Sun'iy intellekt muhandisligining yuksalishi
Fundamental modellar katta til modellaridan, ular esa, o'z navbatida, oddiy til modellaridan kelib chiqqan. ChatGPT va GitHub Copilot kabi dasturlar go'yo hech qayerdan paydo bo'lib qolgandek tuyulsa-da, aslida ular o'nlab yillik texnologik taraqqiyotning mahsulidir, zero birinchi til modellari 1950-yillarda paydo bo'lgan. Ushbu bo'limda til modellaridan sun'iy intellekt muhandisligigacha bo'lgan evolyutsiyaga imkon bergan eng muhim yutuqlar batafsil ko'rib chiqiladi.
Til modellari (LM) dan katta til modellari (LLM) ga
Til modellari ancha vaqtdan beri mavjud bo'lsa-da, ular faqatgina o'z-o'zini nazorat qilish (self-supervision) yordamidagina bugungi miqyosga erisha oldi. Ushbu qismda til modeli va o'z-o'zini nazorat qilish tushunchalari qisqacha sharhlanadi. Agar bu tushunchalar bilan allaqachon tanish bo'lsangiz, bu qismni o'tkazib yuborishingiz mumkin.
Til modellari
Til modeli bir yoki bir nechta til haqidagi statistik ma'lumotlarni o'zida jamlaydi. Mohiyatan, bu ma'lumotlar biror so'zning ma'lum bir kontekstda paydo bo'lish ehtimoli qanchalik ekanligini bildiradi. Masalan, “Mening sevimli rangim __” degan kontekst berilganda, ingliz tilini o'zida jamlagan til modeli “mashina” so'ziga qaraganda “ko'k” so'zini ko'proq bashorat qilishi kerak.
Tillarning statistik tabiati asrlar oldin kashf etilgan. 1905-yilda yozilgan “Raqsga tushayotgan odamchalar sarguzashti” hikoyasida Sherlok Holms sirli tayoqcha shakllar ketma-ketligining shifrini yechish uchun ingliz tilining oddiy statistik ma'lumotlaridan foydalangan. Ingliz tilida eng ko'p uchraydigan harf E bo'lgani uchun, Holms eng ko'p uchraydigan tayoqcha shakli E harfini anglatishi kerak degan xulosaga kelgan.
Keyinroq, Klod Shennon Ikkinchi jahon urushi paytida dushman xabarlarining shifrini ochish uchun yanada murakkabroq statistikadan foydalangan. Uning ingliz tilini qanday modellashtirish haqidagi ishi 1951-yilda chop etilgan va o'z davrida tub burilish yasagan “Bosma ingliz tilining bashorati va entropiyasi” ("Prediction and Entropy of Printed English") nomli maqolasida nashr etilgan. Ushbu maqolada kiritilgan ko'plab tushunchalar, jumladan, entropiya, bugungi kunda ham til modellashtirishda qo'llaniladi.
Dastlabki paytlarda til modeli faqat bitta tilni o'z ichiga olardi. Biroq, bugungi kunda til modeli bir nechta tilni qamrab olishi mumkin.
Til modelining asosiy birligi — bu token. Token — bu modelga qarab, belgi, so'z yoki so'zning bir qismi (masalan, -tion kabi) bo'lishi mumkin.1 Masalan, ChatGPT ortida turgan model — GPT-4 — “I can't wait to build AI applications” iborasini 1-1-rasmda ko'rsatilganidek, to'qqizta tokenga ajratadi. E'tibor bering, bu misolda “can't” so'zi ikkita tokenga — can va t'ga ajratilgan. Turli OpenAI modellarining matnni qanday tokenlarga ajratishini OpenAI veb-saytida ko'rishingiz mumkin.
 1-1 rasm. GPT-4 modeli "I can't wait to build AI applications" iborasini tokenlarga ajratish
1-1 rasm. GPT-4 modeli "I can't wait to build AI applications" iborasini tokenlarga ajratish
Asl matnni tokenlarga ajratish jarayoni tokenizatsiya deb ataladi. GPT-4 uchun o'rtacha bitta token so'z uzunligining taxminan ¾ qismiga teng. Demak, 100 ta token taxminan 75 ta so'zga to'g'ri keladi.
Model ishlay oladigan barcha tokenlar to'plami modelning lug'ati (vocabulary) deb ataladi. Xuddi alifbodagi sanoqli harflardan foydalanib ko'plab so'zlarni hosil qilish mumkin bo'lganidek, cheklangan miqdordagi tokenlar yordamida ham juda ko'p sonli turli xil so'zlarni yaratish mumkin. Mixtral 8x7B modelining lug'at hajmi 32 000 tani tashkil etadi. GPT-4'ning lug'at hajmi esa 100 256 ga teng. Tokenizatsiya usuli va lug'at hajmi model yaratuvchilari tomonidan belgilanadi.
Eslatma
Nima uchun til modellari so'z yoki belgilar o'rniga tokenlardan foydalanadi? Buning uchta asosiy sababi bor:
-
Ma'noli qismlarga ajratish. Belgilarga nisbatan, tokenlar modelga so'zlarni ma'noli tarkibiy qismlarga ajratish imkonini beradi. Masalan, “cooking” (pishirish) so'zini “cook” (pishirmoq) va “ing” (jarayonni bildiruvchi qo'shimcha) qismlariga ajratish mumkin, bunda ikkala qism ham asl so'zning ma'nosidan bir qismini o'zida saqlab qoladi.
-
Samaradorlik. Noyob tokenlar soni noyob so'zlar sonidan kamroq bo'lgani uchun, bu modelning lug'at hajmini qisqartiradi va uni yanada samaraliroq qiladi (bu haqda 2-bobda muhokama qilinadi).
-
Noma'lum so'zlarni qayta ishlash. Tokenlar, shuningdek, modelga noma'lum so'zlarni qayta ishlashga yordam beradi. Masalan, “chatgpting” kabi o'ylab topilgan so'zni “chatgpt” va “ing” qismlariga ajratish mumkin, bu esa modelga uning tuzilishini tushunishga yordam beradi. Shunday qilib, tokenlar bir tomondan birliklar sonini so'zlarga qaraganda kamroq ushlab tursa, ikkinchi tomondan, alohida belgilarga qaraganda ko'proq ma'no saqlab qolish o'rtasidagi muvozanatni ta'minlaydi.
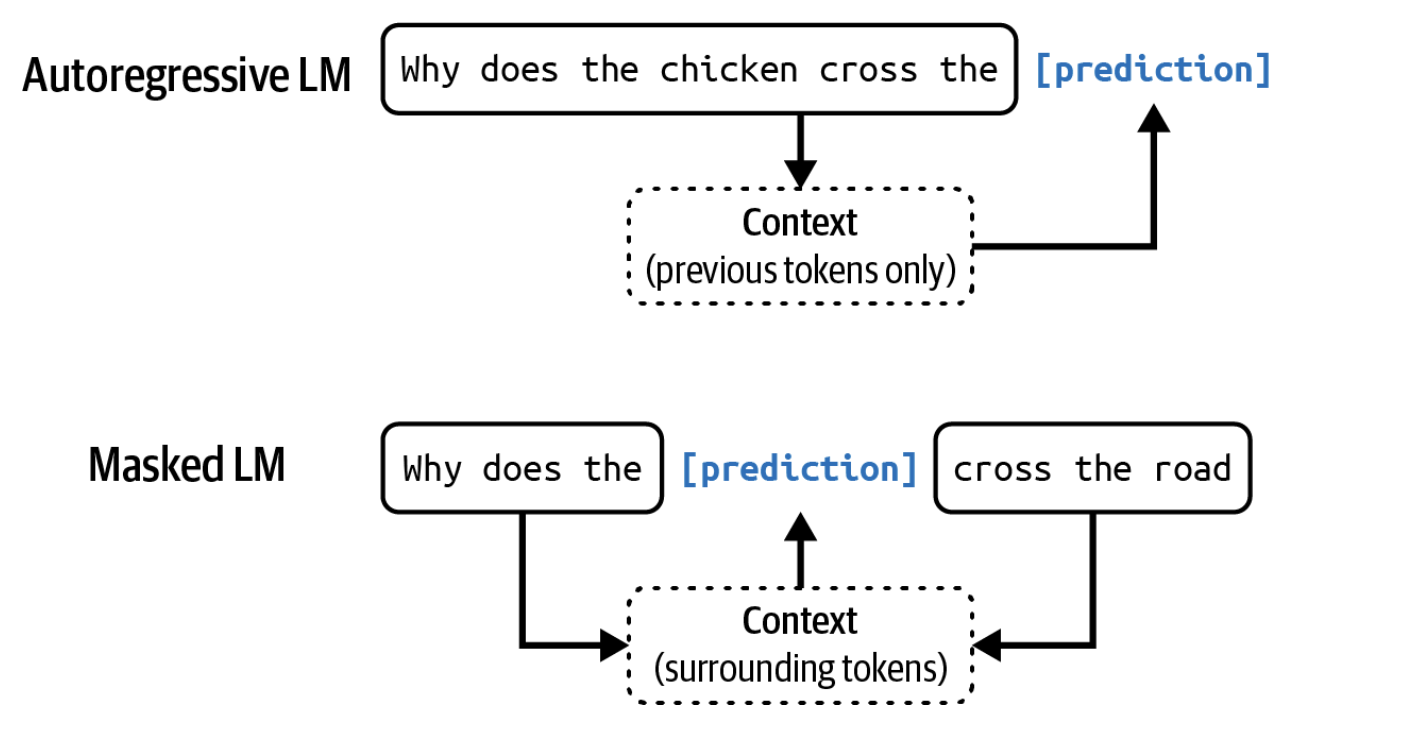
Til modellarining ikkita asosiy turi mavjud: niqoblangan (masked) til modellari va avtoregressiv (autoregressive) til modellari. Bu ikki tur bir-biridan tokenni bashorat qilishda qanday ma'lumotlardan foydalanishi bilan ajralib turadi:
Niqoblangan til modellari
Niqoblangan til modeli ketma-ketlikning istalgan joyidagi tushib qolgan tokenlarni, ham oldingi, ham keyingi kontekstdan foydalangan holda, bashorat qilishga o'rgatiladi. Mohiyatan, niqoblangan til modeli bo'sh joyni to'ldirishga o'rgatiladi. Masalan, “Mening sevimli __ ko'k” degan kontekst berilsa, niqoblangan til modeli bo'sh joy “rang” so'zi bo'lishi ehtimoli yuqori ekanligini bashorat qilishi kerak. Niqoblangan til modelining mashhur namunasi — bu transformatorlardan olingan ikki tomonlama enkoder tasvirlar (bidirectional encoder representations from transformers), ya'ni BERT (Devlin va boshq., 2018).
Ushbu kitob yozilayotgan vaqtda, niqoblangan til modellari odatda hissiyot tahlili (sentiment analysis) va matn tasnifi (text classification) kabi generativ bo'lmagan vazifalar uchun qo'llaniladi. Ular, shuningdek, koddagi xatolarni tuzatish (code debugging) kabi umumiy kontekstni tushunishni talab qiladigan vazifalar uchun ham foydalidir, chunki bunda model xatolarni aniqlash uchun ham oldingi, ham keyingi kodni tushunishi kerak bo'ladi.
Avtoregressiv til modellari
Avtoregressiv til modeli ketma-ketlikdagi keyingi tokenni faqat o'zidan oldingi tokenlardan foydalangan holda bashorat qilishga o'rgatiladi. U “Mening sevimli rangim __” jumlasida keyin nima kelishini bashorat qiladi.2 Avtoregressiv model uzluksiz ravishda birin-ketin token generatsiya qila oladi. Bugungi kunda avtoregressiv til modellari matn generatsiyasi uchun eng maqbul modellar hisoblanadi va shu sababli ular niqoblangan til modellariga qaraganda ancha ommaboproqdir.3
1-2-rasmda til modellarining bu ikki turi ko'rsatilgan.
Eslatma
Ushbu kitobda, agar alohida ta'kidlanmagan bo'lsa, “til modeli” deganda avtoregressiv model nazarda tutiladi.
Til modellarining natijalari erkin va cheklanmagandir. Til modeli o'zining qat'iy, cheklangan lug'atidan foydalanib, cheksiz miqdordagi ehtimoliy natijalarni yarata oladi. Erkin natijalar generatsiya qila oladigan model generativ deb ataladi, shu sababli generativ SI atamasi kelib chiqqan.
Til modelini bir to'ldiruvchi mashina deb tasavvur qilish mumkin: unga biror matn (prompt) berilsa, u shu matnni to'ldirishga harakat qiladi. Mana bir misol:
Shuni ta'kidlash muhimki, bu to'ldirmalar ehtimolliklarga asoslangan bashoratlar bo'lib, ularning to'g'ri bo'lishi kafolatlanmagan. Til modellarining aynan shu ehtimoliy tabiati ulardan foydalanishni bir vaqtning o'zida ham hayajonli, ham asabiylashtiruvchi qiladi. Bu mavzuni 2-bobda yanada chuqurroq o'rganamiz.
Garchi sodda eshitilsa-da, to'ldirish jarayoni nihoyatda qudratli imkoniyatdir. Tarjima, qisqacha bayon qilish, kod yozish va matematik masalalarni yechish kabi ko'plab vazifalarni to'ldirish vazifalari sifatida ifodalash mumkin. Masalan, “Fransuz tilida 'ahvollaringiz qalay' … degani” prompti berilganda, til modeli uni “Comment ça va” bilan to'ldirishi mumkin, bu esa bir tildan ikkinchisiga samarali tarjima qilish demakdir.
Yana bir misol, quyidagi prompt berilganda:
Til modeli uni “Ehtimoliy spam” deb to'ldirishi mumkin, bu esa o'z navbatida til modelini spam-klassifikatorga aylantiradi.
To'ldirish qudratli bo'lsa-da, bu suhbat qurish bilan bir xil narsa emas. Masalan, agar siz to'ldiruvchi mashinaga savol bersangiz, u savolga javob berish o'rniga, sizning gapingizni yana bir savol qo'shish orqali to'ldirishi mumkin. "Yakuniy o'qitish" (Post-Training) bo'limida modelni foydalanuvchi so'roviga qanday qilib munosib javob berishga o'rgatish muhokama qilinadi.
O'z-o'zini nazorat qilish (Self-supervision)
Til modellashtirish — bu ko'plab ML algoritmlaridan faqat bittasigina xolos. Bundan tashqari, obyektlarni aniqlash, mavzularni modellashtirish, tavsiya tizimlari, ob-havoni bashorat qilish, aksiya narxlarini taxmin qilish va hokazolar uchun ham modellar mavjud. Xo'sh, til modellarining boshqa ko'plab ML algoritmlaridan qanday afzalligi bor va nima ularni ChatGPT inqilobiga olib kelgan miqyoslash yondashuvining markaziga aylantirdi?
Javob shundaki, til modellarini o'z-o'zini nazorat qilish (self-supervision) yordamida o'qitish mumkin, holbuki, boshqa ko'plab modellar nazoratli o'qitishni (supervision) talab qiladi. Nazoratli o'qitish — bu ML algoritmlarini maxsus belgilangan ma'lumotlar yordamida o'qitish jarayonidir va bunday ma'lumotlarni to'plash qimmatga tushishi va ko'p vaqt talab qilishi mumkin. O'z-o'zini nazorat qilish esa aynan shu ma'lumotlarni belgilashdagi to'siqni yengib o'tishga yordam beradi. Bu esa, o'z navbatida, modellarga o'rganish uchun kattaroq ma'lumotlar to'plamlarini yaratish va ularning miqyosini samarali ravishda kengaytirish imkonini beradi. Keling, buni batafsil ko'rib chiqamiz.
Nazoratli o'qitishda siz model o'rganishi kerak bo'lgan xususiyatlarni ko'rsatish uchun namunalarni belgilab chiqasiz va keyin modelni shu namunalar asosida o'qitasiz. O'qitib bo'lingach, modelni yangi ma'lumotlarga qo'llash mumkin bo'ladi. Masalan, firibgarlikni aniqlash modelini o'qitish uchun siz har biri “firibgarlik” yoki “firibgarlik emas” deb belgilangan tranzaksiyalar namunalaridan foydalanasiz. Model bu namunalardan o'rganib olgach, siz undan yangi tranzaksiyaning firibgarlik ekanligini bashorat qilish uchun foydalanishingiz mumkin.
2010-yillarda SI modellarining muvaffaqiyati aynan nazoratli o'qitishga asoslangan edi. Chuqur o'rganish (deep learning) inqilobini boshlab bergan model — AlexNet (Krizhevsky va boshq., 2012) — nazoratli o'qitishga asoslangan edi. U ImageNet ma'lumotlar to'plamidagi 1 milliondan ortiq rasmni tasniflashni o'rganish uchun o'qitilgan. U har bir rasmni “mashina”, “havo shari” yoki “maymun” kabi 1000 ta toifadan biriga ajratgan.
Nazoratli o'qitishning kamchiligi shundaki, ma'lumotlarni belgilash qimmat va ko'p vaqt talab qiladigan jarayondir. Agar bir kishi bitta rasmni belgilashi uchun 5 sent ketsa, ImageNet uchun millionta rasmni belgilash 50 000 dollarga tushadi.4 Agar siz har bir rasmni ikki xil odam belgilashini istasangiz — bu orqali belgilash sifatini qayta tekshirish mumkin bo'ladi — xarajat ikki baravar oshadi. Dunyoda 1000 tadan ancha ko'p obyekt mavjudligini hisobga olsak, modellarning imkoniyatlarini ko'proq obyektlar bilan ishlashga kengaytirish uchun siz ko'proq toifalarga oid belgilarni qo'shishingiz kerak bo'ladi. Miqyosni 1 million toifaga yetkazish uchun esa, faqat belgilash xarajatining o'zi 50 million dollarga yetadi.
Kundalik obyektlarni belgilashni ko'pchilik odamlar maxsus tayyorgarliksiz ham bajara oladi. Shu sababli, buni nisbatan arzon amalga oshirish mumkin. Biroq, hamma belgilash vazifalari ham bunchalik oson emas. Ingliz tilidan lotin tiliga tarjima qiluvchi model uchun lotincha tarjimalarni yaratish ancha qimmatroq. Kompyuter tomografiyasi (CT scan) suratida saraton belgilari bor-yo'qligini belgilash esa tasavvur qilib bo'lmas darajada qimmatga tushardi.
O'z-o'zini nazorat qilish ma'lumotlarni belgilashdagi bu to'siqni yengib o'tishga yordam beradi. O'z-o'zini nazorat qilishda model aniq belgilarni talab qilish o'rniga, belgilarni kiruvchi ma'lumotlarning o'zidan chiqarib oladi. Til modellashtirish o'z-o'zini nazorat qilishga asoslanadi, chunki har bir kiruvchi ketma-ketlik ham belgilarni (bashorat qilinishi kerak bo'lgan tokenlarni), ham model bu belgilarni bashorat qilish uchun foydalanishi mumkin bo'lgan kontekstni o'zida mujassam etadi. Masalan, "Men ko'cha taomlarini yaxshi ko'raman." ("I love street food.") jumlasi 1-1-jadvalda ko'rsatilganidek, oltita o'qitish namunasini beradi.
| Kirish (kontekst) | Chiqish (keyingi token) |
|---|---|
<BOS> | I |
<BOS>, I | love |
<BOS>, I, love | street |
<BOS>, I, love, street | food |
<BOS>, I, love, street, food | . |
<BOS>, I, love, street, food, . | <EOS> |
1-1-jadvalda <BOS> va <EOS> ketma-ketlikning boshlanishi va tugashini bildiradi. Bu belgilar til modelining bir nechta ketma-ketliklar bilan ishlashi uchun zarur. Har bir belgi odatda model tomonidan bitta maxsus token sifatida qabul qilinadi. Ketma-ketlikning tugash belgisi ayniqsa muhim, chunki u til modellariga o'z javoblarini qachon tugatish kerakligini bilishga yordam beradi.5
Eslatma
O'z-o'zini nazorat qilish (self-supervision) nazoratsiz o'qitishdan (unsupervision) farq qiladi. O'z-o'zini nazorat qilishda belgilar kiruvchi ma'lumotlarning o'zidan chiqarib olinsa, nazoratsiz o'qitishda esa belgilarga umuman hojat yo'q.
O'z-o'zini nazorat qilish til modellarining hech qanday belgilashni talab qilmasdan, to'g'ridan-to'g'ri matn ketma-ketliklaridan o'rganishini anglatadi. Matn ketma-ketliklari hamma joyda — kitoblarda, blog postlarida, maqolalarda va Reddit izohlarida — mavjud bo'lgani uchun, ulkan hajmdagi o'qitish ma'lumotlarini to'plash mumkin. Bu esa til modellarining miqyosini kengaytirib, katta til modellariga (LLM) aylanishiga imkon beradi.
Biroq, LLM atamasi ilmiy jihatdan unchalik aniq emas. Til modeli “katta” deb hisoblanishi uchun qanchalik katta bo'lishi kerak? Bugun katta deb hisoblangan narsa ertaga kichik bo'lib qolishi mumkin. Modelning hajmi odatda uning parametrlari soni bilan o'lchanadi. Parametr — bu ML modelidagi o'zgaruvchi bo'lib, u o'qitish jarayonida yangilanib boradi.6 Umuman olganda, garchi bu har doim ham to'g'ri bo'lmasa-da, modelda qancha ko'p parametr bo'lsa, uning kerakli xususiyatlarni o'rganish salohiyati shuncha yuqori bo'ladi.
2018-yil iyun oyida OpenAI'ning birinchi generativ oldindan o'qitilgan transformeri (GPT) chiqqanida, uning 117 million parametri bor edi va bu katta hisoblanardi. 2019-yil fevral oyida OpenAI 1.5 milliard parametrli GPT-2'ni taqdim etganida, 117 million endi kichik deb hisoblana boshlandi. Ushbu kitob yozilayotgan vaqtda, 100 milliard parametrli model katta hisoblanadi. Balki bir kun kelib bu hajm ham kichik bo'lib qolar.
Keyingi bo'limga o'tishdan oldin, odatda e'tibordan chetda qoladigan bir savolga to'xtalib o'tmoqchiman: Nima uchun kattaroq modellarga ko'proq ma'lumot kerak? Kattaroq modellar o'rganish uchun ko'proq salohiyatga ega, shuning uchun ularning samaradorligini maksimal darajaga chiqarish uchun ko'proq o'qitish ma'lumotlari kerak bo'ladi.7 Katta modelni kichik ma'lumotlar to'plamida ham o'qitish mumkin, lekin bu hisoblash resurslarini behuda sarflash bo'ladi. Bu ma'lumotlar to'plamida kichikroq modellar yordamida ham xuddi shunday yoki undan ham yaxshiroq natijalarga erishish mumkin edi.
Katta til modellari (LLM) dan fundamental modellarga
Til modellari misli ko'rilmagan vazifalarni bajara olsa-da, ular matn bilan cheklangan. Biz, insonlar, dunyoni nafaqat til orqali, balki ko'rish, eshitish, sezish va boshqa tuyg'ular yordamida idrok etamiz. Matndan tashqari ma'lumotlarni qayta ishlay olish SI'ning real dunyoda faoliyat yuritishi uchun juda muhimdir.
Shu sababli, til modellari ko'proq ma'lumot modalliklarini o'z ichiga olish uchun kengaytirilmoqda. GPT-4V va Claude 3 kabi modellar ham tasvirlarni, ham matnlarni tushuna oladi. Ba'zi modellar hatto videolar, 3D obyektlar, oqsil tuzilmalari va hokazolarni ham tushunadi. Til modellariga ko'proq ma'lumot modalliklarini qo'shish ularni yanada qudratliroq qiladi. "OpenAI" 2023-yilda o'zining GPT-4V tizimi haqidagi hisobotida shunday degan edi: “LLM'larga qo'shimcha modalliklarni (masalan, tasvirli kiritishlarni) qo'shish ba'zilar tomonidan SI tadqiqotlari va ishlanmalaridagi asosiy, ilg'or yo'nalishlardan biri sifatida qaralmoqda.”
Garchi ko'pchilik Gemini va GPT-4V'ni hali ham LLM deb atasa-da, ularni fundamental modellar deb ta'riflash to'g'riroq bo'ladi. “Fundamental” so'zi ham bu modellarning SI dasturlaridagi muhimligini, ham ularning asosida turli ehtiyojlar uchun yangi narsalar qurish mumkinligini anglatadi.
Fundamental modellar SI tadqiqotlarining an'anaviy tuzilishida yangi bir bosqichni boshlab berdi. Uzoq vaqt davomida SI tadqiqotlari ma'lumot modalliklari bo'yicha bo'lingan edi. Tabiiy tilni qayta ishlash (NLP) faqat matn bilan shug'ullanardi. Kompyuter ko'rishi (Computer vision) faqat tasvir bilan shug'ullanardi. Faqat matn bilan ishlaydigan modellar tarjima va spamni aniqlash kabi vazifalar uchun ishlatilishi mumkin edi. Faqat tasvir bilan ishlaydigan modellar esa obyektlarni aniqlash va tasvirlarni tasniflash uchun ishlatilardi. Faqat audio bilan ishlaydigan modellar nutqni aniqlash (nutqdan-matnga yoki STT) va nutq sintezi (matndan-nutqqa yoki TTS) kabi vazifalarni bajara olardi.
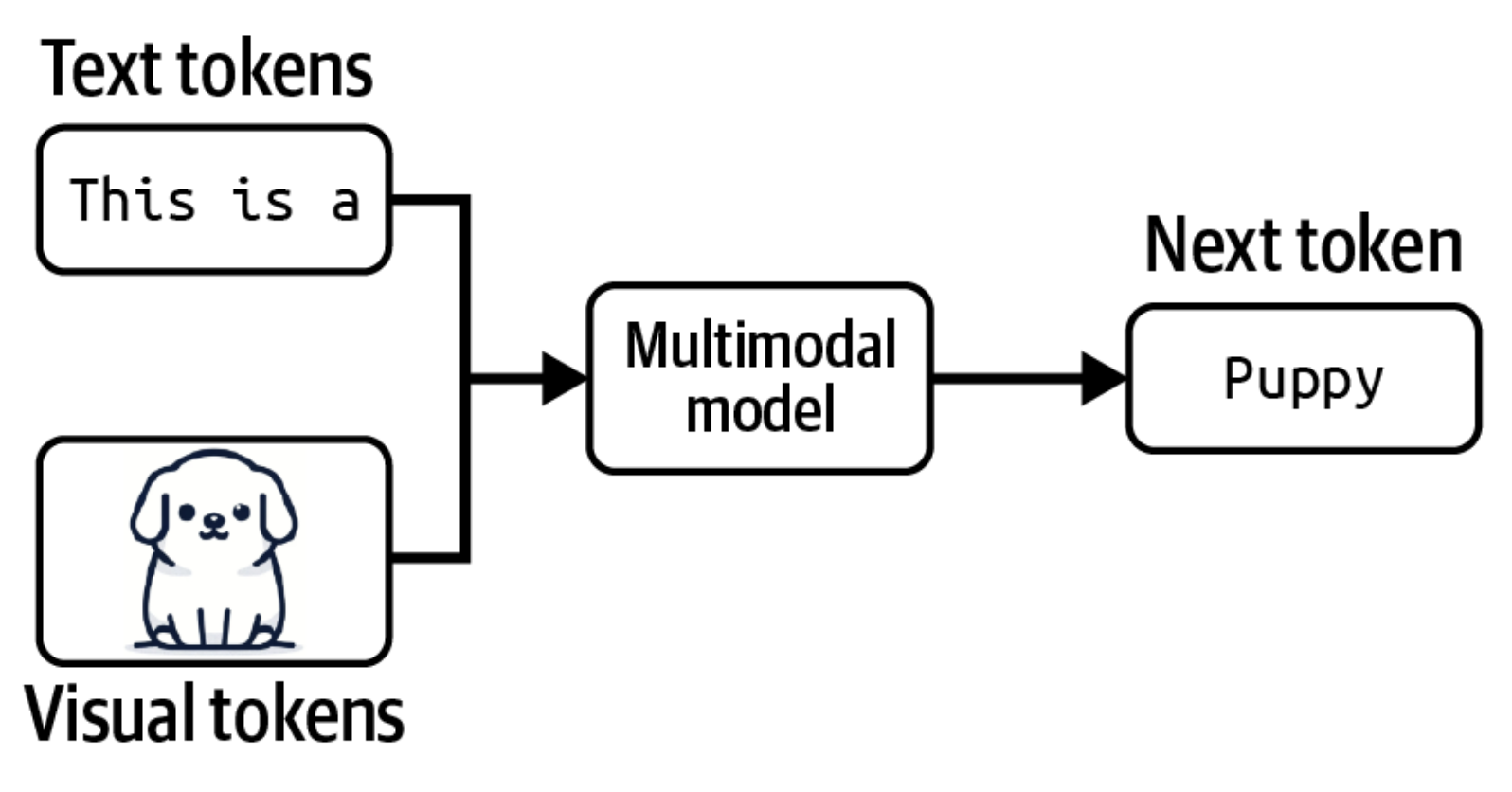
Birdan ortiq ma'lumot modalligi bilan ishlay oladigan model multimodal model deb ham ataladi. Generativ multimodal model esa katta multimodal model (LMM) deyiladi. Agar til modeli keyingi tokenni faqat matnli tokenlarga asoslanib generatsiya qilsa, multimodal model keyingi tokenni ham matn, ham tasvir tokenlariga, ya'ni model qo'llab-quvvatlaydigan barcha modalliklarga asoslanib generatsiya qiladi (1-3-rasm).
Til modellari singari, multimodal modellar ham miqyoslash uchun ma'lumotlarga muhtoj. O'z-o'zini nazorat qilish yondashuvi multimodal modellar uchun ham ishlaydi. Masalan, OpenAI o'zining til-tasvir modeli bo'lgan CLIP'ni o'qitish uchun o'z-o'zini nazorat qilishning tabiiy til nazorati (natural language supervision) deb nomlangan bir turidan foydalangan (OpenAI, 2021). Ular har bir tasvir uchun yorliqlarni mustaqil yaratish o'rniga, internetda birga uchraydigan (tasvir, matn) juftliklarini topdilar. Ular mustaqil belgilash xarajatlarisiz 400 million (tasvir, matn) juftligidan iborat ma'lumotlar to'plamini yarata oldilar, bu esa ImageNet'dan 400 baravar kattaroq edi. Bu ma'lumotlar to'plami CLIP'ning yakuniy o'qitishni talab qilmasdan, bir nechta tasvir tasnifi vazifalariga umumlashtira oladigan birinchi modelga aylanishiga imkon berdi.
Eslatma
Ushbu kitobda fundamental modellar atamasi ham katta til modellari, ham katta multimodal modellarni anglatadi.
Shuni ta'kidlash joizki, CLIP generativ model emas — u erkin natijalar generatsiya qilishga o'rgatilmagan. CLIP — bu ham matnlar, ham tasvirlarning qo'shma embedding'larini hosil qilishga o'rgatilgan embedding modelidir (embedding — bu so'z yoki tasvir kabi murakkab ma'lumotni ma'nosini saqlagan holda ixcham raqamli ko'rinishga, ya'ni vektorga o'tkazish jarayoni). “Embedding'larga kirish” bo'limida embedding'lar batafsil muhokama qilinadi. Hozircha, embedding'larni asl ma'lumotlarning ma'nosini o'zida aks ettirishga harakat qiladigan vektorlar deb tasavvur qilishingiz mumkin. CLIP kabi multimodal embedding modellari Flamingo, LLaVA va Gemini (avvalgi Bard) singari generativ multimodal modellarning asosini, ya'ni tayanchini tashkil etadi.
Maxsus vazifali modellardan umumiy maqsadli modellarga
Fundamental modellar, shuningdek, maxsus vazifali modellardan umumiy maqsadli modellarga o'tish davrini ham anglatadi. Ilgari modellar ko'pincha hissiyot tahlili (sentiment analysis) yoki tarjima kabi maxsus vazifalar uchun ishlab chiqilardi. Hissiyot tahlili uchun o'qitilgan model tarjima qila olmasdi va aksincha.
Fundamental modellar o'zlarining miqyosi va o'qitilish usuli tufayli juda keng doiradagi vazifalarni bajara oladi. Tayyor holatida, umumiy maqsadli modellar ko'plab vazifalarni nisbatan yaxshi bajara oladi. LLM ham hissiyot tahlilini, ham tarjimani bajara oladi. Biroq, ko'p hollarda umumiy maqsadli modelni biror maxsus vazifa uchun uning samaradorligini maksimal darajaga chiqarish maqsadida biroz o'zgartirish (tweak qilish) mumkin.
1-4-rasmda fundamental modellarni baholash uchun Super-NaturalInstructions benchmarkida ishlatiladigan vazifalar ko'rsatilgan va bu fundamental model qanday turdagi vazifalarni bajara olishi haqida tasavvur beradi (Wang va boshq., 2022).
Tasavvur qiling, siz bir chakana savdo kompaniyasi bilan ularning veb-sayti uchun mahsulot tavsiflarini generatsiya qiladigan dastur ustida ishlayapsiz. Tayyor holatidagi model to'g'ri tavsiflarni generatsiya qilishi mumkin, lekin brendning o'ziga xos ovozini (voice) aks ettira olmasligi yoki brendning asosiy g'oyalarini (messaging) ta'kidlay olmasligi mumkin. Generatsiya qilingan tavsiflar hatto marketing nutqi va siyqasi chiqqan iboralarga (cliches) to'la bo'lishi ham mumkin.
Modelni vazifaga moslashtirish
Modeldan o'zingiz istagan natijani olish uchun qo'llashingiz mumkin bo'lgan bir nechta texnikalar mavjud. Masalan, siz kerakli mahsulot tavsiflariga oid misollar bilan boyitilgan batafsil ko'rsatmalar ishlab chiqishingiz mumkin. Bu yondashuv prompt muhandisligi (prompt engineering) deb ataladi. Yoki modelni mijozlarning fikr-mulohazalari bazasiga ulashingiz mumkin, model esa bu ma'lumotlardan dastak sifatida foydalanib, yanada yaxshiroq tavsiflar generatsiya qiladi. Ko'rsatmalarni ma'lumotlar bazasi bilan to'ldirish qidiruv bilan boyitilgan generatsiya (Retrieval-Augmented Generation, RAG) deb nomlanadi. Shuningdek, siz modelni yuqori sifatli mahsulot tavsiflari to'plamida finetuning qilish, ya'ni yakuniy o'qitish imkoniga ham egasiz.
Tayyor modeldan foydalanish yoki o'zi yaratish?
Prompt muhandisligi, RAG va finetuning qilish — bular modelni o'z ehtiyojlaringizga moslashtirish uchun ishlatishingiz mumkin bo'lgan, sun'iy intellekt muhandisligidagi uchta eng keng tarqalgan texnikadir. Kitobning qolgan qismida ularning barchasi batafsil muhokama qilinadi.
Mavjud qudratli modelni o'z vazifangizga moslashtirish, odatda, noldan yangi model yaratishdan ancha oson. Tasavvur qiling: bir tomonda 1 million namuna va olti oylik mehnat, ikkinchi tomonda esa atigi o'nta namuna va bir dam olish kuni. Fundamental modellar SI ilovalarini yaratish xarajatlarini kamaytiradi va yechimni bozorga olib chiqish muddatini (time to market) sezilarli darajada qisqartiradi. Modelni moslashtirish uchun qancha ma'lumot kerakligi esa siz tanlagan usulga bog'liq bo'ladi. Ushbu kitobda har bir usulni muhokama qilar ekanmiz, bu savolga ham alohida to'xtalib o'tamiz. Shunga qaramay, muayyan vazifaga ixtisoslashgan modellarning ham o'ziga yarasha afzalliklari ko'p: masalan, ular ancha ixcham bo'lishi mumkin, bu esa ulardan foydalanishni tezroq va arzonroq qiladi.
O'z modelingizni yaratish yoki mavjudidan foydalanish — bu jamoalar o'zlari javob topishlari kerak bo'lgan klassik "sotib olish yoki o'zi yaratish" masalasidir. Kitob davomidagi muhokamalar bu qarorni qabul qilishga yordam beradi.
Fundamental modellardan sun'iy intellekt muhandisligiga
Sun'iy intellekt muhandisligi (AI Engineering) fundamental modellar asosida dasturlar yaratish jarayonini anglatadi. Odamlar o'n yildan oshiq vaqtdan beri SI dasturlarini yaratib kelishadi — bu jarayon ko'pincha ML muhandisligi yoki MLOps (ML operatsiyalari qisqartmasi) deb nomlanadi. Xo'sh, nega endi aynan sun'iy intellekt muhandisligi haqida gapiryapmiz?
Agar an'anaviy ML muhandisligi ML modellarini ishlab chiqishni o'z ichiga olsa, sun'iy intellekt muhandisligi mavjudlaridan dastak sifatida foydalanadi. Qudratli fundamental modellarning mavjudligi va ochiqligi birgalikda sun'iy intellekt muhandisligining bir yo'nalish sifatida jadal rivojlanishi uchun ideal sharoitlarni yaratadigan uchta omilga olib keldi:
1-omil: Umumiy maqsadli SI imkoniyatlari
Fundamental modellar nafaqat mavjud vazifalarni yaxshiroq bajara olgani uchun, balki ko'proq vazifalarni bajara olgani uchun ham qudratlidir. Ilgari imkonsiz deb hisoblangan dasturlar endi mumkin bo'lib qoldi, ilgari o'ylab ham ko'rilmagan dasturlar paydo bo'lmoqda. Hatto bugun imkonsiz deb hisoblangan dasturlar ertaga mumkin bo'lib qolishi ham hech gap emas. Bu esa SI'ni hayotning ko'proq jabhalari uchun foydaliroq qiladi va ham foydalanuvchilar bazasini, ham SI dasturlariga bo'lgan talabni keskin oshiradi.
Masalan, SI endi insonlar kabi, ba'zan esa ulardan ham yaxshiroq yoza olgani uchun, u muloqotni talab qiladigan har bir vazifani avtomatlashtirishi yoki qisman avtomatlashtirishi mumkin — bu esa deyarli hamma narsani anglatadi. SI elektron pochta xabarlarini yozish, mijozlar so'rovlariga javob berish va murakkab shartnomalarni tushuntirish uchun ishlatilmoqda. Kompyuterga ega bo'lgan har bir kishi marketing materiallarini yaratish, professional portret suratlarni tahrirlash, san'at konsepsiyalarini vizualizatsiya qilish, kitoblarni illustratsiya qilish va hokazolarda yordam beradigan moslashtirilgan, yuqori sifatli tasvirlar va videolarni bir zumda generatsiya qila oladigan vositalarga ega. SI hatto o'qitish ma'lumotlarini sintez qilish, algoritmlar ishlab chiqish va kod yozish uchun ham ishlatilishi mumkin, bularning barchasi kelajakda yanada qudratliroq modellarni o'qitishga yordam beradi.
2-omil: SI sohasiga investitsiyalarning ortishi
ChatGPT'ning muvaffaqiyati ham venchur kapitalistlar, ham korporatsiyalar tomonidan SI sohasiga kiritilayotgan investitsiyalarning keskin ortishiga turtki bo'ldi. SI dasturlarini yaratish arzonlashib, bozorga chiqish tezlashgani sari, SI'ga kiritilgan sarmoyadan olinadigan daromad ham jozibadorroq bo'lib bormoqda. Kompaniyalarning barchasi o'z mahsulotlari va jarayonlariga SI'ni joriy etishga shoshilmoqda. Scribd kompaniyasining amaliy tadqiqotlar bo'yicha katta menejeri Mett Rossning menga aytishicha, uning ishlatilish senariylari uchun taxminiy SI xarajatlari 2022-yil aprelidan 2023-yil apreligacha bo'lgan davrda 100 baravarga kamaygan.
"Goldman Sachs Research" hisob-kitoblariga ko'ra, 2025-yilga kelib SI investitsiyalari AQSHda 100 milliard dollarga, global miqyosda esa 200 milliard dollarga yaqinlashishi mumkin.8 SI ko'pincha raqobatbardosh ustunlik sifatida tilga olinadi. FactSet tadqiqotiga ko'ra, 2023-yilning ikkinchi choragida S&P 500 kompaniyalarining har uchdan biri o'zlarining daromadlari haqidagi hisobotlarida SI'ni tilga olgan — bu ko'rsatkich o'tgan yilgiga nisbatan uch baravar ko'pdir. 1-5-rasmda 2018-yildan 2023-yilgacha bo'lgan davrda o'z daromadlari haqidagi hisobotlarida SI'ni tilga olgan S&P 500 kompaniyalari soni ko'rsatilgan.
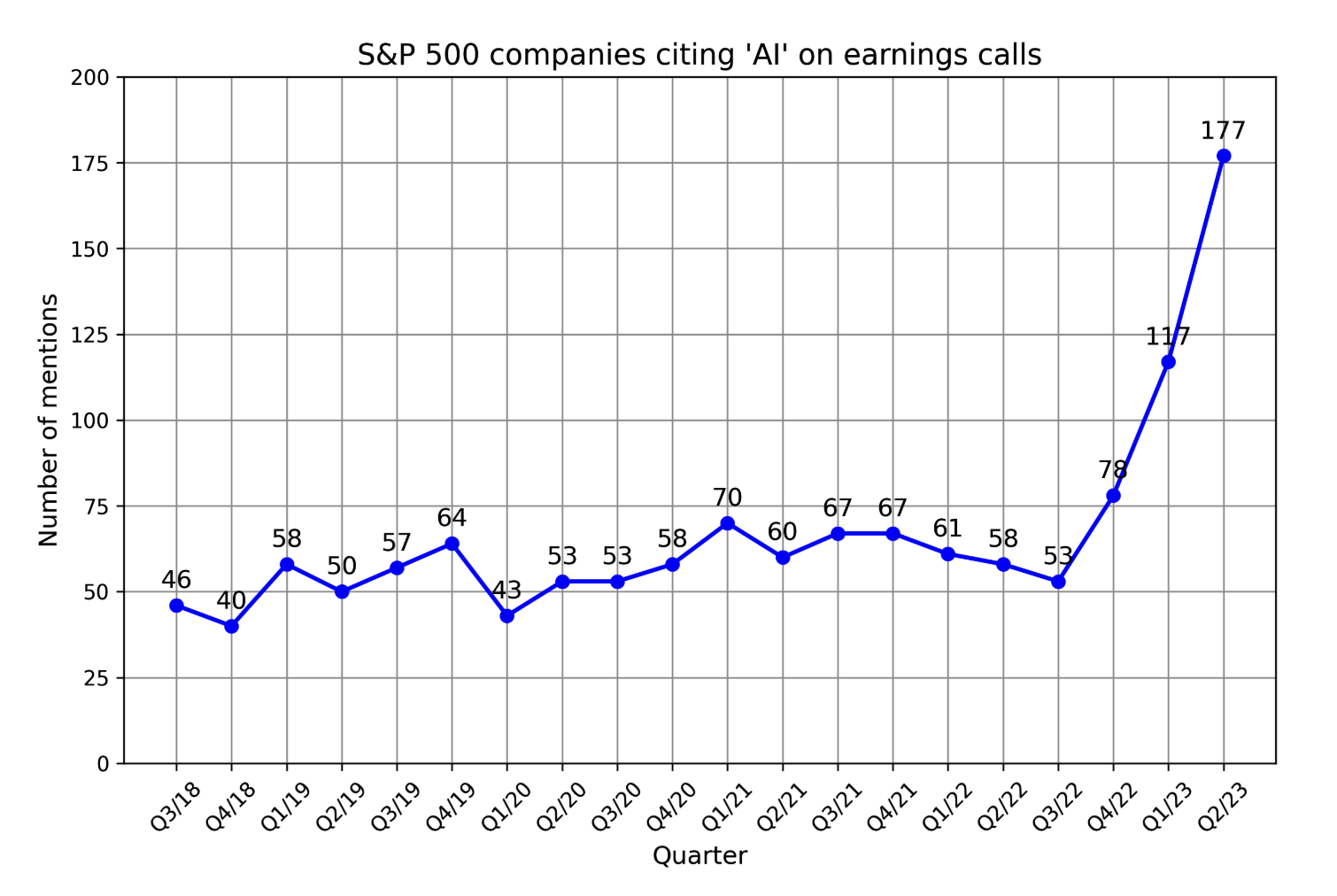
WallStreetZen ma'lumotlariga ko'ra, o'z daromadlari haqidagi hisobotlarida SI'ni tilga olgan kompaniyalarning aksiya narxlari tilga olmaganlarga qaraganda ko'proq o'sgan: 2.4% ga nisbatan o'rtacha 4.6% o'sdi. Bu sabab-oqibat bog'liqligimi (SI bu kompaniyalarni muvaffaqiyatliroq qilmoqda) yoki shunchaki korrelyatsiyami (kompaniyalar yangi texnologiyalarga tez moslashgani uchun muvaffaqiyatli), bu hali noaniq.
3-omil: SI dasturlarini yaratish uchun kirish to'sig'ining pastligi
OpenAI va boshqa model provayderlari tomonidan ommalashtirilgan "xizmat sifatida taqdim etiluvchi model" yondashuvi SI'dan foydalanib dasturlar yaratishni ancha osonlashtiradi. Bu yondashuvda modellar foydalanuvchi so'rovlarini qabul qiluvchi va model natijalarini qaytaruvchi API'lar orqali taqdim etiladi. Bu API'larsiz SI modelidan foydalanish ushbu modelni o'z serverlarida ishga tushirish va xizmat ko'rsatish uchun maxsus infratuzilmani talab qiladi. API'lar esa sizga oddiy API chaqiruvlari orqali qudratli modellardan foydalanish imkonini beradi.
Nafaqat bu, SI minimal darajada kod yozish bilan ham dasturlar yaratish imkonini beradi. Birinchidan, SI siz uchun kod yoza oladi, bu esa dasturiy ta'minot muhandisligi bo'yicha tajribasi bo'lmagan odamlarga o'z g'oyalarini tezda kodga aylantirish va ularni foydalanuvchilarga taqdim etish imkonini beradi. Ikkinchidan, siz bu modellar bilan biror dasturlash tilidan foydalanish o'rniga, oddiy ingliz tilida ishlashingiz mumkin. Endi har kim, ha, istalgan odam SI dasturlarini yarata oladi.
SI muhandisligining portlashi
Fundamental modellarni ishlab chiqish uchun talab etiladigan resurslar tufayli, bu jarayon faqat yirik korporatsiyalar (Google, Meta, Microsoft, Baidu, Tencent), hukumatlar (Yaponiya, BAA) va ambitsiyali, yaxshi moliyalashtirilgan startaplar (OpenAI, Anthropic, Mistral) uchungina mumkin. 2022-yil sentabr oyidagi intervyusida OpenAI bosh direktori Sem Altman aksariyat odamlar uchun eng katta imkoniyat bu modellarni maxsus dasturlarga moslashtirish bo'lishini aytgan.
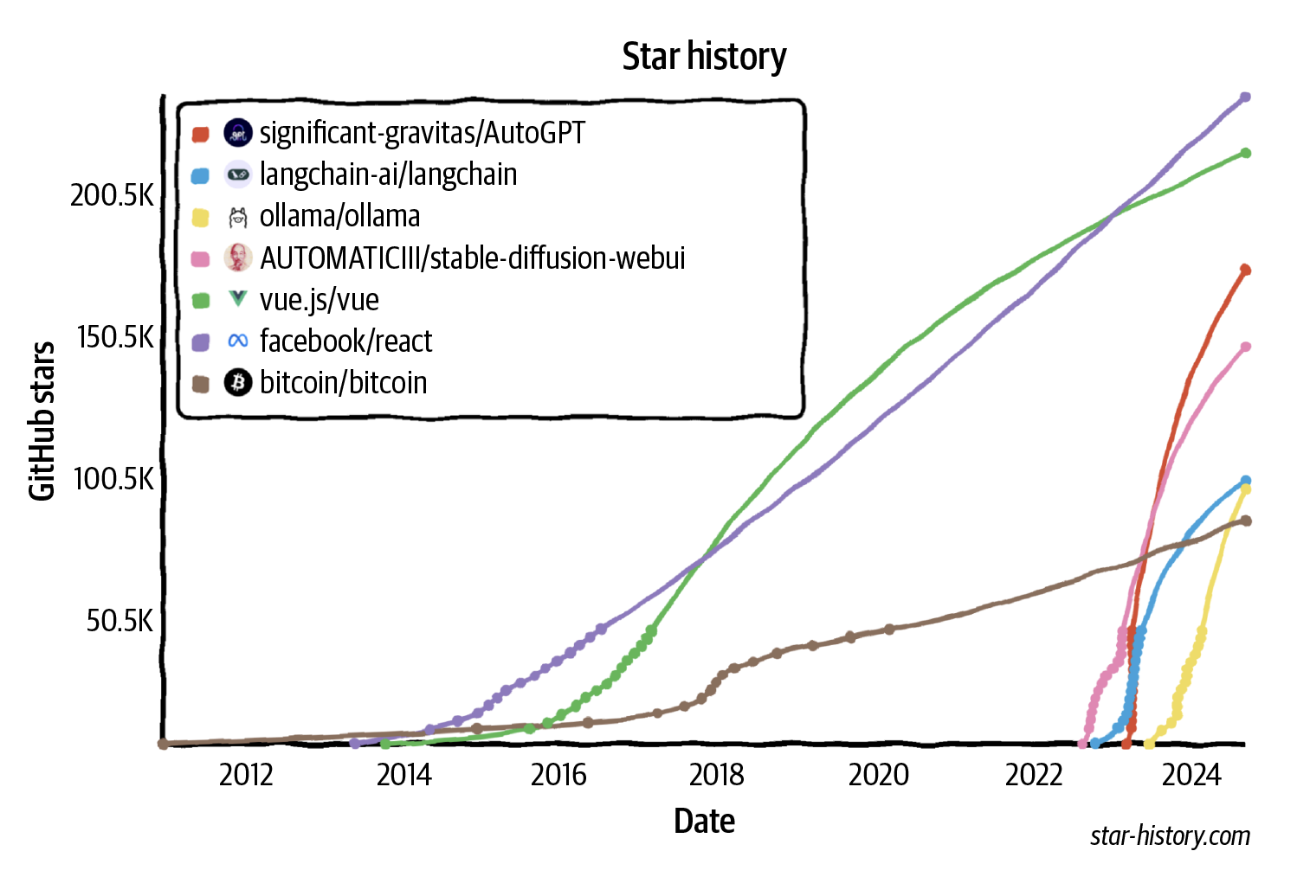
Dunyo bu imkoniyatni tezda qabul qildi. Sun'iy intellekt muhandisligi eng tez, balki eng jadal rivojlanayotgan muhandislik yo'nalishi sifatida maydonga chiqdi. Sun'iy intellekt muhandisligi uchun vositalar avvalgi har qanday dasturiy ta'minot muhandisligi vositalariga qaraganda tezroq ommalashmoqda. Atigi ikki yil ichida to'rtta ochiq manbali SI muhandislik vositasi (AutoGPT, Stable Diffusion web UI, LangChain, Ollama) GitHub'da Bitcoin'dan ko'ra ko'proq yulduzcha to'plab ulgurdi. Ular yulduzchalar soni bo'yicha hatto eng mashhur veb-ishlab chiqish freymvorklari, jumladan React va Vue'ni ham ortda qoldirish arafasida. 1-6-rasmda SI muhandislik vositalarining GitHub yulduzchalari o'sishi Bitcoin, Vue va React bilan taqqoslangan.
LinkedIn'ning 2023-yil avgust oyidagi so'rovnomasi shuni ko'rsatadiki, o'z profiliga “Generativ SI,” “ChatGPT,” “Prompt Muhandisligi,” va “Prompt Yaratish” kabi atamalarni qo'shgan mutaxassislar soni har oy o'rtacha 75% ga oshgan. ComputerWorld esa “SI'ni o'zini tutishga o'rgatish — eng tez o'sayotgan karyera ko'nikmasi” deb e'lon qildi.
Nega aynan “Sun'iy intellekt muhandisligi” atamasi?
Fundamental modellar asosida dasturlar yaratish jarayonini tasvirlash uchun ko'plab atamalar qo'llanilmoqda, jumladan, ML muhandisligi, MLOps, AIOps, LLMOps va hokazo. Xo'sh, nima uchun men bu kitob uchun aynan sun'iy intellekt muhandisligi atamasini tanladim?
Men ML muhandisligi atamasini tanlamadim, chunki “SI muhandisligi va ML muhandisligi farqlari” bo'limida muhokama qilinganidek, fundamental modellar bilan ishlash an'anaviy ML modellari bilan ishlashdan bir nechta muhim jihatlari bilan farq qiladi. ML muhandisligi atamasi bu farqni to'liq ifodalash uchun yetarli bo'lmaydi. Shunday bo'lsa-da, ML muhandisligi ikkala jarayonni ham qamrab oluvchi ajoyib umumiy atamadir.
Men “Ops” bilan tugaydigan atamalarning barchasidan voz kechdim, chunki jarayonda operatsion qismlar mavjud bo'lsa-da, asosiy e'tibor fundamental modellarni siz xohlagandek ishlashi uchun sozlashga (ya'ni, muhandislikka) qaratilgan.
Va nihoyat, men fundamental modellar asosida dasturlar ishlab chiqayotgan 20 kishidan ular o'z faoliyatini qanday atashlari haqida so'rovnoma o'tkazdim. Aksariyati sun'iy intellekt muhandisligi atamasini ma'qul ko'rdi. Men ham ko'pchilikning tanloviga qo'shilishga qaror qildim.
Jadal kengayib borayotgan SI muhandislari hamjamiyati misli ko'rilmagan darajada qiziqarli va xilma-xil dasturlar bilan ajoyib ijodkorlikni namoyon etmoqda. Keyingi bo'limda eng keng tarqalgan dastur andozalaridan (application patterns) ba'zilari ko'rib chiqiladi.
Izohlar
-
Ingliz tilidan boshqa tillarda bitta Unicode belgisi ba'zan bir nechta token sifatida ifodalanishi mumkin. ↩
-
Avtoregressiv til modellari ba'zan sababiy til modellari (
causal language models) deb ham ataladi. ↩ -
Texnik jihatdan, agar juda qattiq harakat qilinsa,
BERTkabi niqoblangan til modelidan ham matn generatsiyasi uchun foydalanish mumkin. ↩ -
Ma'lumotlarni belgilashning haqiqiy narxi bir nechta omillarga, jumladan, vazifaning murakkabligi, miqyosi (kattaroq ma'lumotlar to'plamlari odatda har bir namuna uchun arzonroq narxga olib keladi) va belgilash xizmatini taqdim etuvchi provayderga bog'liq. Masalan, 2024-yil sentabr holatiga ko'ra,
Amazon SageMaker Ground Truth50 000 tadan kam rasmni belgilash uchun har bir rasmga 8 sent, 1 milliondan ortiq rasmni belgilash uchun esa har bir rasmga atigi 2 sent oladi. ↩ -
Bu xuddi insonlar uchun qachon gapirishni to'xtatishni bilish muhim bo'lganiga o'xshaydi. ↩
-
Maktabda menga model parametrlari ham model og'irliklari (weights), ham model siljishlari (biases)ni o'z ichiga oladi deb o'rgatishgan. Biroq, bugungi kunda biz odatda barcha parametrlarni nazarda tutib, model og'irliklari atamasini ishlatamiz. ↩
-
Kattaroq modellarga ko'proq o'qitish ma'lumotlari kerakligi mantiqqa zid tuyulishi mumkin. Agar model qudratliroq bo'lsa, o'rganish uchun kamroq namuna talab qilishi kerak emasmi? Biroq, bizning maqsadimiz katta modelning bir xil ma'lumotlar yordamida kichik modelning samaradorligiga erishishi emas. Bizning maqsadimiz — model samaradorligini maksimal darajaga chiqarishdir. ↩
-
Taqqoslash uchun, AQSHning davlat boshlang'ich va o'rta maktablari uchun umumiy xarajatlari taxminan 900 milliard dollarni tashkil etadi — bu AQSHdagi SI investitsiyalaridan atigi to'qqiz baravar ko'p. ↩