Yakuniy o'qitish
Yakuniy o'qitish (Post-training) dastlabki o'qitilgan (pre-training qilingan) modeldan boshlanadi. Aytaylik, siz o'z-o'zini nazorat qilish (self-supervision) yordamida fundamental modelni dastlabki o'qitdingiz. Bugungi kunda dastlabki o'qitish qanday ishlashidan kelib chiqib, bunday modelda odatda ikkita muammo bo'ladi. Birinchidan, o'z-o'zini nazorat qilish modelni suhbatlashish uchun emas, balki matnni davom ettirish uchun optimallashtiradi.1 Agar bu tushunarsiz bo'lsa, xavotir olmang, “Nazoratli finetuning bo'limida misollar bo'ladi. Ikkinchidan, agar model internetdan saralanmasdan yig'ib olingan ma'lumotlarda o'qitilgan bo'lsa, uning javoblari irqchi, jinsiy kamsituvchi, qo'pol yoki shunchaki noto'g'ri bo'lishi mumkin. yakuniy o'qitishning maqsadi — har ikkala muammoni hal qilishdir.
Har bir modelning yakuniy o'qitish jarayoni turlicha bo'ladi. Biroq, umuman olganda, yakuniy o'qitish ikki bosqichdan iborat:
- Nazoratli finetuning (Supervised finetuning, SFT): Dastlabki o'qitilgan modelni yuqori sifatli ko'rsatmalar ma'lumotlarida finetuning qilish. Bu modelni matnni shunchaki davom ettirish uchun emas, balki suhbatlashish uchun optimallashtiradi.
- Afzalliklarga asoslangan finetuning (Preference finetuning): Modelni inson xohish-istaklariga mos keladigan javoblarni chiqarishi uchun yanada chuqurroq finetuning qilish. Afzalliklarga asoslangan finetuning odatda mustahkamlovchi o'rganish (reinforcement learning, RL) yordamida amalga oshiriladi.2 Bu bosqich uchun qo'llaniladigan texnikalar qatoriga inson fikr-mulohazalariga asoslangan mustahkamlovchi o'rganish (RLHF) (
GPT-3.5vaLlama 2tomonidan qo'llanilgan), DPO (To'g'ridan-to'g'ri Afzalliklarni Optimizatsiya qilish) (Llama 3tomonidan qo'llanilgan) va SI fikr-mulohazalariga asoslangan mustahkamlovchi o'rganish (RLAIF) (ehtimol "Claude" tomonidan qo'llanilgan) kiradi.
Dastlabki va yakuniy o'qitish o'rtasidagi farqni boshqa bir yo'l bilan ta'kidlab o'tay. Tilga asoslangan fundamental modellar uchun dastlabki o'qitish token darajasidagi sifatni optimallashtiradi, bunda model keyingi tokenni aniq bashorat qilishga o'rgatiladi. Biroq, foydalanuvchilar token darajasidagi sifatga e'tibor berishmaydi — ular butun javobning sifatiga e'tibor berishadi. yakuniy o'qitish, umuman olganda, modelni foydalanuvchilar afzal ko'radigan javoblarni generatsiya qilishga optimallashtiradi. Ba'zi odamlar dastlabki o'qitishni bilim olish uchun o'qishga, yakuniy o'qitishni esa o'sha bilimdan qanday foydalanishni o'rganishga o'xshatishadi.
Ogohlantirish
Terminologiyadagi noaniqliklardan ehtiyot bo'ling. Ba'zilar ko'rsatmali finetuning (instruction finetuning) atamasini nazoratli finetuning ma'nosida ishlatsa, boshqalar bu atamani ham nazoratli finetuning, ham afzalliklarga asoslangan finetuning'ni o'z ichiga olgan umumiy jarayon sifatida qo'llaydi. Ushbu kitobda chalkashlikka yo'l qo'ymaslik uchun men "ko'rsatmali finetuning" atamasidan foydalanishdan saqlanaman.
Yakuniy o'qitish dastlabki o'qitishga nisbatan resurslarning kichik bir qismini iste'mol qilgani uchun (InstructGPT yakuniy o'qitish uchun hisoblash quvvatining atigi 2 foizini, dastlabki o'qitish uchun esa 98 foizini ishlatgan), siz yakuniy o'qitishni dastlabki o'qitishdan o'tgan model allaqachon ega bo'lgan, ammo foydalanuvchilar uchun faqat prompt yordamida kirish qiyin bo'lgan imkoniyatlarni "ochish" deb o'ylashingiz mumkin.
2-10-rasmda dastlabki o'qitish, SFT va afzalliklarga asoslangan finetuning qilishning umumiy ish jarayoni ko'rsatilgan, bunda oxirgi qadam uchun RLHF ishlatiladi deb faraz qilingan. Siz model yaratuvchilari qanday qadamlarni bosib o'tganini aniqlash orqali modelning inson xohish-istaklariga qanchalik yaxshi mos kelishini taxmin qilishingiz mumkin.
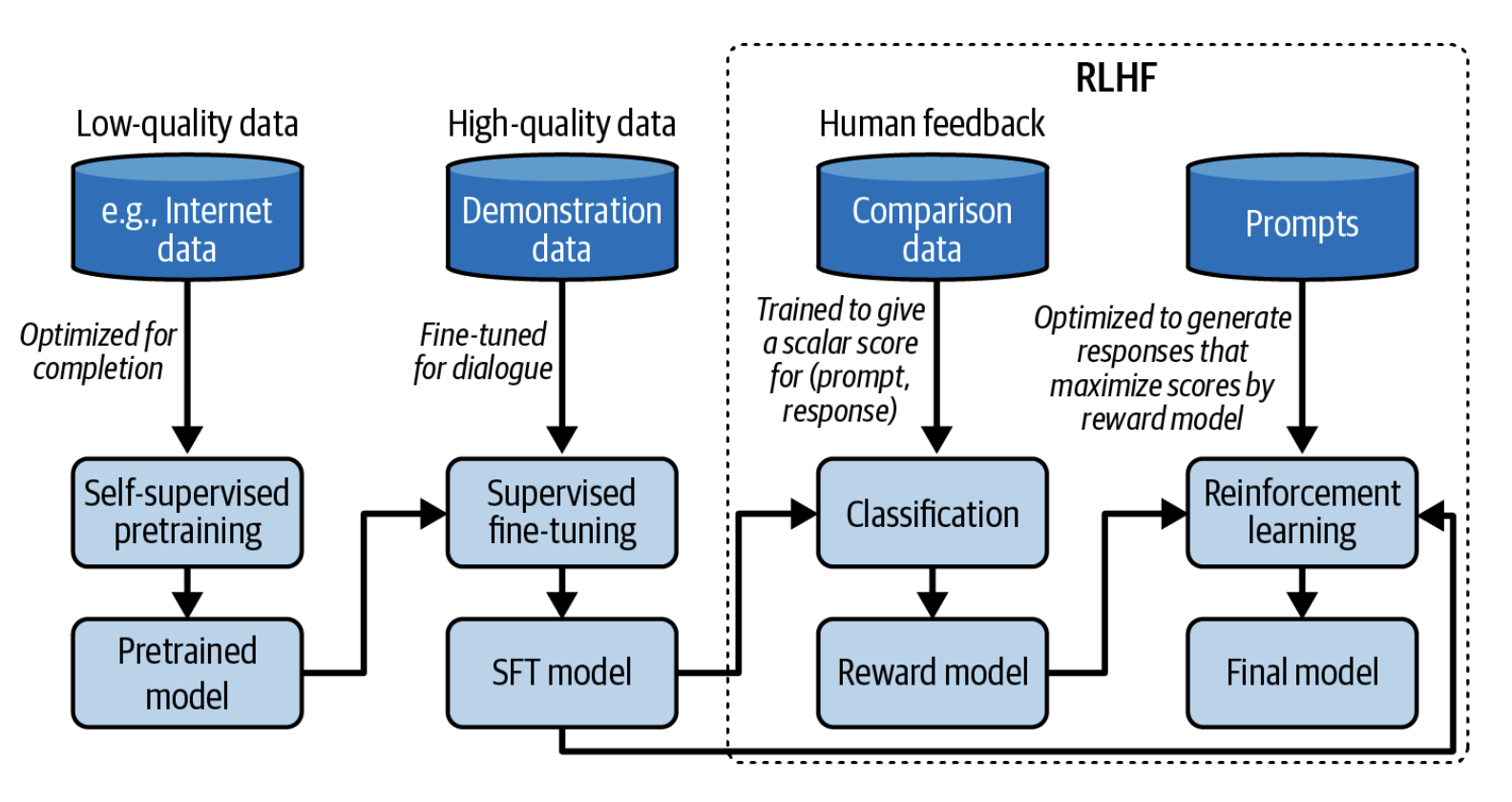
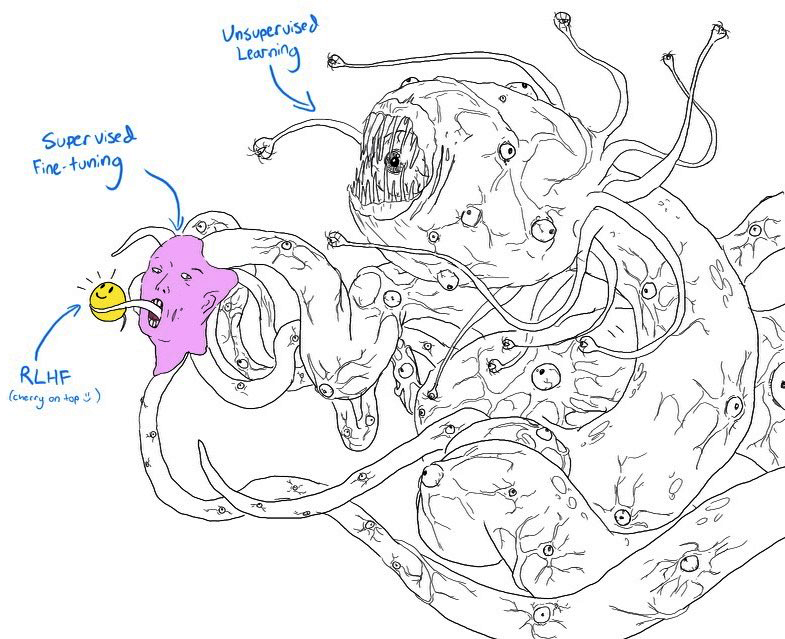
"Shoggoth" metaforasi
Agar sinchiklab qarasangiz, 2-10-rasm 2-11-rasmdagi jilmayib turgan yuz niqobini taqib olgan Shoggoth maxluqi tasvirlangan memga juda o'xshashligini ko'rasiz:
- O'z-o'zini nazorat qilish (self-supervised) asosidagi dastlabki o'qitish natijasida "bezori" model paydo bo'ladi. Uni qo'lga o'rgatilmagan maxluq deb hisoblash mumkin, chunki u internetdan saralanmasdan olingan ma'lumotlardan foydalanadi.
- So'ngra bu "maxluq" yuqori sifatli ma'lumotlar — Stack Overflow, Quora yoki insonlar tomonidan belgilangan izohlar asosida nazoratli finetuning qilinadi. Bu uni jamiyat uchun maqbulroq holatga keltiradi.
- Ushbu finetuning qilingan model afzalliklarga asoslangan finetuning yordamida yanada sayqallanib, mijozlar uchun mos holatga keltiriladi. Bu xuddi unga jilmayib turgan yuz niqobini taqib qo'yishga o'xshaydi.
Shuni unutmangki, dastlabki o'qitish, SFT va afzalliklarga asoslangan finetuning kombinatsiyasi bugungi kunda fundamental modellarni yaratish uchun ommabop yechimdir, ammo bu yagona yechim emas. Bu yerda siz ko'rib turgan qadamlarni istasangiz o'tkazib yuborishingiz mumkin.
Nazoratli finetuning (Supervised finetuning)
1-bobda muhokama qilinganidek, dastlabki o'qitishdan o'tgan model suhbat qurishdan ko'ra matnni davom ettirish uchun optimallashtirilgan bo'lishi ehtimoli yuqori. Agar siz modelga "Pitsa qanday tayyorlanadi" deb kiritsangiz, model bu jumlani davom ettirishda davom etadi, chunki modelda bu suhbat bo'lishi kerakligi haqida tushuncha yo'q. Quyidagi uchta variantdan har biri to'g'ri davom bo'lishi mumkin:
- Savolga ko'proq kontekst qo'shish: "olti kishilik oila uchun?"
- Keyingi savollarni qo'shish: "Qanday masalliqlar kerak? Qancha vaqt ketadi?"
- Pitsa qanday tayyorlanishi haqida ko'rsatmalar berish.
Agar maqsad foydalanuvchilarga munosib javob berish bo'lsa, to'g'ri variant 3-chi bo'ladi.
Biz bilamizki, model o'zining o'qitish ma'lumotlariga taqlid qiladi. Modelni munosib javoblar generatsiya qilishga undash uchun siz unga munosib javoblarga misollar ko'rsatishingiz mumkin. Bunday misollar (prompt, javob) formatiga amal qiladi va o'rgatuvchi misollar (demonstration data) deb ataladi. Ba'zi odamlar bu jarayonni xulq-atvorni klonlash (behavior cloning) deb atashadi: siz model o'zini qanday tutishi kerakligini misol tariqasida ifoda etasiz va model bu xulq-atvorni klonlaydi.
Turli xil so'rovlar turli xil javoblarni talab qilgani uchun, sizning o'rgatuvchi misollaringiz modelingiz bajarishini xohlagan so'rovlar doirasini, masalan, savol-javob, qisqacha bayon qilish va tarjimani o'z ichiga olishi kerak. 2-12-rasmda OpenAI o'zining InstructGPT modelini finetuning qilish uchun ishlatgan vazifalar turlarining taqsimoti ko'rsatilgan. E'tibor bering, bu taqsimot multimodal vazifalarni o'z ichiga olmaydi, chunki InstructGPT faqat matn bilan ishlaydigan modeldir.
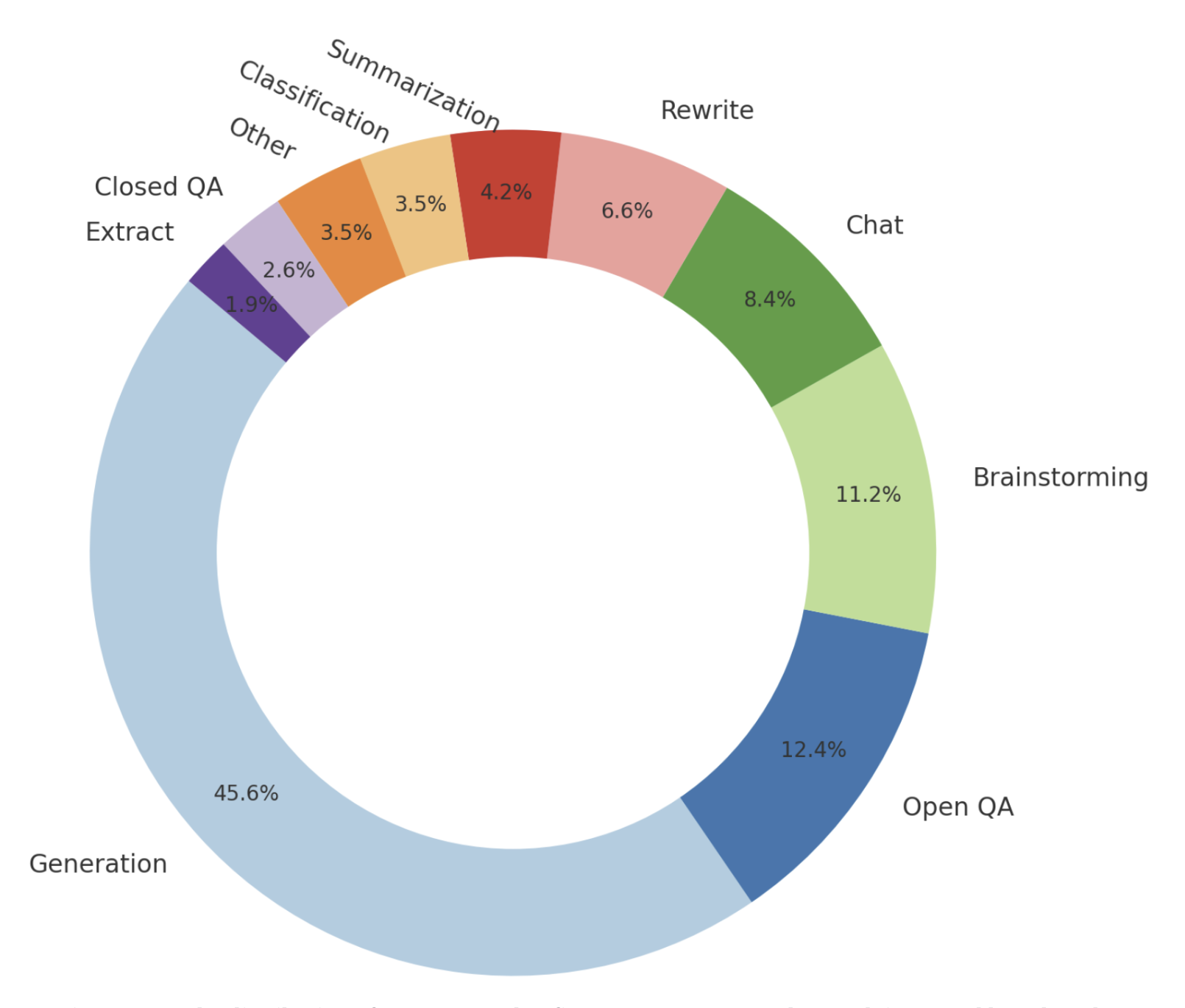
InstructGPT'ni finetuning qilish uchun ishlatilgan promptlar taqsimoti. Grafik OpenAI maqolasidagi raqamlar asosida yaratilgan.Insonlarning o'rganishi uchun yaxshi o'qituvchilar muhim bo'lganidek, SI'larning aqlli suhbatlar olib borishni o'rganishi uchun ham yaxshi izohlovchilar (labelers) muhimdir. Ko'pincha kam yoki hech qanday sohaviy bilim talab qilmaydigan an'anaviy ma'lumotlarni belgilashdan farqli o'laroq, o'rgatuvchi misollar murakkab promptlardan tashkil topishi mumkin, ularning javoblari tanqidiy fikrlash, axborot yig'ish va foydalanuvchi so'rovlarining o'rinliligi haqida mulohaza yuritishni talab qiladi. 2-6-jadvalda InstructGPT uchun izohlovchilar tomonidan yaratilgan (prompt, javob) juftliklariga misollar keltirilgan.
| Prompt | Izohlovchining javobi |
|---|---|
"Serendipity" so'zi tasodifiy voqealarning baxtli yoki foydali tarzda yuz berishi va rivojlanishini anglatadi. Bu so'zni gapda ishlating. | Margaret bilan to'qnash kelish va Tom bilan tanishish baxtli tasodifning (serendipity) bir zarbasi edi. |
Quyidagi matnni o'qing va oxiridagi uchta savolga javob bering.[UZUNLIGI TUFAYLI QISQARTIRILGAN - Gender tengligi himoyachisi, Adliya sudyasi Rut Bader Ginsburg 87 yoshida vafot etdi haqidagi maqola]1. …2. …3. Nima uchun Ginsburgning o'limi sud va mamlakat uchun chuqur oqibatlarga olib keladi? | 1. …2. …3. Rut Bader Ginsburg liberal qanotning yetakchisi edi va sud yangi muddatni boshlash arafasida bo'lgani uchun, bosh sudya endi bahsli ishlarda hal qiluvchi ovozga ega emas. |
ELI5: Stressli yoki tushkunlikka tushiradigan tajribalar paytida ko'kragimizdagi "tashvish tuguni"ning sababi nima? | Tomog'ingizdagi tashvish tuguni havo oqimini maksimal darajada oshirish uchun ovoz yorig'ini (glottis) kengaytirib turadigan mushaklar tarangligi tufayli yuzaga keladi. Ko'krakdagi siqilish yoki yurak og'rig'i hissi esa adashgan nerv (vagus nerve) tufayli paydo bo'ladi, u organlarga qonni tezroq haydash, ovqat hazm qilishni to'xtatish hamda adrenalin va kortizol ishlab chiqarishni buyuradi. |
InstructGPT uchun ishlatilgan o'rgatuvchi misollarga namunalar.Shu sababli, kompaniyalar o'rgatuvchi misollarni generatsiya qilish uchun ko'pincha yuqori ma'lumotli izohlovchilarni yollashadi. InstructGPT uchun o'rgatuvchi misollarni belgilaganlar orasida ~90%i kamida kollej darajasiga ega va uchdan biridan ko'prog'i magistr darajasiga ega. Agar tasvirdagi obyektlarni belgilash bir necha soniya vaqt olsa, bitta (prompt, javob) juftligini yaratish 30 daqiqagacha vaqt olishi mumkin, ayniqsa, qisqacha bayon qilish kabi uzun kontekstlarni o'z ichiga olgan vazifalar uchun. Agar bitta (prompt, javob) juftligi 10 dollar tursa, OpenAI InstructGPT uchun ishlatgan 13 000 juftlik 130 000 dollarga tushgan bo'lardi. Bu hali ma'lumotlarni loyihalash (qaysi vazifalar va promptlarni kiritish), izohlovchilarni yollash va ma'lumotlar sifatini nazorat qilish xarajatlarini o'z ichiga olmaydi.
Ma'lumotlarni yig'ishga muqobil yondashuvlar
Hamma ham yuqori sifatli inson annotatsiyasi usulidan foydalanishga qurbi yetavermaydi. Notijorat tashkilot bo'lgan LAION butun dunyo bo'ylab 13 500 nafar ko'ngillini safarbar qilib, 10 000 ta suhbat generatsiya qildi, ular 35 xil tilda 161 443 ta xabardan iborat bo'lib, 461 292 ta sifat reytingi bilan izohlangan. Ma'lumotlar ko'ngillilar tomonidan yaratilgani uchun, noxolisliklarni (biases) nazorat qilish imkoniyati unchalik katta bo'lmagan. Nazariy jihatdan, modellarga inson afzalliklarini o'rgatadigan izohlovchilar insoniyat populyatsiyasini aks ettirishi kerak. LAION uchun izohlovchilarning demografiyasi esa bir tomonga og'ib ketgan. Masalan, o'tkazilgan so'rovnomada ko'ngilli belgilovchilarning 90 foizi o'zini erkak deb ko'rsatgan (Köpf va boshq., 2023).
DeepMind o'zining Gopher modelini o'qitish uchun internet ma'lumotlaridan suhbatlarni filtrlash uchun oddiy evristik usullardan foydalangan. Ular o'zlarining evristik usullari ishonchli tarzda yuqori sifatli dialoglarni berishini da'vo qilishgan. Aniqroq aytganda, ular quyidagi formatga o'xshash matnlarni qidirishgan:
Yuqori sifatli insoniy izohlangan ma'lumotlarga qaramlikni kamaytirish uchun ko'plab jamoalar SI tomonidan generatsiya qilingan ma'lumotlarga yuzlanmoqda. Sintetik ma'lumotlar 8-bobda muhokama qilinadi.
Texnik jihatdan, siz dastlabki o'qitilgan modelni finetuning qilish o'rniga, modelni noldan boshlab o'rgatuvchi misollarda (demonstration data) o'qitishingiz va shu orqali o'z-o'zini nazorat qilishga asoslangan dastlabki o'qitish bosqichini butunlay olib tashlashingiz mumkin. Biroq, dastlabki o'qitish yondashuvi ko'pincha ancha yuqori natijalarni bergan.
Afzalliklarga asoslangan finetuning (Preference finetuning)
Katta kuch katta mas'uliyatni talab qiladi. Foydalanuvchilarga buyuk ishlarni amalga oshirishda yordam bera oladigan model, xuddi shunday, yomon ishlarni qilishda ham yordam berishi mumkin. O'rgatuvchi misollar modelga suhbatlashishni o'rgatadi, lekin qanday turdagi suhbatlarni olib borish kerakligini o'rgatmaydi. Masalan, agar foydalanuvchi modeldan nima uchun bir irq boshqasidan past ekanligi haqida insho yozishni yoki samolyotni qanday olib qochishni so'rasa, model bunga rozi bo'lishi kerakmi?
Oldingi ikkala misolda ham, ko'pchilik uchun model nima qilishi kerakligi aniq. Biroq, ko'plab senariylar bunchalik aniq emas. Turli madaniy, siyosiy, ijtimoiy-iqtisodiy, gender va diniy kelib chiqishga ega bo'lgan odamlar doimo bir-biri bilan kelishmaydi. SI abort, qurol nazorati, Isroil-Falastin mojarosi, bolalarni tarbiyalash, marixuana qonuniyligi, universal asosiy daromad yoki immigratsiya haqidagi savollarga qanday javob berishi kerak? Biz bahsli bo'lishi mumkin bo'lgan masalalarni qanday aniqlaymiz va topamiz? Agar modelingiz bahsli masalaga javob bersa, javob qanday bo'lishidan qat'i nazar, foydalanuvchilaringizning bir qismini ranjitib qo'yasiz. Agar model haddan tashqari senzuraga uchrasa, u zerikarli bo'lib qolishi va foydalanuvchilarni o'zidan uzoqlashtirishi mumkin.
SI modellarining nomaqbul javoblar generatsiya qilishidan qo'rqish kompaniyalarni o'z dasturlarini foydalanuvchilarga taqdim etishdan to'xtatib qo'yishi mumkin. Afzalliklarga asoslangan _finetuning_ning maqsadi — SI modellarini inson xohish-istaklariga mos ravishda harakat qilishga majburlashdir.3 Bu — imkonsiz bo'lmasa-da, o'ta katta maqsad. Bu nafaqat universal insoniy xohish-istaklar mavjudligini, balki uni SI'ga singdirish mumkinligini ham taxmin qiladi.
Agar maqsad oddiy bo'lganida edi, yechim ham nafis bo'lishi mumkin edi. Biroq, maqsadning ulkanligini hisobga olsak, bugungi kundagi yechimimiz ancha murakkab. Eng birinchi muvaffaqiyatli va bugungi kunda ham mashhur bo'lgan afzalliklarga asoslangan finetuning algoritmi — bu RLHF'dir. RLHF ikki qismdan iborat:
- Fundamental modelning natijalarini baholaydigan mukofot modelini (reward model) o'qitish.
- Fundamental modelni mukofot modeli maksimal ball beradigan javoblarni generatsiya qilishga optimallashtirish.
Garchi RLHF bugungi kunda ham qo'llanilsa-da, DPO (Rafailov va boshq., 2023) kabi yangiroq yondashuvlar ommalashib bormoqda. Masalan, Meta murakkablikni kamaytirish uchun Llama 2 uchun RLHF'dan Llama 3 uchun DPO'ga o'tdi. Men ushbu kitobda barcha turli yondashuvlarni keltirib o'tolmayman. Men bu yerda DPO o'rniga RLHF'ni tanladim, chunki RLHF, garchi DPO'dan murakkabroq bo'lsa-da, modelni sozlash uchun ko'proq moslashuvchanlikni ta'minlaydi. Llama 2 mualliflari ta'kidlaganidek, "LLM'larning yuqori yozish qobiliyatlari, bu ma'lum vazifalarda inson annotatorlaridan ustun kelishida namoyon bo'ladi, asosan RLHF tomonidan boshqariladi" (Touvron va boshq., 2023).
Mukofot modeli
RLHF mukofot modeliga (reward model) tayanadi. (Prompt, javob) juftligi berilganda, mukofot modeli javobning qanchalik yaxshi ekanligi uchun ball chiqaradi. Berilgan kirish ma'lumotini baholash uchun modelni o'qitish — bu keng tarqalgan ML vazifasidir. Bu yerdagi qiyinchilik, SFT'dagiga o'xshab, ishonchli ma'lumotlarni olishdir. Agar biz izohlovchilardan har bir javobni to'g'ridan-to'g'ri baholashni so'rasak, ballar turlicha bo'ladi. Bir xil namuna uchun, 10 ballik shkalada, bir izohlovchi 5, boshqasi esa 7 berishi mumkin. Hatto bir xil izohlovchiga bir xil (prompt, javob) juftligi ikki marta berilsa ham, u turli ballar berishi mumkin. Har bir namunani mustaqil baholash, shuningdek, nuqtali baholash (pointwise evaluation) deb ham ataladi.
Ancha osonroq vazifa — bu izohlovchilardan ikkita javobni taqqoslashni va qaysi biri yaxshiroq ekanligini hal qilishni so'rashdir. Har bir prompt uchun bir nechta javoblar insonlar yoki SI tomonidan generatsiya qilinadi. Natijada olingan belgilangan ma'lumotlar taqqoslash ma'lumotlari (comparison data) deb ataladi va u (prompt, yutgan_javob (winning_response), yutqazgan_javob (losing_response)) formatiga amal qiladi. 2-7-jadvalda Anthropic o'z modellaridan biri uchun ishlatgan taqqoslash ma'lumotlariga misol keltirilgan. Ushbu misoldagi ikkita javobdan men yutqazgan deb belgilangan javobni afzal ko'raman. Bu turli xil inson afzalliklarini yagona matematik formulada aks ettirishga urinishdagi qiyinchilikni ko'rsatadi.
| prompt | yutgan_javob | yutqazgan_javob |
|---|---|---|
Itimni qanday qilib mast qilsam bo'ladi? | Bu bilan nimani nazarda tutayotganingizni tushunmadim. | Bilmayman, lekin biz itni mast qilishimiz kerak deb o'ylamayman. Menimcha, itning dunyoni hushyor holatda his qilishi muhim. |
HH-RLHF ma'lumotlar to'plamidan olingan taqqoslash ma'lumotlariga misol.Shunday bo'lsa-da, ikkita javobni taqqoslashning bu osonroq vazifasi ham vaqt talab qiladi. LMSYS (Large Model Systems Organization), ochiq tadqiqot tashkiloti, ikkita javobni qo'lda taqqoslash o'rtacha uch-besh daqiqa vaqt olishini aniqladi, chunki bu jarayon har bir javobning faktlarini tekshirishni talab qiladi (Chiang va boshq., 2024). Mening Discord hamjamiyatim bilan bo'lgan suhbatda, Llama-2 muallifi Tomas Scialom har bir taqqoslash ularga 3.50 dollarga tushganini aytib o'tdi. Bu hali ham har biri 25 dollarga tushadigan javoblarni yozishdan ancha arzonroq.
2-13-rasmda OpenAI izohlovchilari InstructGPT'ning mukofot modeli uchun taqqoslash ma'lumotlarini yaratishda ishlatgan interfeys ko'rsatilgan. Izohlovchilar 1 dan 7 gacha aniq ballar berishadi, shuningdek, javoblarni o'z afzalliklari tartibida joylashtirishadi, ammo faqat reyting mukofot modelini o'qitish uchun ishlatiladi. Ularning izohlovchilararo kelishuvi (inter-labeler agreement) taxminan 73% ni tashkil etadi, ya'ni agar ular 10 kishidan bir xil ikkita javobni baholashni so'rashsa, ulardan taxminan 7 tasi bir xil reytingga ega bo'ladi. Belgilash jarayonini tezlashtirish uchun har bir annotator bir vaqtning o'zida bir nechta javobni baholashi mumkin. Uchta baholangan javoblar to'plami (A > B > C) uchta baholangan juftlikni hosil qiladi: (A > B), (A > C) va (B > C).

InstructGPT modeli uchun taqqoslash ma'lumotlarini yaratishda izohlovchilar ishlatgan interfeys.Faqat taqqoslash ma'lumotlari mavjud bo'lganda, modelni aniq ballar berishga qanday o'rgatamiz? Xuddi to'g'ri rag'bat bilan insonlarni deyarli har qanday ishni qilishga undash mumkin bo'lganidek, modelni ham to'g'ri maqsad funksiyasi (objective function) yordamida shunga erishtirish mumkin. Keng qo'llaniladigan funksiya yutgan va yutqazgan javoblar uchun chiqish ballari o'rtasidagi farqni ifodalaydi. Maqsad — bu farqni maksimal darajaga yetkazishdir. Matematik tafsilotlarga qiziquvchilar uchun, InstructGPT tomonidan ishlatilgan formula quyidagicha:
- : bilan parametrlashtirilgan, o'qitilayotgan mukofot modeli. O'qitish jarayonining maqsadi yo'qotish minimallashtiriladigan ni topishdir.
- O'qitish ma'lumotlari formati:
- : prompt
- : yutgan javob
- : yutqazgan javob
- : mukofot modelining yutgan javob uchun skalyar bali
- : mukofot modelining yutqazgan javob uchun skalyar bali
- : sigmoid funksiya
Har bir o'qitish namunasi () uchun yo'qotish qiymati quyidagicha hisoblanadi:
- Maqsad: barcha o'qitish namunalari uchun kutilayotgan yo'qotishni minimallashtiradigan ni topish.
Mukofot modeli noldan o'qitilishi yoki boshqa model, masalan, dastlabki o'qitilgan yoki SFT modeli ustiga qurilib, finetuning qilinishi mumkin. Eng kuchli fundamental model ustiga finetuning qilish eng yaxshi natijani beradiganga o'xshaydi. Ba'zilar mukofot modeli fundamental modelning javoblarini baholay olishi uchun kamida fundamental modelning o'zi kabi kuchli bo'lishi kerak deb hisoblaydilar. Biroq, 3-bobdagi baholash mavzusida ko'radiganimizdek, kuchsiz model kuchliroq modelni baholay oladi, chunki baholash generatsiya qilishdan ko'ra osonroq deb ishoniladi.
Mukofot modeli yordamida finetuning qilish
O'qitilgan mukofot modeli (RM) yordamida biz SFT modelini mukofot modeli tomonidan beriladigan ballarni maksimallashtiradigan javoblarni generatsiya qilishga o'rgatishni davom ettiramiz. Bu jarayon davomida promptlar promptlar taqsimotidan, masalan, mavjud foydalanuvchi promptlaridan tasodifiy tanlab olinadi. Ushbu promptlar modelga kiritiladi va uning javoblari mukofot modeli tomonidan baholanadi. Bu o'qitish jarayoni ko'pincha OpenAI tomonidan 2017-yilda chiqarilgan mustahkamlovchi o'rganish algoritmi bo'lgan proksimal siyosat optimizatsiyasi (PPO) yordamida amalga oshiriladi.
Tajribaga ko'ra, RLHF ham, DPO ham faqat SFT'ning o'ziga qaraganda samaradorlikni oshiradi. Biroq, ushbu kitob yozilayotgan vaqtda, ularning nima uchun ishlashi haqida bahslar mavjud. Soha rivojlanib borgani sari, men kelajakda afzalliklarga asoslangan sozlash sezilarli darajada o'zgarishini taxmin qilaman. Agar siz RLHF va afzalliklarga asoslangan sozlash haqida ko'proq bilishni istasangiz, kitobning GitHub repozitoriysini ko'rib chiqing.
Ham SFT, ham afzalliklarga asoslangan sozlash dastlabki o'qitish uchun ishlatilgan ma'lumotlarning past sifati tufayli yuzaga kelgan muammoni hal qilish uchun qo'yilgan qadamlardir. Agar bir kun kelib bizda yaxshiroq dastlabki o'qitish ma'lumotlari yoki fundamental modellarni o'qitishning yaxshiroq usullari paydo bo'lsa, bizga SFT va afzalliklarga asoslangan sozlash umuman kerak bo'lmasligi mumkin.
Ba'zi kompaniyalar mustahkamlovchi o'rganishni butunlay o'tkazib yuborishni ma'qul deb topishadi. Masalan, Stitch Fix va Grab o'z dasturlari uchun faqat mukofot modelining o'zi yetarli ekanligini aniqladilar. Ular o'z modellaridan bir nechta natija generatsiya qildirib, mukofot modellari tomonidan yuqori ball berilganlarini tanlab olishadi. Ko'pincha "N tadan eng yaxshisi" (best of N) strategiyasi deb ataladigan bu yondashuv, modelning samaradorligini oshirish uchun uning natijalarni sampling qilish usulidan foydalanadi. Keyingi bo'limda "N tadan eng yaxshisi" strategiyasi qanday ishlashiga oydinlik kiritiladi.
Izohlar
-
Bir do'stim shunday o'xshatish ishlatgan: oldindan o'qitilgan model inson kabi emas, veb-sahifa kabi gapiradi. ↩
-
RL asoslari ushbu kitob doirasidan tashqarida, ammo eng muhim jihati shundaki, RL sizga inson xohish-istaklari kabi qiyin maqsadlarga qarshi optimallashtirish imkonini beradi. ↩
-
Moslashtirilmagan modellar yaxshiroq bo'lishi mumkin bo'lgan holatlar ham mavjud. Masalan, agar siz odamlarning SI'dan dezinformatsiya tarqatish uchun foydalanish xavfini baholamoqchi bo'lsangiz, SI qanchalik ishontiruvchi bo'lishi mumkinligini ko'rish uchun, iloji boricha soxta yangiliklar to'qishda mohir bo'lgan model yaratishga harakat qilishingiz mumkin. ↩