O'qitish ma'lumotlari
SI modelining sifati u o'qitilgan ma'lumotlarning sifatidan oshmaydi. Agar o'qitish ma'lumotlarida vyetnam tili bo'lmasa, model ingliz tilidan vyetnam tiliga tarjima qila olmaydi. Xuddi shunday, agar tasvir tasnifi modeli o'zining o'qitish to'plamida faqat hayvonlarni ko'rsa, u o'simliklar suratlari bilan yaxshi ishlay olmaydi.
Agar siz modelning biror vazifani yaxshiroq bajarishini istasangiz, o'qitish ma'lumotlariga o'sha vazifa uchun ko'proq ma'lumot qo'shishingiz kerak bo'ladi. Biroq, katta modelni o'qitish uchun yetarli ma'lumot to'plash oson emas va bu qimmatga tushishi mumkin. Model yaratuvchilari ko'pincha mavjud ma'lumotlarga tayanishlariga to'g'ri keladi, hatto bu ma'lumotlar ularning ehtiyojlariga to'liq javob bermasa ham.
O'qitish ma'lumotlarining umumiy manbalari
Masalan, o'qitish ma'lumotlari uchun keng tarqalgan manbalardan biri bu Common Crawl bo'lib, u internetdagi veb-saytlarni vaqti-vaqti bilan skanerlaydigan (crawls) notijorat tashkilot tomonidan yaratilgan. 2022 va 2023-yillarda ushbu tashkilot har oy taxminan 2-3 milliard veb-sahifani skanerlagan. Google kompaniyasi Common Crawl'ning tozalangan quyi to'plamini taqdim etadi va u Colossal Clean Crawled Corpus yoki qisqacha C4 deb ataladi.
Common Crawl va ma'lum darajada C4'ning ma'lumotlar sifati shubhali — klikbeyt, dezinformatsiya, propaganda, fitna nazariyalari, irqchilik, misoginiya (ayollarni kamsitish) va siz internetda ko'rgan yoki chetlab o'tgan har qanday shubhali veb-sayt bo'lishi mumkin. Washington Post tadqiqoti shuni ko'rsatdiki, ma'lumotlar to'plamidagi eng keng tarqalgan 1000 ta veb-sayt orasida NewsGuard'ning ishonchlilik shkalasi bo'yicha past o'rinlarda turadigan bir nechta ommaviy axborot vositalari ham bor. Oddiy qilib aytganda, Common Crawl'da soxta yangiliklar juda ko'p.
Shunga qaramay, Common Crawl mavjud bo'lgani uchungina, uning turli variantlari o'zlarining o'qitish ma'lumotlari manbalarini oshkor qiladigan aksariyat fundamental modellarda, jumladan, OpenAI'ning GPT-3 va Google'ning Gemini modellarida ishlatiladi. Taxminimcha, Common Crawl o'z o'qitish ma'lumotlarini oshkor qilmaydigan modellarda ham ishlatiladi. Ham jamoatchilik, ham raqobatchilar tomonidan tanqid qilinishdan qochish uchun ko'plab kompaniyalar bu ma'lumotni oshkor qilishni to'xtatgan.
Ba'zi jamoalar internetdan past sifatli ma'lumotlarni filtrlash uchun evristik qoidalardan foydalanadilar. Masalan, OpenAI GPT-2ni o'qitish uchun faqat kamida uchta ijobiy ovoz (upvotes) olgan Reddit havolalaridan foydalangan. Garchi bu hech kimni qiziqtirmaydigan havolalarni saralashga yordam bersa-da, Reddit ham aynan odob-axloq va yuksak didning cho'qqisi emas.
"Xohlaganimizni emas, borini ishlatamiz" yondashuvi o'qitish ma'lumotlarida mavjud bo'lgan vazifalarni yaxshi bajaradigan, lekin siz uchun muhim bo'lgan vazifalarni unchalik yaxshi bajara olmaydigan modellarning paydo bo'lishiga olib kelishi mumkin. Bu muammoni hal qilish uchun sizning aniq ehtiyojlaringizga mos keladigan ma'lumotlar to'plamlarini saralash (curate) juda muhimdir. Ushbu bo'lim muayyan tillar va sohalar uchun ma'lumotlarni saralashga qaratilgan bo'lib, u o'sha sohalardagi ilovalar uchun keng qamrovli, ammo ixtisoslashgan poydevorni ta'minlaydi. 8-bobda esa o'ta tor doiradagi vazifalarga moslashtirilgan modellar uchun ma'lumotlar strategiyalari ko'rib chiqiladi.
Garchi til va sohaga xos fundamental modellarni noldan o'qitish mumkin bo'lsa-da, ularni umumiy maqsadli modellar ustida finetuning qilish ham keng tarqalgan amaliyotdir.
Umumiy va maxsus ma'lumotlar balansi
Ba'zilar: "Nega model hamma narsani qila olishi uchun uni shunchaki mavjud bo'lgan barcha ma'lumotlarda — ham umumiy, ham ixtisoslashgan ma'lumotlarda o'qitib qo'ya qolmaymiz?" deb o'ylashi mumkin. Ko'pchilik aynan shunday qiladi ham. Biroq, ko'proq ma'lumotda o'qitish ko'pincha ko'proq hisoblash resurslarini talab qiladi va bu har doim ham yaxshiroq natijaga olib kelavermaydi. Masalan, kamroq miqdordagi yuqori sifatli ma'lumotlarda o'qitilgan model ko'p miqdordagi past sifatli ma'lumotlarda o'qitilgan modeldan ustun kelishi mumkin. Gunasekar va boshqalar (2023) 7 milliard tokenli yuqori sifatli kodlash ma'lumotlaridan foydalanib, bir nechta muhim kodlash benchmarklarida o'zidan ancha katta modellardan ustun keladigan 1,3 milliard parametrli modelni o'qitishga muvaffaq bo'lishdi. Ma'lumotlar sifatining ta'siri 8-bobda batafsilroq muhokama qilinadi.
Ko'p tilli modellar
Internetda ingliz tili hukmronlik qiladi. Common Crawl ma'lumotlar to'plamining tahlili shuni ko'rsatadiki, ma'lumotlarning deyarli yarmi (45.88%) ingliz tiliga to'g'ri keladi, bu esa uni ikkinchi eng keng tarqalgan til — rus tilidan (5.97%) sakkiz baravar ko'proq tarqalganiga dalolat qiladi (Lai va boshq., 2023). Common Crawl'da kamida 1% ulushga ega bo'lgan tillar ro'yxati uchun 2-1-jadvalga qarang. O'qitish ma'lumotlari sifatida cheklangan miqdorda mavjud bo'lgan tillar — odatda bu ro'yxatga kiritilmagan tillar — kam resursli (low-resource) hisoblanadi.
| Til | Kod | Aholi soni (M) | CC hajmi (%) | Kat. |
|---|---|---|---|---|
| Ingliz tili | en | 1,452 | 45.8786 | H |
| Rus tili | ru | 258 | 5.9692 | H |
| Nemis tili | de | 134 | 5.8811 | H |
| Xitoy tili | zh | 1,118 | 4.8747 | H |
| Yapon tili | jp | 125 | 4.7884 | H |
| Fransuz tili | fr | 274 | 4.7254 | H |
| Ispan tili | es | 548 | 4.4690 | H |
| Italyan tili | it | 68 | 2.5712 | H |
| Golland tili | nl | 30 | 2.0585 | H |
| Polyak tili | pl | 45 | 1.6636 | H |
| Portugal tili | pt | 257 | 1.1505 | H |
| Vyetnam tili | vi | 85 | 1.0299 | H |
Boshqa ko'plab tillar, garchi bugungi kunda so'zlashuvchilar soni ko'p bo'lsa-da, Common Crawl'da juda kam ifodalangan. 2-2-jadvalda ushbu tillarning ba'zilari ko'rsatilgan. Ideal holda, dunyo aholisidagi ulush va Common Crawl'dagi ulush o'rtasidagi nisbat 1 bo'lishi kerak. Bu nisbat qanchalik yuqori bo'lsa, bu til Common Crawl'da shunchalik kam ifodalangan bo'ladi.
| Til | So'zlashuvchilar (million) | Dunyo aholisidagi 1 | Common Crawl'dagi % | Dunyo : Common Crawl nisbati |
|---|---|---|---|---|
| Panjob tili | 113 | 1.41% | 0.0061% | 231.56 |
| Suaxili tili | 71 | 0.89% | 0.0077% | 115.26 |
| Urdu tili | 231 | 2.89% | 0.0274% | 105.38 |
| Kannada tili | 64 | 0.80% | 0.0122% | 65.57 |
| Telugu tili | 95 | 1.19% | 0.0183% | 64.89 |
| Gujarati tili | 62 | 0.78% | 0.0126% | 61.51 |
| Maratxi tili | 99 | 1.24% | 0.0213% | 58.10 |
| Bengal tili | 272 | 3.40% | 0.0930% | 36.56 |
| Ingliz tili | 1452 | 18.15% | 45.88% | 0.40 |
Internet ma'lumotlarida ingliz tilining hukmronligini hisobga olsak, ko'plab tadqiqotlarga ko'ra, umumiy maqsadli modellarning boshqa tillarga qaraganda ingliz tilida ancha yaxshiroq ishlashi ajablanarli emas. Masalan, 57 ta fanni qamrab olgan 14 000 ta ko'p tanlovli masalalardan iborat MMLU benchmarkida GPT-4 telugu kabi kam ifodalangan tillarga qaraganda ingliz tilida ancha yaxshiroq natija ko'rsatgan (2-1-rasm) (OpenAI, 2023).
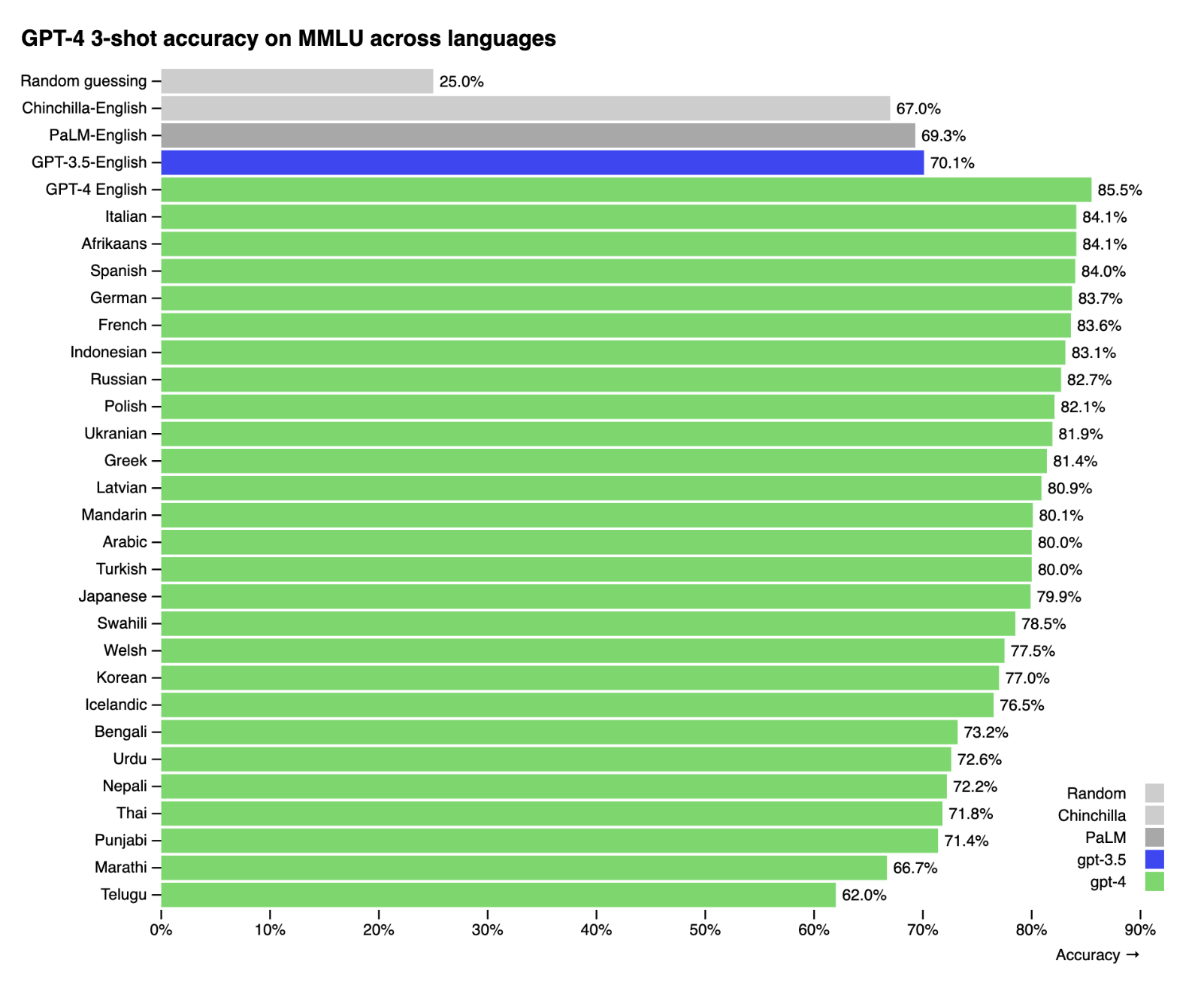
GPT-4 boshqa har qanday tilga qaraganda ingliz tilida yaxshiroq ishlaydi. Boshqa tillardagi MMLU testini olish uchun OpenAI savollarni "Azure AI Translator" yordamida tarjima qilgan.Xuddi shunday, "Project Euler"dagi oltita matematik masala bo'yicha sinovdan o'tkazilganda, Yennie Jun GPT-4'ning ingliz tilidagi masalalarni arman yoki fors tillariga qaraganda uch baravardan ko'proq yecha olganini aniqladi.2 GPT-4 birma va amxar tillaridagi barcha oltita savolda muvaffaqiyatsizlikka uchradi (2-2-rasm).
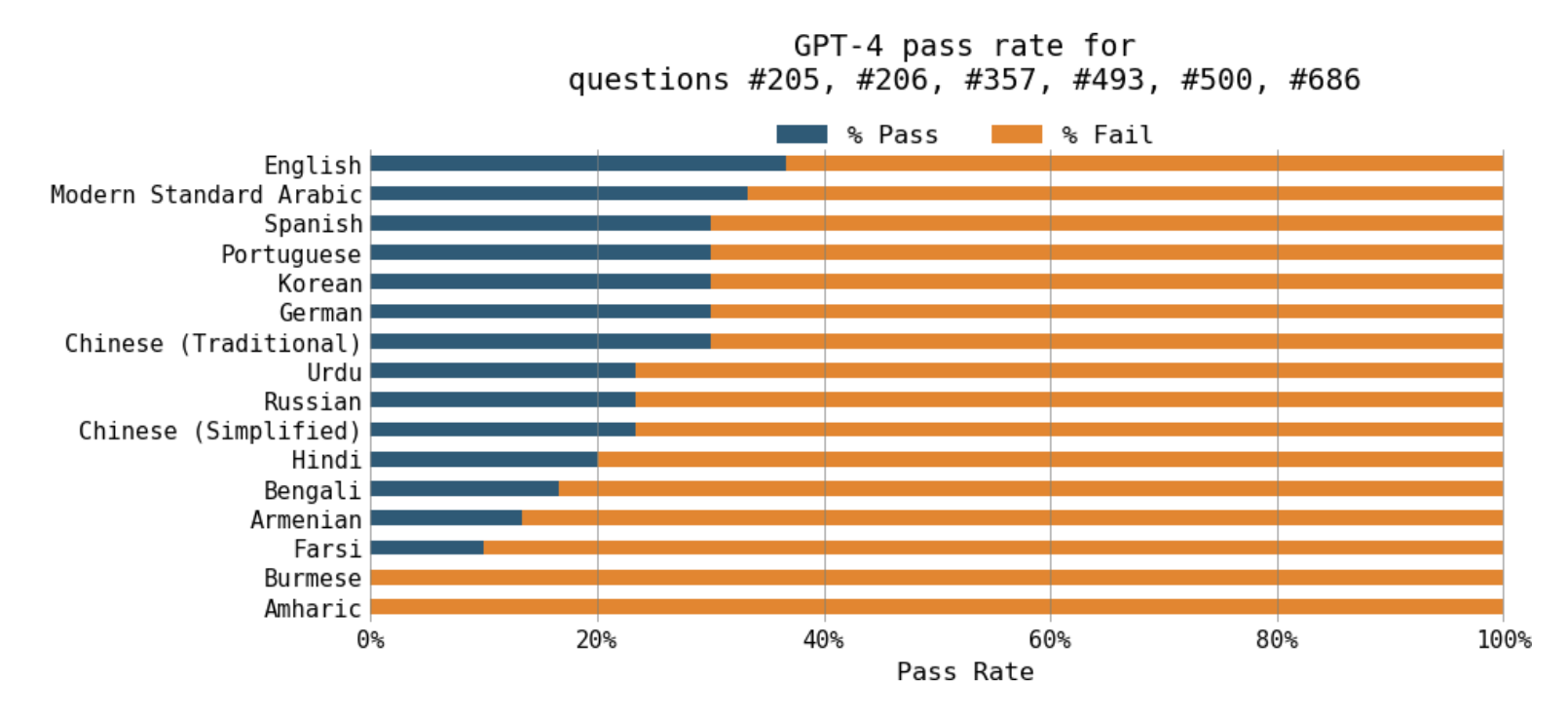
GPT-4 matematikada boshqa tillarga qaraganda ingliz tilida ancha yaxshiroq.Kamchilik sabablari va yechimlari
Kam ifodalanganlik bu past samaradorlikning asosiy sababidir. GPT-4'ning MMLU benchmarklarida eng yomon natijalarni ko'rsatgan uchta til — telugu, maratxi va panjob — ayni paytda Common Crawl'da eng kam ifodalangan tillar qatoriga kiradi. Biroq, kam ifodalanganlik yagona sabab emas. Tilning tuzilishi va u o'zida mujassam etgan madaniyat ham model uchun tilni o'rganishni qiyinlashtirishi mumkin.
LLM'lar odatda tarjimada yaxshi ekanligini hisobga olsak, biz shunchaki barcha so'rovlarni boshqa tillardan ingliz tiliga tarjima qilib, javoblarni olib, so'ng ularni asl tilga qayta tarjima qila olamizmi? Ko'pchilik haqiqatan ham bu yondashuvga amal qiladi, ammo bu ideal emas. Birinchidan, bu kam ifodalangan tillarni tarjima qilish uchun yetarlicha tushuna oladigan modelni talab qiladi. Ikkinchidan, tarjima ma'lumot yo'qotilishiga olib kelishi mumkin. Masalan, vyetnam tili kabi ba'zi tillarda ikki suhbatdosh o'rtasidagi munosabatni bildiruvchi olmoshlar mavjud. Ingliz tiliga tarjima qilinganda, bu olmoshlarning barchasi "I" va "you" deb tarjima qilinadi, bu esa munosabat haqidagi ma'lumotning yo'qolishiga sabab bo'ladi.
Modellar, shuningdek, ingliz tilidan boshqa tillarda kutilmagan samaradorlik muammolariga duch kelishi mumkin. Masalan, NewsGuard ChatGPT'ning ingliz tiliga qaraganda xitoy tilida dezinformatsiya yaratishga ko'proq moyil ekanligini aniqladi. 2023-yil aprel oyida NewsGuard ChatGPT-3.5'dan Xitoy haqida ingliz, soddalashtirilgan xitoy va an'anaviy xitoy tillarida dezinformatsion maqolalar yaratishni so'radi. Ingliz tili uchun ChatGPT yettita promptdan oltitasida yolg'on da'volarni yaratishdan bosh tortdi. Biroq, u soddalashtirilgan va an'anaviy xitoy tillarida barcha yetti holatda ham yolg'on da'volarni yaratdi. Xulq-atvordagi bu farqqa nima sabab bo'lgani noaniq.3
Sifat muammolaridan tashqari, modellar ingliz tilidan boshqa tillar uchun sekinroq va qimmatroq bo'lishi ham mumkin. Modelning inference kechikishi va narxi kirish va javobdagi tokenlar soniga mutanosibdir. Ma'lum bo'lishicha, tokenizatsiya ba'zi tillar uchun boshqalariga qaraganda ancha samaraliroq bo'lishi mumkin. GPT-4'ni 52 tilga tarjima qilingan bir million qisqa matndan iborat MASSIVE ma'lumotlar to'plamida sinovdan o'tkazgan Yennie Jun shuni aniqladiki, bir xil ma'noni ifodalash uchun birma va hind kabi tillar ingliz yoki ispan tillariga qaraganda ancha ko'proq token talab qiladi. MASSIVE ma'lumotlar to'plami uchun ingliz tilidagi o'rtacha token uzunligi 7 tani tashkil etsa, hind tilida bu ko'rsatkich 32 tani, birma tilida esa naq 72 tani tashkil etadi — bu ingliz tilidagidan o'n baravar ko'pdir.
Agar tokenni generatsiya qilish uchun ketadigan vaqt barcha tillarda bir xil deb faraz qilsak, GPT-4 bir xil mazmun uchun birma tilida ingliz tilidagiga qaraganda taxminan o'n baravar ko'proq vaqt sarflaydi. Token ishlatilishi bo'yicha haq oladigan API'lar uchun esa, birma tili ingliz tilidan o'n baravar qimmatroqqa tushadi.
Bu muammoni hal qilish uchun ko'plab modellar ingliz tilidan boshqa tillarga e'tibor qaratish uchun o'qitilgan. Ingliz tilidan tashqari eng faol til, shubhasiz, xitoy tilidir, bunga ChatGLM, YAYI, Llama-Chinese va boshqalarni misol qilib keltirish mumkin. Shuningdek, fransuz (CroissantLLM), vyetnam (PhoGPT), arab (Jais) va boshqa ko'plab tillarda ham modellar mavjud.
Sohaga ixtisoslashgan modellar
Gemini, GPT seriyasi va Llama seriyasi kabi umumiy maqsadli modellar kodlash, huquq, fan, biznes, sport va atrof-muhit fanlari kabi keng doiradagi sohalarda aql bovar qilmas darajada yaxshi ishlay oladi. Bu, asosan, ularning o'qitish ma'lumotlariga ushbu sohalarning kiritilgani tufaylidir. 2-3-rasmda Washington Post'ning 2023-yilgi tahliliga ko'ra, Common Crawl'da mavjud bo'lgan sohalarning taqsimoti ko'rsatilgan.4
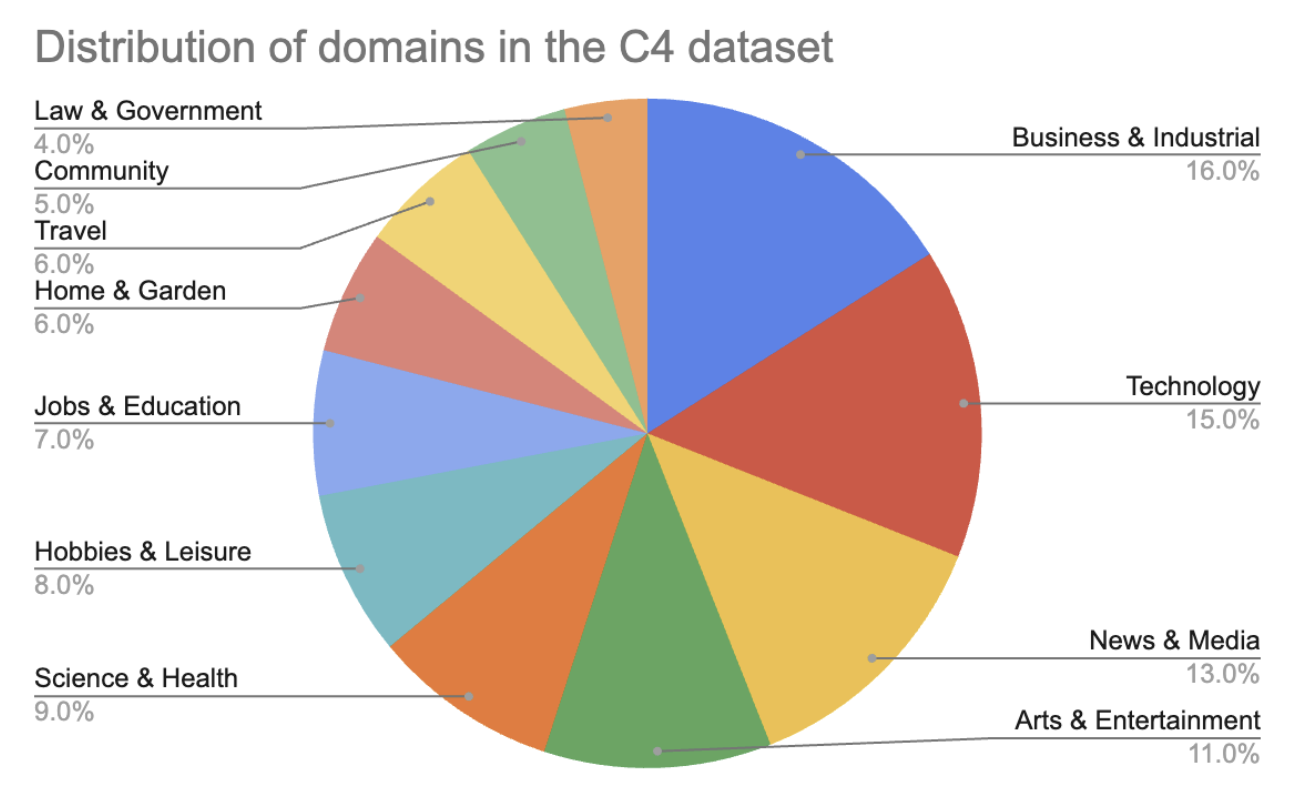
C4 ma'lumotlar to'plamidagi sohalarning taqsimoti. Washington Post statistikasi asosida qayta yaratilgan. Ushbu tahlilning bir kamchiligi shundaki, u faqat kiritilgan toifalarni ko'rsatadi, yetishmayotgan toifalarni emas.Ushbu kitob yozilayotgan vaqtda, vizual ma'lumotlardagi sohalar taqsimoti bo'yicha hali ko'p tahlillar mavjud emas. Bu, ehtimol, tasvirlarni matnlarga qaraganda tasniflash qiyinroq bo'lgani uchundir.5 Biroq, siz modelning sohalarini uning benchmark natijalaridan xulosa qilishingiz mumkin. 2-3-jadvalda ikkita model — CLIP va Open CLIP — turli benchmarklarda qanday ishlashi ko'rsatilgan. Bu benchmarklar ushbu ikki modelning qushlar, gullar, mashinalar va yana bir nechta toifalarda qanchalik yaxshi ishlashini ko'rsatadi, ammo real dunyo bu bir nechta toifadan ancha kattaroq va murakkabroqdir.
| Ma'lumotlar to'plami | CLIPViT-B/32 (OpenAI) To'g'riligi | Open CLIPViT-B/32 (Cade) To'g'riligi |
|---|---|---|
| ImageNet | 63.2 | 62.9 |
| ImageNet v2 | – | 62.6 |
| Birdsnap | 37.8 | 46.0 |
| Country211 | 17.8 | 14.8 |
| Oxford 102 Category Flower | 66.7 | 66.0 |
| German Traffic Sign Recognition Benchmark | 32.2 | 42.0 |
| Stanford Cars | 59.4 | 79.3 |
| UCF101 | 64.5 | 63.1 |
Open CLIP va CLIP'ning turli tasvir ma'lumotlar to'plamlaridagi samaradorligi.Garchi umumiy maqsadli fundamental modellar turli sohalar haqidagi kundalik savollarga javob bera olsa-da, ular tor sohaga oid vazifalarda, ayniqsa, o'qitish paytida bu vazifalarni hech qachon ko'rmagan bo'lsa, yaxshi ishlay olmasligi ehtimoli yuqori. Sohaning tor doiradagi vazifalariga ikkita misol — bu dori vositalarini kashf qilish va saratonni skrining qilishdir. Dori vositalarini kashf qilish maxsus formatlarga ega bo'lgan va olinishi qimmatga tushadigan oqsil, DNK va RNK ma'lumotlarini o'z ichiga oladi. Bu ma'lumotlarning ochiq internet ma'lumotlarida topilishi ehtimoldan yiroq. Xuddi shunday, saratonni skrining qilish odatda rentgen va fMRT (funksional magnit-rezonans tomografiya) skanerlarini o'z ichiga oladi, ularni maxfiylik tufayli olish qiyin.
Modelni ushbu sohaga ixtisoslashgan vazifalarda yaxshi ishlashga o'rgatish uchun siz juda maxsus ma'lumotlar to'plamlarini saralashingiz kerak bo'lishi mumkin. Eng mashhur sohaga ixtisoslashgan modellardan biri, ehtimol, DeepMind'ning AlphaFold modelidir. U taxminan 100 000 ta ma'lum oqsillarning ketma-ketliklari va 3D tuzilmalarida o'qitilgan. NVIDIA'ning BioNeMo modeli dori vositalarini kashf qilish uchun biomolekulyar ma'lumotlarga e'tibor qaratadigan yana bir modeldir. Google'ning Med-PaLM2 modeli esa tibbiy so'rovlarga yuqori aniqlik bilan javob berish uchun LLM qudratini tibbiy ma'lumotlar bilan birlashtirgan.
Maslahat
Sohaga ixtisoslashgan modellar ayniqsa biotibbiyotda keng tarqalgan, ammo boshqa sohalar ham ulardan foyda ko'rishi mumkin. Ehtimol, arxitektura eskizlarida o'qitilgan model me'morlargaStable Diffusion'dan ancha yaxshiroq yordam berishi mumkin yoki zavod rejalarida o'qitilgan model ishlab chiqarish jarayonlari uchunChatGPTkabi umumiy modeldan ancha yaxshiroq optimallashtirilishi mumkin.
Ushbu bo'limda o'qitish ma'lumotlarining model samaradorligiga qanday ta'sir qilishi haqida umumiy tushuncha berildi. Endi keling, modelning qanday loyihalashtirilganligi uning ishlashiga qanday ta'sir ko'rsatishini ko'rib chiqamiz.
Izohlar
-
Ushbu hisob-kitob uchun dunyo aholisi sakkiz milliard deb olingan. ↩
-
Yennie Jun, “GPT-4 Can Solve Math Problems—but Not in All Languages”. Siz bu tadqiqotni OpenAIning Tokenizer'i yordamida tekshirib ko'rishingiz mumkin. ↩
-
Bu dastlabki o'qitish ma'lumotlari yoki moslashtirish ma'lumotlaridagi ba'zi bir noxolisliklar tufayli bo'lishi mumkin. Ehtimol, OpenAI o'z modellarini o'qitish uchun xitoy tilidagi yoki Xitoyga oid hikoyalardagi ma'lumotlarni bunchalik ko'p kiritmagandir. ↩
-
“Inside the Secret List of Websites That Make AI like ChatGPT Sound Smart”, Washington Post, 2023. ↩
-
Matnlar uchun siz soha kalit so'zlarini evristika sifatida ishlatishingiz mumkin, ammo tasvirlar uchun aniq evristikalar mavjud emas. Men topa olgan vizual ma'lumotlar to'plamlari haqidagi aksariyat tahlillar tasvir o'lchamlari, tiniqligi yoki video uzunliklari haqida edi. ↩