldindan ML tajribasiga ega bo'lmagan SI muhandislari ham bor.
SI muhandisligini va uning an'anaviy ML muhandisligidan qanday farq qilishini juda yaxshi tushunib olish uchun, keyingi bo'limda SI dasturlarini yaratish jarayonining turli qatlamlari tahlil qilinadi va har bir qatlamning SI muhandisligi va ML muhandisligida qanday rol o'ynashiga nazar tashlanadi.
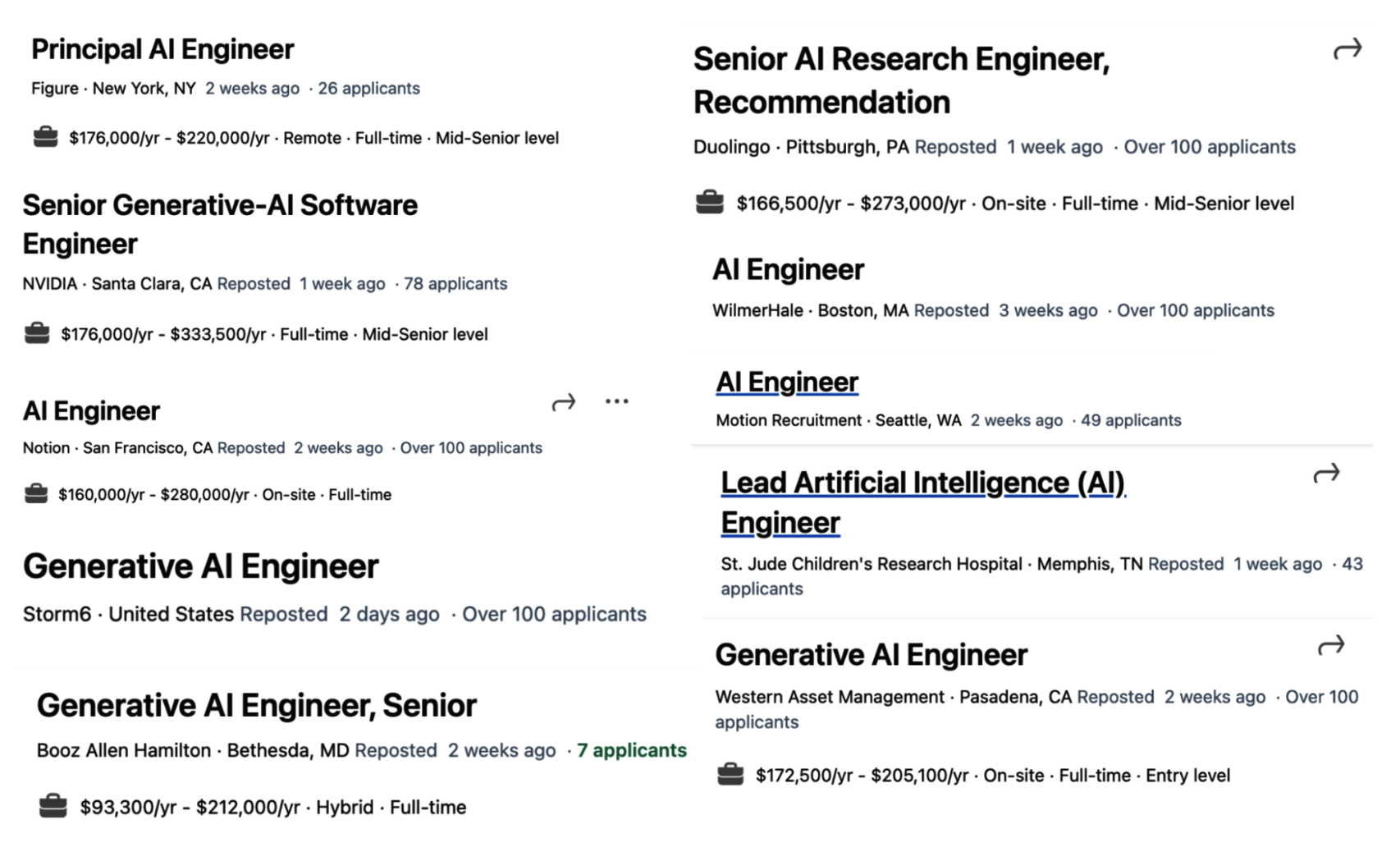
SI stekining uch qatlami
Har qanday SI dasturi stekida uchta qatlam mavjud: dasturni ishlab chiqish, modelni ishlab chiqish va infratuzilma. SI dasturini ishlab chiqayotganda, siz odatda yuqori qatlamdan boshlab, zaruratga qarab pastga tushib borasiz:
1. Dasturni ishlab chiqish
Modellar tayyor holatda bo'lgani uchun, har kim ulardan dasturlar ishlab chiqishda foydalanishi mumkin. Bu so'nggi ikki yil ichida eng ko'p kuzatilgan harakat va hali ham jadal rivojlanayotgan qatlamdir. Dasturni ishlab chiqish modelni yaxshi promptlar va kerakli kontekst bilan ta'minlashni o'z ichiga oladi. Bu qatlam puxta baholashni talab qiladi. Yaxshi dasturlar, shuningdek, yaxshi interfeyslarni ham talab qiladi.
2. Modelni ishlab chiqish
Bu qatlam modellarni ishlab chiqish uchun vositalarni ta'minlaydi, jumladan, modellashtirish, o'qitish, finetuning qilish va inference optimizatsiyasi uchun freymvorklarni. Ma'lumotlar modelni ishlab chiqishning markazida bo'lgani uchun, bu qatlam ma'lumotlar to'plami muhandisligini (dataset engineering) ham o'z ichiga oladi. Modelni ishlab chiqish ham puxta baholashni talab qiladi.
3. Infratuzilma
Stekning eng quyi qismida infratuzilma joylashgan bo'lib, u modelga xizmat ko'rsatish (model serving), ma'lumotlar va hisoblash resurslarini boshqarish hamda monitoring uchun vositalarni o'z ichiga oladi.
Ushbu uch qatlamning tuzilishini va har birining qanday vazifalarni o'z ichiga olishini 1-14-rasmda ko'rib chiqamiz.
Fundamental modellar paydo bo'lishi bilan sohadagi manzara qanday o'zgarganini his qilish uchun, 2024-yil mart oyida men GitHub'dan kamida 500 yulduzchaga ega bo'lgan SI'ga oid barcha repozitoriylarni tahlil qilib chiqdim. GitHub'ning bugungi kundagi keng qamrovini hisobga olsak, bu ma'lumotlar ekotizimni tushunish uchun ishonchli ko'rsatkich bo'la oladi, deb ishonaman. Tahlilimga, shuningdek, dasturlar va modellar uchun repozitoriylarni ham kiritdim — ular mos ravishda dasturni ishlab chiqish va modelni ishlab chiqish qatlamlarining mahsulotidir. Natijada men jami 920 ta repozitoriy jamladim. 1-15-rasmda har bir toifadagi repozitoriylar sonining oylar kesimida qanday o'sib borgani ko'rsatilgan.
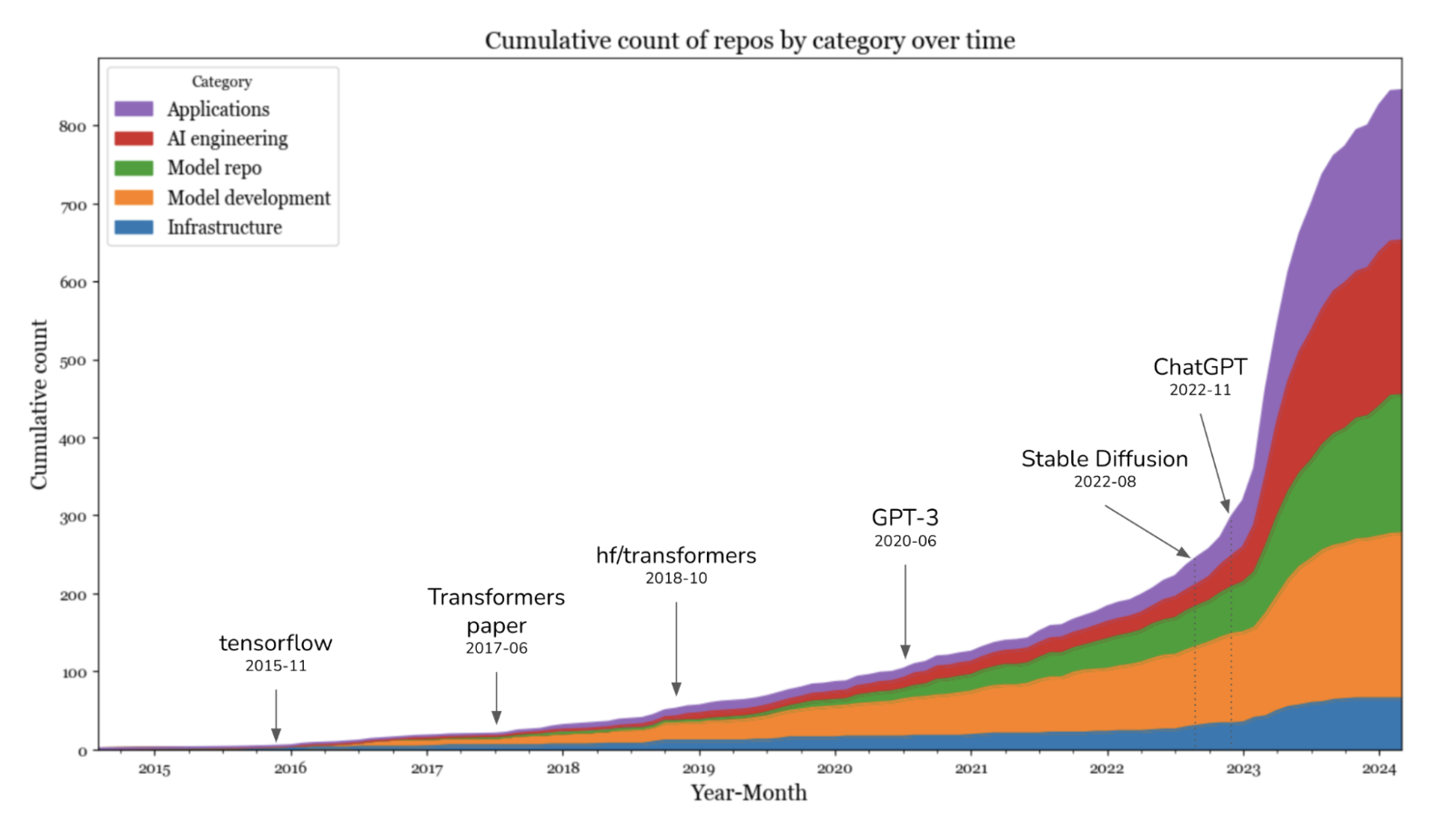
Ma'lumotlar shuni ko'rsatadiki, Stable Diffusion va ChatGPT taqdim etilganidan so'ng, 2023-yilda SI vositalari sonida keskin sakrash yuz bergan. 2023-yilda eng katta o'sish "dasturlar" va "dasturlarni ishlab chiqish" toifalarida kuzatildi. Infratuzilma qatlamida ham o'sish bo'ldi, biroq u boshqa qatlamlardagi o'sishdan ancha past edi. Bu kutilgan holat. Garchi modellar va dasturlar o'zgargan bo'lsa-da, asosiy infratuzilma ehtiyojlari — resurslarni boshqarish, xizmat ko'rsatish, monitoring va hokazolar — o'zgarishsiz qolmoqda.
O'zgarmas tamoyillar
Bu bizni keyingi muhim nuqtaga olib keladi. Fundamental modellar atrofidagi hayajon va ijodkorlik misli ko'rilmagan darajada bo'lsa-da, SI dasturlarini yaratishning ko'plab asosiy tamoyillari o'z kuchida qolmoqda. Korporativ ishlatilish senariylari uchun SI dasturlari avvalgidek biznes muammolarini hal qilishi kerak va shuning uchun biznes metrikalarini ML metrikalariga (va aksincha) bog'lash hali ham dolzarb. Siz avvalgidek tizimli eksperimentlar o'tkazishingiz kerak. Klassik ML muhandisligida siz turli giperparametrlar bilan tajriba o'tkazgan bo'lsangiz, fundamental modellar bilan turli modellar, promptlar, qidiruv algoritmlari, sampling o'zgaruvchilari va boshqalar bilan tajriba o'tkazasiz. (sampling o'zgaruvchilari 2-bobda muhokama qilinadi.) Biz hali ham modellarni tezroq va arzonroq ishlashiga intilamiz. Va hali ham teskari aloqa mexanizmini (feedback loop) yo'lga qo'yish muhim, toki amaliyotdagi ma'lumotlar yordamida dasturlarimizni doimiy takomillashtirib bora olamiz.
Bu shuni anglatadiki, ML muhandislari so'nggi o'n yil davomida to'plagan bilim va tajribalarning aksariyati bugun ham o'z qadrini yo'qotmagan. Bu jamoaviy tajriba har kimning SI dasturlarini yaratishni boshlashini osonlashtiradi. Biroq, ushbu mustahkam tamoyillar poydevori ustiga qurilgan SI muhandisligiga xos bo'lgan ko'plab yangiliklar ham mavjud va biz ularni ushbu kitobda chuqur o'rganamiz.
SI muhandisligi va ML muhandisligi farqlari
SI dasturlarini joriy etishning o'zgarmas tamoyillari mavjudligi kishiga dalda bersa-da, nimalar o'zgarganini tushunish ham muhimdir. Bu o'zlarining mavjud platformalarini yangi SI ishlatilish senariylariga moslashtirishni istagan jamoalar uchun va yangi bozorda raqobatbardosh bo'lib qolish uchun qaysi ko'nikmalarni o'rganishga qiziqqan dasturchilar uchun foydalidir.
Yuqori darajada qaraganda, bugungi kunda fundamental modellar yordamida dasturlar yaratish an'anaviy ML muhandisligidan uchta asosiy jihati bilan farq qiladi:
-
Model yaratishdan ko'ra modeldan foydalanish. Fundamental modellarsiz, siz o'z dasturlaringiz uchun o'z modelingizni o'qitishingiz kerak edi. SI muhandisligida esa kimdir siz uchun o'qitgan modeldan foydalanasiz. Bu shuni anglatadiki, SI muhandisligi modellashtirish va o'qitishga kamroq, modelni moslashtirishga esa ko'proq e'tibor qaratadi.
-
Resurs talabchanligi. SI muhandisligi an'anaviy ML muhandisligiga qaraganda kattaroq, ko'proq hisoblash resurslarini iste'mol qiladigan va yuqori kechikishga ega bo'lgan modellar bilan ishlaydi. Bu samarali o'qitish va inference optimizatsiyasi uchun bosimning kuchliroq ekanligini anglatadi. Hisoblash resurslarini ko'p talab qiladigan modellarning natijalaridan biri shuki, ko'plab kompaniyalar endi avvalgidan ko'ra ko'proq GPU'larga muhtoj va kattaroq hisoblash klasterlari bilan ishlaydi, bu esa GPU'lar va katta klasterlar bilan ishlashni biladigan muhandislarga talabning ortganini bildiradi.1
-
Natijalarning tabiati. SI muhandisligi erkin natijalar (open-ended outputs) yarata oladigan modellar bilan ishlaydi. Erkin natijalar modellarga ko'proq vazifalar uchun ishlatilish moslashuvchanligini beradi, lekin ularni baholashni ham qiyinlashtiradi. Bu esa baholashni SI muhandisligida ancha kattaroq muammoga aylantiradi.
Qisqacha aytganda, SI muhandisligi ML muhandisligidan shunisi bilan farq qiladiki, u e'tiborni modelni noldan yaratishga emas, balki mavjud modellarni moslashtirish va baholashga qaratadi. Men ushbu bobda modelni moslashtirishni bir necha bor tilga oldim, shuning uchun keyingi bo'limga o'tishdan oldin, bu tushunchani bir xil anglayotganimizga ishonch hosil qilmoqchiman. Umuman olganda, modelni moslashtirish texnikalarini model og'irliklarini (weights) yangilashni talab qilishi yoki qilmasligiga qarab ikki toifaga bo'lish mumkin.
Modelni moslashtirish yondashuvlari
-
Promptga asoslangan texnikalar, jumladan, prompt muhandisligi, model og'irliklarini yangilamasdan modelni moslashtiradi. Siz modelni o'zini o'zgartirish o'rniga, unga ko'rsatmalar va kontekst berish orqali moslashtirasiz. Prompt muhandisligini boshlash osonroq va u kamroq ma'lumot talab qiladi. Ko'plab muvaffaqiyatli dasturlar faqat prompt muhandisligi yordamida yaratilgan. Uning qo'llash osonligi sizga ko'proq modellar bilan tajriba o'tkazish imkonini beradi, bu esa dasturlaringiz uchun kutilmaganda yaxshi ishlaydigan modelni topish imkoniyatingizni oshiradi. Biroq, prompt muhandisligi murakkab vazifalar yoki qat'iy samaradorlik talablariga ega dasturlar uchun yetarli bo'lmasligi mumkin.
-
Finetuning qilish, aksincha, model og'irliklarini yangilashni talab qiladi. Siz modelni uning o'ziga o'zgartirishlar kiritish orqali moslashtirasiz. Umuman olganda, finetuning qilish texnikalari murakkabroq va ko'proq ma'lumot talab qiladi, lekin ular modelingizning sifati, kechikishi va xarajatini sezilarli darajada yaxshilashi mumkin. Ko'p narsalarni model og'irliklarini o'zgartirmasdan amalga oshirib bo'lmaydi, masalan, modelni o'qitish paytida duch kelmagan yangi vazifaga moslashtirish.
Endi, keling, dasturni ishlab chiqish va modelni ishlab chiqish qatlamlariga chuqurroq nazar tashlab, har biri SI muhandisligi bilan qanday o'zgarganini ko'rib chiqamiz. Biz mavjud ML muhandislari ko'proq tanish bo'lgan narsadan boshlaymiz. Ushbu bo'lim SI dasturini ishlab chiqishda ishtirok etadigan turli jarayonlarning umumiy sharhini beradi. Bu jarayonlar qanday ishlashi esa ushbu kitob davomida muhokama qilinadi.
Modelni ishlab chiqish
Modelni ishlab chiqish — bu an'anaviy ML muhandisligi bilan eng ko'p bog'lanadigan qatlamdir. U uchta asosiy mas'uliyatni o'z ichiga oladi: modellashtirish va o'qitish, ma'lumotlar to'plami muhandisligi hamda inference optimizatsiyasi. Baholash ham talab etiladi, lekin ko'pchilik unga birinchi bo'lib dasturni ishlab chiqish qatlamida duch kelgani uchun, men baholashni keyingi bo'limda muhokama qilaman.
Modellashtirish va o'qitish
Modellashtirish va o'qitish model arxitekturasini ishlab chiqish, uni o'qitish va finetuning qilish jarayonini anglatadi. Bu toifadagi vositalarga misol qilib Google'ning TensorFlow, Hugging Face'ning Transformers va Meta'ning PyTorch freymvorklarini keltirish mumkin.
ML modellarini ishlab chiqish bunga alohida ixtisoslashgan ML bilimlarini talab qiladi. Bu turli xil ML algoritmlarini (masalan, klasterlash, logistik regressiya, qaror daraxtlari va kollaborativ filtrlash) va neyron to'r arxitekturalarini (masalan, to'g'ridan-to'g'ri tarqaluvchi (feedforward), qaytalanuvchi (recurrent), konvolyutsion (convolutional) va transformer) bilishni talab qiladi. Shuningdek, u modelning qanday o'rganishini, jumladan, gradient tushishi (gradient descent), yo'qotish funksiyasi (loss function), regulyarizatsiya (regularization) kabi tushunchalarni anglashni ham talab qiladi.
Fundamental modellarning mavjudligi bilan, ML bilimlari endi SI dasturlarini yaratish uchun majburiy shart emas. Men gradient tushishi haqida o'rganishga umuman qiziqmaydigan ko'plab ajoyib va muvaffaqiyatli SI dasturlari yaratuvchilarini uchratdim. Biroq, ML bilimlari hali ham o'ta qimmatlidir, chunki u siz foydalanishingiz mumkin bo'lgan vositalar to'plamini kengaytiradi va model kutilganidek ishlamaganda muammolarni bartaraf etishga yordam beradi.
O'qitish, dastlabki o'qitish, finetuning qilish va yakuniy o'qitish o'rtasidagi farqlar
O'qitish har doim model og'irliklarini (weights) o'zgartirishni o'z ichiga oladi, lekin model og'irliklariga kiritilgan har qanday o'zgartirish ham o'qitish degani emas. Masalan, kvantlash (quantization) — model og'irliklarining aniqligini pasaytirish jarayoni — texnik jihatdan modelning og'irlik qiymatlarini o'zgartirsa-da, o'qitish deb hisoblanmaydi.
"O'qitish" atamasi ko'pincha dastlabki o'qitish (pre-training), finetuning qilish va yakuniy o'qitish (post-training) o'rnida ishlatilishi mumkin, bular o'qitishning turli bosqichlarini anglatadi:
Dastlabki o'qitish (Pre-training): Dastlabki o'qitish modelni noldan o'qitishni anglatadi — bunda model og'irliklari tasodifiy qiymatlar bilan boshlanadi. LLM'lar uchun dastlabki o'qitish ko'pincha modelni matnni davom ettirishga o'rgatishni o'z ichiga oladi. Barcha o'qitish bosqichlari ichida dastlabki o'qitish, shubhasiz, eng ko'p resurs talab qiladigan jarayondir.
InstructGPTmodeli uchun dastlabki o'qitish umumiy hisoblash va ma'lumotlar resurslarining 98 foizigacha qismini egallaydi. Dastlabki o'qitish, shuningdek, uzoq vaqt talab etadi. Bu jarayondagi kichik bir xato jiddiy moliyaviy yo'qotishlarga olib kelishi va loyihani ancha orqaga surib yuborishi mumkin. Resurs talabchanligi tufayli, bu jarayon sanoqlilar shug'ullanadigan san'atga aylanib qolgan. Biroq, katta modellarni dastlabki o'qitish bo'yicha tajribaga ega bo'lgan mutaxassislarga talab juda yuqori.2Finetuning qilish: Finetuning qilish oldindan o'qitilgan modelni o'qitishda davom etishni anglatadi — bunda model og'irliklari avvalgi o'qitish jarayonidan olinadi. Model dastlabki o'qitishdan ma'lum bilimlarga ega bo'lgani uchun, finetuning qilish odatda dastlabki o'qitishga qaraganda kamroq resurs (masalan, ma'lumotlar va hisoblash quvvati) talab qiladi.
Yakuniy (Post-training): Ko'pchilik yakuniy o'qitish deganda modelni dastlabki o'qitish bosqichidan keyin o'qitish jarayonini tushunadi. Konseptual jihatdan, yakuniy o'qitish va finetuning qilish bir xil narsa va ularni bir-birining o'rnida ishlatsa bo'ladi. Biroq, ba'zida odamlar ularni turli maqsadlarni bildirish uchun farqli ishlatishlari mumkin. Agar bu jarayon model yaratuvchilari tomonidan amalga oshirilsa, odatda yakuniy o'qitish deyiladi. Masalan, OpenAI modelni ommaga taqdim etishdan oldin uning ko'rsatmalarga yaxshiroq amal qilishini ta'minlash uchun uni yakuniy o'qitishdan o'tkazishi mumkin. Agar bu jarayon dastur yaratuvchilari tomonidan amalga oshirilsa, bu finetuning qilish deyiladi. Masalan, siz OpenAI modelini (u o'zi ham yakuniy o'qitishdan o'tgan bo'lishi mumkin) o'z ehtiyojlaringizga moslashtirish uchun finetuning qilishingiz mumkin.
Dastlabki o'qitish va yakuniy o'qitish bir spektrni tashkil etadi.3 Ularning jarayonlari va vositalari juda o'xshash. Ularning farqlari 2 va 7-boblarda batafsilroq o'rganiladi.
Ba'zi odamlar "o'qitish" atamasini prompt muhandisligiga nisbatan ishlatishadi, bu esa noto'g'ri. Men "Business Insider"da bir maqolani o'qidim, unda muallif
ChatGPT'ni o'zining yoshligini taqlid qilishga "o'rgatganini" aytgan. U buni o'zining bolalik kundaliklariniChatGPT'ga kiritish orqali amalga oshirgan. So'zlashuv tilida, muallifning "o'qitish" so'zini ishlatishi to'g'ri, chunki u modelga biror narsa qilishni o'rgatmoqda. Ammo texnik jihatdan, agar siz modelga nima qilish kerakligini unga kiritiladigan kontekst orqali o'rgatsangiz, siz prompt muhandisligi bilan shug'ullanayotgan bo'lasiz. Xuddi shunday, men odamlarning aslida prompt muhandisligi bilan shug'ullanayotgan bo'lsalar-da, "finetuning qilish" atamasini ishlatganini ham ko'rganman.
Ma'lumotlar to'plami muhandisligi
Ma'lumotlar to'plami muhandisligi (Dataset engineering) SI modellarini o'qitish va moslashtirish uchun zarur bo'lgan ma'lumotlarni saralash, generatsiya qilish va belgilashni anglatadi.
An'anaviy ML muhandisligida aksariyat ishlatilish senariylari cheklangan natijali (close-ended) bo'ladi — ya'ni, modelning natijasi faqat oldindan belgilangan qiymatlar orasida bo'lishi mumkin. Masalan, faqat ikkita ehtimoliy natijaga — “spam” va “spam emas”ga — ega bo'lgan spam tasnifi cheklangan natijali vazifadir. Fundamental modellar esa, aksincha, erkin turdagi (open-ended) natijalar beradi. Erkin turdagi so'rovlarni belgilash cheklangan natijali so'rovlarni belgilashdan ancha qiyinroq — insho yozishdan ko'ra elektron pochtaning spam ekanligini aniqlash osonroq. Shu sababli, ma'lumotlarni belgilash — SI muhandisligi oldida turgan jiddiy sinovlardan biridir.
Yana bir farq shundaki, an'anaviy ML muhandisligi ko'proq jadvalli ma'lumotlar bilan ishlasa, fundamental modellar strukturalashmagan ma'lumotlar bilan ishlaydi. SI muhandisligida ma'lumotlar bilan ishlash ko'proq takrorlanishlarni olib tashlash (deduplication), tokenizatsiya, kontekstni qidirib topish (context retrieval) va sifat nazorati, jumladan, maxfiy ma'lumotlar va toksik ma'lumotlarni olib tashlash bilan bog'liq. Ma'lumotlar to'plami muhandisligi 8-bobning asosiy mavzusidir.
Ko'pchilikning ta'kidlashicha, modellar endi shunchaki oddiy xomashyoga (commodities) aylanib ulgurdi. Shu bois, raqobat ustunligini aynan ma'lumotlar belgilab beradi va bu ma'lumotlar to'plami muhandisligini har qachongidan ham muhimroq qiladi. Sizga qancha ma'lumot kerakligi siz qo'llaydigan moslashtirish texnikasiga bog'liq. Modelni noldan o'qitish odatda finetuning qilishdan ko'ra ko'proq ma'lumot talab qilsa, finetuning esa o'z navbatida prompt muhandisligiga qaraganda kattaroq hajmni so'raydi.
Qancha ma'lumot kerakligidan qat'i nazar, ma'lumotlar bo'yicha tajriba modelni o'rganishda foydalidir, chunki uning o'qitish ma'lumotlari o'sha modelning kuchli va zaif tomonlari haqida muhim ishoralar beradi.
Inference optimizatsiyasi
Inference (ya'ni, o'qitilgan modeldan yangi ma'lumotlar asosida natija olish jarayoni) optimizatsiyasi modellarni tezroq va arzonroq qilishni anglatadi. Inference optimizatsiyasi ML muhandisligi uchun har doim muhim bo'lgan. Foydalanuvchilar hech qachon tezroq modellarga yo'q demaydi, kompaniyalar esa arzonroq inference'dan doim foyda ko'rishi mumkin. Biroq, fundamental modellar miqyosi kengayib, yanada yuqori inference xarajatlari va kechikishiga olib kelgani sari, inference optimizatsiyasi yanada muhimroq bo'lib bormoqda.
Fundamental modellar bilan bog'liq qiyinchiliklardan biri shundaki, ular ko'pincha avtoregressivdir — ya'ni, tokenlar ketma-ket generatsiya qilinadi. Agar modelga bitta token generatsiya qilish uchun 10 ms vaqt ketsa, 100 ta tokenli natijani generatsiya qilish uchun bir soniya, undan ham uzunroq natijalar uchun esa yanada ko'proq vaqt kerak bo'ladi. Foydalanuvchilarning tobora sabrsiz bo'lib borayotganini hisobga olsak, SI dasturlarining kechikishini odatiy internet dasturi uchun kutiladigan 100 ms darajasiga tushirish ulkan muammodir. Inference optimizatsiyasi ham sanoatda, ham akademik doiralarda faol tadqiqot sohasiga aylandi.
Modelni ishlab chiqishning turli toifalari SI muhandisligi bilan qanday o'zgarganining qisqacha xulosasi 1-4-jadvalda ko'rsatilgan.
| Toifa | An'anaviy ML bilan ishlash | Fundamental modellar bilan ishlash |
|---|---|---|
| Modellashtirish va o'qitish | Modelni noldan o'qitish uchun ML bilimlari talab etiladi | ML bilimlari majburiy emas, lekin bo'lsa yaxshi (Ko'pchilik bu fikrga qo'shilmasligi va ML bilimlari majburiy ekanligini aytishi mumkin.) |
| Ma'lumotlar to'plami muhandisligi | Ko'proq xususiyat muhandisligi (feature engineering) bilan bog'liq, ayniqsa jadvalli ma'lumotlarda | Xususiyat muhandisligi kamroq, ko'proq ma'lumotlardagi takrorlanishlarni olib tashlash, tokenizatsiya, kontekstni qidirib topish va sifat nazorati bilan bog'liq |
| Inference optimizatsiyasi | Muhim | Yanada muhimroq |
Inference optimizatsiyasi texnikalari, jumladan, kvantlash (quantization), distillash (distillation) va parallellashtirish (parallelism), 7-bobdan 9-bobgacha muhokama qilinadi.
Dasturni ishlab chiqish
An'anaviy ML muhandisligida jamoalar o'zlarining xususiy modellari yordamida dasturlar yaratishardi va bunda model sifati asosiy farqlovchi omil edi. Fundamental modellar bilan esa, ko'plab jamoalar bir xil modeldan foydalanganligi sababli, farqlanishga dasturni ishlab chiqish jarayoni orqali erishish kerak.
Dasturni ishlab chiqish qatlami quyidagi mas'uliyatlardan iborat: baholash, prompt muhandisligi va SI interfeysi.
Baholash
Baholash — bu xavflarni yumshatish va imkoniyatlarni ochish demakdir. Baholash butun modelni moslashtirish jarayonida zarur. U modellarni tanlash, yutuqlarni o'lchash, dasturning joriy etishga tayyor yoki tayyor emasligini aniqlash hamda amaliyotdagi muammolar va takomillashtirish imkoniyatlarini aniqlash uchun kerak.
Garchi baholash ML muhandisligida har doim muhim bo'lgan bo'lsa-da, fundamental modellar bilan u yanada muhimroqdir va buning ko'plab sabablari bor. Fundamental modellarni baholashdagi qiyinchiliklar 3-bobda muhokama qilinadi. Qisqacha aytganda, bu qiyinchiliklar asosan fundamental modellarning erkin natijali (open-ended) tabiati va kengaytirilgan imkoniyatlaridan kelib chiqadi. Masalan, firibgarlikni aniqlash kabi cheklangan natijali ML vazifalarida, odatda, modelingiz natijalarini solishtirishingiz mumkin bo'lgan kutilgan etalon javoblar (ground truths) mavjud bo'ladi. Agar modelning natijasi kutilgan natijadan farq qilsa, siz modelning xato qilganini bilasiz. Chatbotlar kabi vazifalarda esa, har bir prompt uchun shunchalik ko'p ehtimoliy javoblar mavjudki, modelning javobini solishtirish uchun etalon javoblarning to'liq ro'yxatini tuzishning iloji yo'q.
Ko'plab moslashtirish texnikalarining mavjudligi ham baholashni qiyinlashtiradi. Bir texnika bilan yomon ishlaydigan tizim boshqasi bilan ancha yaxshiroq ishlashi mumkin. Google 2023-yil dekabr oyida Gemini'ni ishga tushirganda, ular Gemini'ning MMLU benchmarkida (Hendrycks va boshq., 2020) ChatGPT'dan yaxshiroq ekanligini da'vo qilishdi. Google Gemini'ni CoT@32 deb nomlangan prompt muhandisligi texnikasi yordamida baholagan edi. Bu texnikada Gemini'ga 32 ta misol ko'rsatilgan, ChatGPT'ga esa atigi 5 ta misol ko'rsatilgan. Ikkalasiga ham beshtadan misol ko'rsatilganda esa, ChatGPT yaxshiroq natija ko'rsatgan (1-5-jadval).
Gemini Ultra | Gemini Pro | GPT-4 | GPT-3.5 | PaLM 2-L | Claude 2 | Inflection-2 | Grok 1 | Llama-2 | |
|---|---|---|---|---|---|---|---|---|---|
| MMLU samaradorligi | 90.04%CoT@32 | 79.13%CoT@8 | 87.29%CoT@32(API orqali) | 70.0% 5-shot | 78.4% 5-shot | 78.5% 5-shot | 79.6% 5-shot CoT | 73.0% 5-shot | 68.0% |
| 83.7% 5-shot | 71.8% 5-shot | 86.4% 5-shot (reported) |
Gemini'ning texnik hisobotida (2023-yil dekabr) ko'rish mumkin."5-shot" modelga 5 ta namuna ko'rsatilganini, "CoT@32" esa "Chain of Thought" yondashuvi bilan 32 ta namuna ko'rsatilganini bildiradi.
Prompt muhandisligi va kontekstni qurish
Prompt muhandisligi — bu SI modellarini, ularning og'irliklarini (weights) o'zgartirmasdan, faqat kiruvchi ma'lumotning o'zi orqali kerakli xususiyatlarni namoyon etishga undashdir. Gemini'ni baholash voqeasi prompt muhandisligining model samaradorligiga qanchalik katta ta'sir qilishini yaqqol ko'rsatib beradi. Boshqa bir prompt muhandisligi texnikasini qo'llash orqali Gemini Ultra'ning MMLU bo'yicha samaradorligi 83.7% dan 90.04% ga ko'tarildi.
Faqat promptlar yordamida modelni aql bovar qilmas ishlarni bajarishga majbur qilish mumkin. To'g'ri ko'rsatmalar modelni siz xohlagan vazifani, siz tanlagan formatda bajarishga unday oladi. Prompt muhandisligi shunchaki modelga nima qilish kerakligini aytish emas. Bu, shuningdek, modelga berilgan vazifani bajarishi uchun zarur bo'lgan kontekst va vositalarni taqdim etish hamdir. Uzun kontekstli murakkab vazifalar uchun, model o'z tarixini kuzatib borishi uchun unga xotirani boshqarish tizimini ham taqdim etishingiz kerak bo'lishi mumkin. 5-bobda prompt muhandisligi, 6-bobda esa kontekstni qurish muhokama qilinadi.
SI interfeysi
SI interfeysi (AI Interface) — bu foydalanuvchilarning SI ilovangiz bilan ishlashi uchun interfeys yaratishni anglatadi. Fundamental modellar paydo bo'lishidan avval, faqat o'z modellarini ishlab chiqishga yetadigan ulkan resursi bor kompaniyalargina SI dasturlarini yarata olardi. Bu dasturlar ko'pincha tashkilotlarning mavjud mahsulotlariga singdirib yuborilardi. Masalan, firibgarlikni aniqlash tizimlari Stripe, Venmo va PayPal xizmatlarining ajralmas qismi edi. Tavsiya tizimlari (recommender systems) esa Netflix, TikTok va Spotify kabi ijtimoiy tarmoqlar va media platformalarining negizini tashkil etardi.
Fundamental modellar sharofati bilan endi istagan odam SI ilovalarini yarata oladi. Siz o'z ilovangizni mustaqil mahsulot sifatida taqdim etishingiz yoki ularni boshqa mahsulotlarga, jumladan, o'zgalar yaratgan tizimlarga ham integratsiya qilishingiz mumkin. Masalan, ChatGPT va Perplexity — mustaqil mahsulotlardir, GitHub Copilot esa ko'pincha VSCode muhitida plagin sifatida, Grammarly esa Google Docs uchun brauzer kengaytmasi sifatida ishlatiladi. Midjourney'ni esa ham uning mustaqil veb-dasturi orqali, ham uning Discord'dagi integratsiyasi orqali ishlatish mumkin.
Mustaqil SI dasturlari uchun interfeyslarni ta'minlaydigan yoki SI'ni mavjud mahsulotlarga oson integratsiya qilish imkonini beradigan vositalarga ehtiyoj bor. Quyida, SI dasturlari uchun ommalashib borayotgan interfeyslarning ba'zilari keltirilgan:
- Mustaqil veb, desktop va mobil dasturlar.4
- Foydalanuvchilarga veb-saytlarni ko'zdan kechirish paytida SI modellariga tezda so'rov yuborish imkonini beradigan brauzer kengaytmalari.
- Slack, Discord, WeChat va WhatsApp kabi chat dasturlariga integratsiya qilingan chatbotlar.
- VSCode, Shopify va Microsoft 365 kabi ko'plab mahsulotlar dasturchilarga SI'ni o'z mahsulotlariga plaginlar va qo'shimchalar sifatida integratsiya qilish imkonini beruvchi API'larni taqdim etadi. Bu API'lardan, shuningdek, 6-bobda muhokama qilinadi, SI agentlari butun dunyo bilan ishlashi uchun ham foydalanish mumkin.
Garchi chat interfeysi eng ko'p qo'llanilsa-da, SI interfeyslari ovozga asoslangan (masalan, ovozli yordamchilarda) yoki mujassamlangan (masalan, to'ldirilgan va virtual reallikda) bo'lishi ham mumkin.
Bu yangi SI interfeyslari, shuningdek, foydalanuvchi fikr-mulohazalarini yig'ish va ajratib olishning yangi usullarini ham anglatadi. Suhbat interfeysi foydalanuvchilarga tabiiy tilda fikr-mulohaza berishni ancha osonlashtiradi, ammo bu fikr-mulohazani ajratib olish qiyinroq. Foydalanuvchi fikr-mulohazalari dizayni 10-bobda muhokama qilinadi.
Dasturlarni ishlab chiqishning turli toifalari SI muhandisligi bilan qanday o'zgarganining qisqacha xulosasi 1-6-jadvalda ko'rsatilgan.
| Toifa | An'anaviy ML bilan ishlash | Fundamental modellar bilan ishlash |
|---|---|---|
| SI interfeysi | Kamroq muhim | Muhim |
| Prompt muhandisligi | Qo'llanilmaydi | Muhim |
| Baholash | Muhim | Muhimroq |
SI muhandisligi va Full-stack muhandisligi farqlari
Dasturlarni ishlab chiqishga, ayniqsa, interfeyslarga bo'lgan e'tiborning ortishi SI muhandisligini full-stack ishlab chiqishga yaqinlashtiradi.5 Interfeyslarning ahamiyati ortib borayotgani SI vositalari dizaynida ko'proq frontend muhandislarini jalb qilishga qaratilgan o'zgarishlarga olib kelmoqda. An'anaviy ML muhandisligi asosan Python'ga yo'naltirilgan edi. Fundamental modellardan oldin eng mashhur ML freymvorklari asosan Python API'larini qo'llab-quvvatlardi. Bugungi kunda Python hali ham ommabop, ammo LangChain.js, Transformers.js, OpenAI'ning Node kutubxonasi va Vercel'ning AI SDK'si kabi JavaScript API'larini qo'llab-quvvatlash ham ortib bormoqda.
Garchi ko'plab SI muhandislari an'anaviy ML sohasidan kelgan bo'lsalar-da, tobora ko'proq mutaxassislar veb-ishlab chiqish yoki full-stack sohalaridan kelmoqda. Full-stack muhandislarining an'anaviy ML muhandislaridan ustunligi ularning g'oyalarni tezda demoga aylantirish, fikr-mulohazalarni olish va iteratsiya qilish qobiliyatidir.
An'anaviy ML muhandisligida ishni odatda ma'lumot yig'ish va modelni o'qitishdan boshlaysiz. Mahsulotni yaratish esa eng oxirida keladi. Biroq, bugungi kunda SI modellarining tayyor holatda mavjudligi tufayli, ishni avval mahsulotni yaratishdan boshlash, ma'lumotlar va modellarga esa faqat mahsulot o'zini oqlaganidan (shows promise) keyingina sarmoya kiritish imkoniyati paydo bo'ldi. Bu jarayon 1-16-rasmda tasvirlangan.

An'anaviy ML muhandisligida modelni ishlab chiqish va mahsulotni ishlab chiqish ko'pincha bir-biridan uzilgan jarayonlar bo'lib, ko'plab tashkilotlarda ML muhandislari mahsulotga oid qarorlarda kamdan-kam ishtirok etishadi. Biroq, fundamental modellar bilan, SI muhandislari mahsulotni yaratishda ancha faolroq ishtirok etishga moyil.
Izohlar
-
Bir "Fortune 500" kompaniyasining SI rahbari menga aytganidek: uning jamoasi 10 ta GPU bilan ishlashni biladi, lekin 1000 ta GPU bilan esa ishlashni bilishmaydilar. ↩
-
Va ularga aql bovar qilmas darajada katta maosh taklif qilinadi. ↩
-
Agar siz "dastlabki o'qitish" va "yakuniy o'qitish" atamalarini ijodkorlikdan yiroq deb hisoblasangiz, siz yolg'iz emassiz. SI tadqiqot hamjamiyati ko'p narsada zo'r, lekin nom berishda emas. Biz allaqachon "katta til modellari" atamasi "katta" so'zining noaniqligi tufayli ilmiy atama bo'la olmasligi haqida gaplashgan edik. Va men odamlarning "X — sizga kerak bo'lgan yagona narsa" sarlavhasi bilan maqolalar chop etishni bas qilishlarini juda xohlardim. ↩
-
Streamlit,GradiovaPlotly DashSI veb-dasturlarini yaratish uchun keng tarqalgan vositalardir. ↩ -
Anton Bacaj menga aytganidek: “SI muhandisligi — bu shunchaki stek'iga SI modellari qo'shilgan dasturiy ta'minot muhandisligidir.” ↩