Sampling
Model o'z natijalarini sampling (ya'ni, ehtimolliklar taqsimoti asosida natijani tanlab olish) deb nomlanuvchi jarayon orqali hosil qiladi. Ushbu bo'limda turli sampling strategiyalari va sampling o'zgaruvchilari, jumladan temperature, top-k va top-p muhokama qilinadi. So'ngra model samaradorligini oshirish uchun bir nechta natijalarni qanday sampling qilish mumkinligi ko'rib chiqiladi. Shuningdek, modellarni muayyan format va cheklovlarga rioya qiladigan javoblarni generatsiya qilishga majburlash uchun sampling jarayonini qanday o'zgartirish mumkinligini ham ko'ramiz.
Sampling SI natijalarini ehtimollikka asoslangan (probabilistic) qiladi. Ushbu ehtimollik tabiatini tushunish SI'ning nomuvofiqlik (inconsistency) va gallyutsinatsiya kabi xatti-harakatlari bilan ishlashda muhimdir. Bo'lim ushbu ehtimollik tabiati nimani anglatishi va u bilan qanday ishlash kerakligini chuqur tahlil qilish bilan yakunlanadi.
Sampling asoslari
Kirish ma'lumoti berilganda, neyron to'r avval ehtimoliy natijalarning ehtimolliklarini hisoblab, keyin natija chiqaradi. Tasniflash modeli uchun ehtimoliy natijalar — bu mavjud sinflardir. Misol uchun, agar model elektron pochtaning spam yoki spam emasligini tasniflashga o'qitilgan bo'lsa, faqat ikkita ehtimoliy natija mavjud: spam va spam emas. Model ushbu ikki natijaning har birining ehtimolligini hisoblaydi — masalan, elektron pochtaning spam bo'lish ehtimoli 90%, spam bo'lmaslik ehtimoli esa 10%. Keyin siz ushbu chiqish ehtimolliklariga asoslanib qaror qabul qilishingiz mumkin. Masalan, agar siz spam ehtimoli 50% dan yuqori bo'lgan har qanday elektron pochta spam deb belgilanishi kerak deb qaror qilsangiz, 90% spam ehtimoliga ega bo'lgan elektron pochta spam deb belgilanadi.
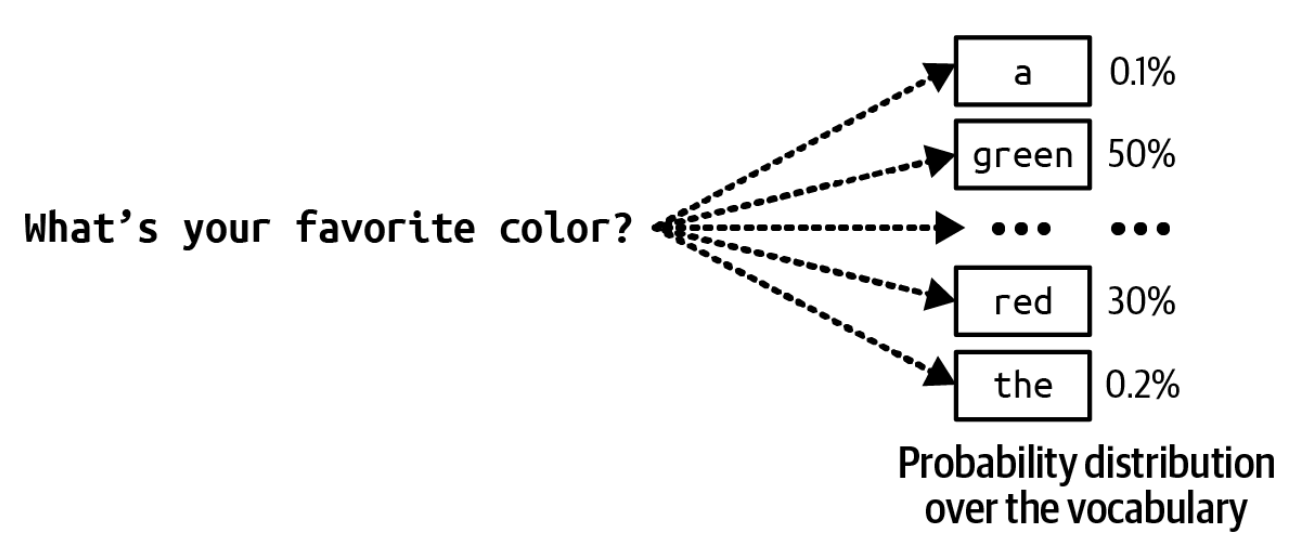
Til modeli uchun, keyingi tokenni generatsiya qilish uchun, model avval lug'atdagi barcha tokenlar bo'yicha ehtimollik taqsimotini hisoblaydi, bu 2-14-rasmda ko'rsatilgan.
Turli ehtimolliklarga ega bo'lgan ehtimoliy natijalar bilan ishlaganda, keng tarqalgan strategiya eng yuqori ehtimollikka ega bo'lgan natijani tanlashdir. Har doim eng ehtimolli natijani tanlash ochko'z sampling (greedy sampling) deb ataladi. Bu ko'pincha tasniflash vazifalari uchun yaxshi ishlaydi. Masalan, agar model elektron pochtaning spam emasligidan ko'ra, bo'lish ehtimolini yuqoriroq deb baholasa, uni spam deb belgilash mantiqan to'g'ri. Biroq, til modeli uchun ochko'z sampling zerikarli natijalarni yuzaga keltiradi. Tasavvur qiling, siz qanday savol berishingizdan qat'i nazar, doimo eng keng tarqalgan so'zlar bilan javob beradigan modelni.
Har doim keyingi eng ehtimolli tokenni tanlash o'rniga, model keyingi tokenni barcha mumkin bo'lgan qiymatlar bo'yicha ehtimollik taqsimotiga muvofiq sampling qilishi mumkin. 2-14-rasmda ko'rsatilganidek, "Mening sevimli rangim ..." konteksti berilganda, agar "qizil"ning keyingi token bo'lish ehtimoli 30% va "yashil"ning ehtimoli 50% bo'lsa, "qizil" 30% hollarda, "yashil" esa 50% hollarda tanlanadi.
Model bu ehtimolliklarni qanday hisoblaydi? Kirish ma'lumoti berilganda, neyron to'r logit vektorini (ehtimollikka aylantirilmagan "xom" ballar vektorini) chiqaradi. Har bir logit bitta ehtimoliy qiymatga mos keladi. Til modeli misolida, har bir logit model lug'atidagi bitta tokenga mos keladi. Logit vektorining o'lchami lug'at hajmiga teng. Logit vektorining vizualizatsiyasi 2-15-rasmda ko'rsatilgan.
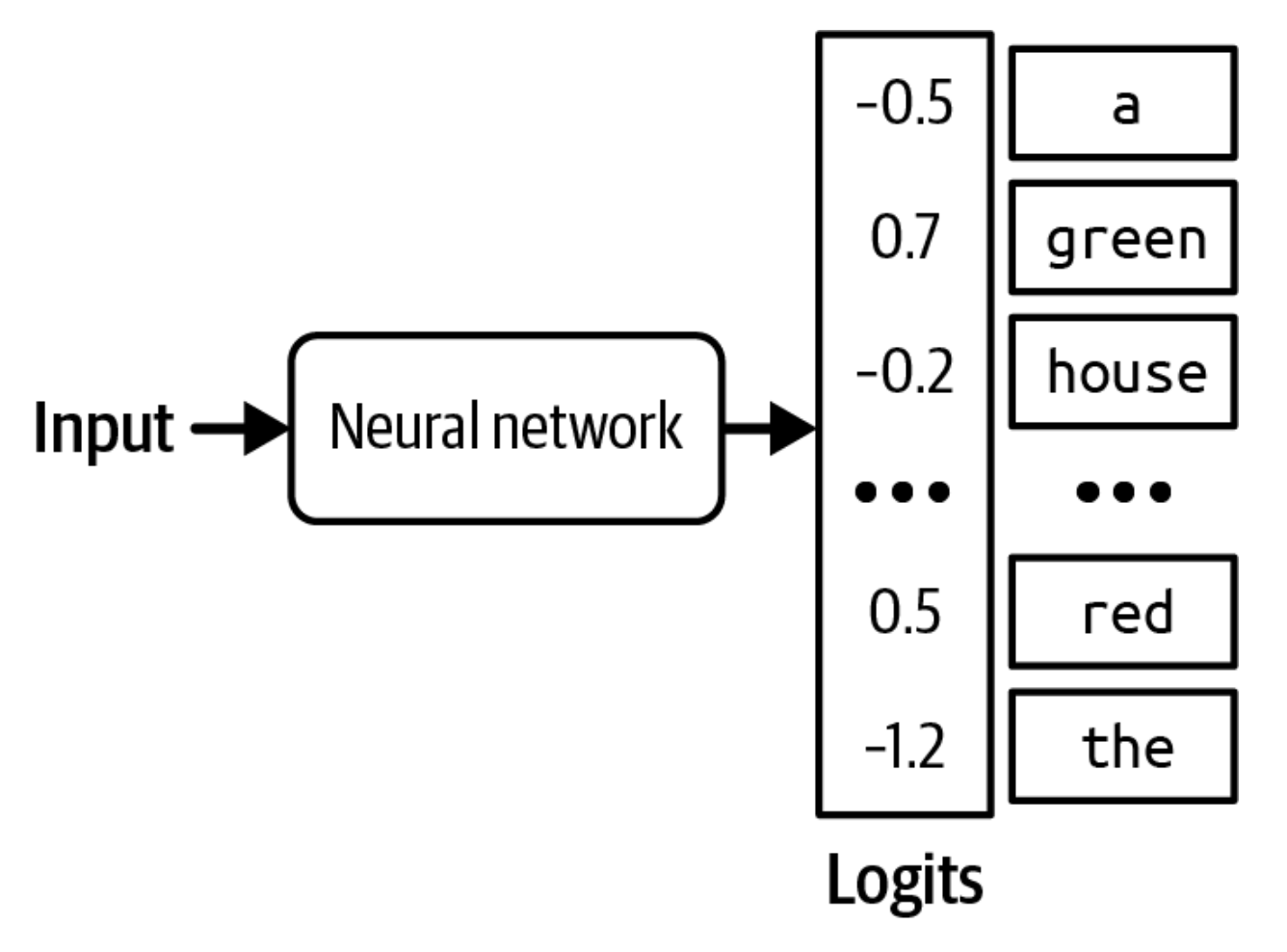
Kattaroq logit'lar yuqori ehtimolliklarga mos kelsa-da, logit'lar ehtimolliklarni ifodalamaydi. Logit'lar yig'indisi birga teng emas. Logit'lar hatto manfiy bo'lishi ham mumkin, ehtimolliklar esa manfiy bo'lmasligi kerak. Logit'larni ehtimolliklarga aylantirish uchun ko'pincha softmax qatlami ishlatiladi. Aytaylik, model N hajmli lug'atga ega va logit vektori [x1, x2, ..., xN] bo'lsin. i-chi token uchun ehtimollik, pi, quyidagicha hisoblanadi:
Sampling strategiyalari
To'g'ri sampling strategiyasi modelni sizning dasturingizga mosroq javoblar generatsiya qilishga undashi mumkin. Masalan, bir sampling strategiyasi modelni yanada ijodiy javoblar generatsiya qilishga majburlasa, boshqasi uning generatsiyalarini prognozli (predictable) qilishi mumkin. Modellarni o'ziga xos xususiyatlarga ega javoblar tomon "yo'naltirish" uchun ko'plab turli sampling strategiyalari joriy etilgan. Siz o'zingizning sampling strategiyangizni ham ishlab chiqishingiz mumkin, garchi bu odatda modelning logit'lariga kirishni talab qilsa ham. Keling, ularning qanday ishlashini ko'rish uchun bir nechta keng tarqalgan sampling strategiyalarini ko'rib chiqamiz.
Temperature
Keyingi tokenni ehtimollik taqsimotiga ko'ra sampling qilishning bir muammosi shundaki, model kamroq ijodkor (creative) bo'lishi mumkin. Oldingi misolda, "qizil", "yashil", "binafsha" kabi keng tarqalgan ranglar eng yuqori ehtimolliklarga ega. Til modelining javobi besh yoshli bolanikiga o'xshab qoladi: "Mening sevimli rangim yashil". "The" (inglizcha artikl) kabi so'zlarning ehtimoli past bo'lgani uchun, modelning "Mening sevimli rangim — bahor tongida sokin ko'lning rangi" kabi ijodiy jumla generatsiya qilish ehtimoli past bo'ladi.
Mumkin bo'lgan qiymatlarning ehtimolliklarini qayta taqsimlash uchun siz temperature bilan sampling qilishingiz mumkin. Intuitiv ravishda, yuqori temperature keng tarqalgan tokenlarning ehtimolliklarini pasaytiradi va natijada kamroq uchraydigan tokenlarning ehtimolliklarini oshiradi. Bu modellarga ijodiyroq javoblar yaratish imkonini beradi.
Temperature — bu softmax transformatsiyasidan oldin logit'larni sozlash uchun ishlatiladigan doimiy qiymat. Logit'lar temperature'ga bo'linadi. Berilgan temperature uchun, -chi token uchun sozlangan logit qiymati bo'ladi. Keyin softmax o'rniga ushbu sozlangan logit'ga qo'llaniladi.
Temperature'ning ehtimolliklarga ta'sirini o'rganish uchun oddiy bir misolni ko'rib chiqamiz. Tasavvur qiling, bizda faqat ikkita ehtimoliy natijaga ega bo'lgan model bor: A va B. Oxirgi qatlamdan hisoblangan logit'lar [1, 2]. A uchun logit 1, B uchun esa 2.
Temperature'siz (bu 1 ga tengtemperature'ni ishlatish bilan bir xil),softmaxehtimolliklari [0.27, 0.73] bo'ladi. Model 73% hollarda B ni tanlaydi.Temperature= 0.5 bo'lganda, ehtimolliklar [0.12, 0.88] bo'ladi. Endi model 88% hollarda B ni tanlaydi.
Temperature qanchalik yuqori bo'lsa, modelning eng aniq qiymatni (eng yuqori logit'ga ega qiymatni) tanlash ehtimoli shunchalik kamayadi. Bu model natijalarini ijodiyroq qiladi, lekin ular mantiqiy jihatdan kamroq bog'langan (coherent) bo'lishi mumkin. Temperature qanchalik past bo'lsa, modelning eng aniq qiymatni tanlash ehtimoli shunchalik yuqori bo'ladi, bu esa model natijasini yanada izchil (consistent) qiladi, lekin u zerikarliroq bo'lishi mumkin.1
2-16-rasmda turli temperature'da A va B tokenlari uchun softmax ehtimolliklari ko'rsatilgan. Temperature 0 ga yaqinlashgan sari, modelning B tokenini tanlash ehtimoli 1 ga yaqinlashadi. Bizning misolimizda, 0.1 dan past temperature uchun model deyarli har doim B ni chiqaradi. Temperature oshgan sari, A tokenining tanlanish ehtimoli ortadi, B tokenining tanlanish ehtimoli esa kamayadi. Model provayderlari odatda temperature'ni 0 va 2 oralig'ida cheklashadi. Agar siz o'z modelingizga ega bo'lsangiz, istalgan manfiy bo'lmagan temperature'dan foydalanishingiz mumkin. Ijodiy qo'llanish holatlari uchun ko'pincha 0.7 temperature tavsiya etiladi, chunki u ijodkorlik va prognozli bo'lishlik o'rtasidagi muvozanatni ta'minlaydi, lekin siz tajriba o'tkazib, o'zingiz uchun eng yaxshi ishlaydigan temperature'ni topishingiz mumkin.
![2-16-rasm. A va B tokenlarining logitlari [1, 2] bo'lganda, turli temperature'dagi softmax ehtimolliklari.](/ai-engineering/2-chapter/2.16-figure.png)
temperature'lardagi softmax ehtimolliklari. temperature qiymatini belgilamasdan, ya'ni 1 ga teng temperature'dan foydalanganda, B ning softmax ehtimoli 73% bo'lardi.Model natijalari izchilroq bo'lishi uchun temperature'ni 0 ga o'rnatish keng tarqalgan amaliyotdir. Texnik jihatdan, temperature hech qachon 0 bo'la olmaydi — logit'larni 0 ga bo'lish mumkin emas. Amalda esa, biz temperature'ni 0 ga o'rnatganimizda, model shunchaki logit sozlamasi va softmax hisob-kitobini qilmasdan, eng katta logit'ga ega bo'lgan tokenni tanlaydi.2
Maslahat
SI modeli bilan ishlashdagi keng tarqalgan nosozliklarni aniqlashning (debugging)ning keng tarqalgan usullaridan biri — bu modelning berilgan kirish ma'lumotlari uchun hisoblagan ehtimolliklarini ko'zdan kechirishdir. Masalan, agar ehtimolliklar tasodifiydek ko'rinsa, demak, model hali ko'p narsani o'rganmagan.
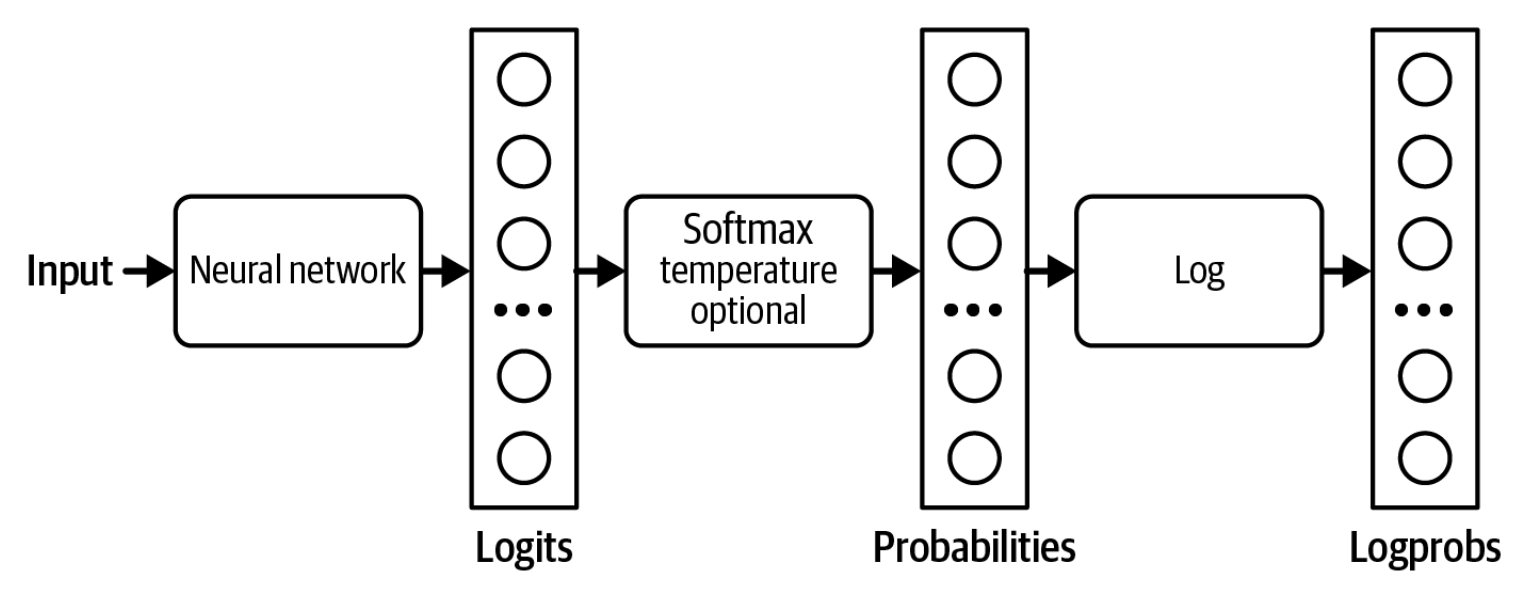
Ko'pgina model provayderlari o'z modellari tomonidan generatsiya qilingan ehtimolliklarni logprobs sifatida qaytaradi. Logprobs, ya'ni logarifmik ehtimolliklar (log probabilities), logarifmik shkaladagi ehtimolliklardir. Neyron to'rning ehtimolliklari bilan ishlaganda logarifmik shkalaga afzallik beriladi, chunki u underflow muammosini kamaytirishga yordam beradi.3 Til modeli 100 000 hajmli lug'at bilan ishlayotgan bo'lishi mumkin, bu esa ko'plab tokenlar uchun ehtimolliklar mashina tomonidan ifodalash uchun juda kichik bo'lishi mumkinligini anglatadi. Kichik sonlar 0 ga yaxlitlanishi mumkin. Logarifmik shkala bu muammoni kamaytirishga yordam beradi.
2-17-rasmda logit'lar, ehtimolliklar va logprob'larning qanday hisoblanishi ish jarayoni ko'rsatilgan.
Kitob davomida ko'rib turganingizdek, logprob dasturlarni yaratish (ayniqsa, tasniflash uchun), dasturlarni baholash va modellarning ichki ishlashini tushunish uchun foydalidir. Biroq, ushbu kitob yozilayotgan vaqtda, ko'plab model provayderlari o'z modellarining logprob'larini oshkor qilmaydi, yoki agar oshkor qilsalar ham, logprob API'si cheklangan bo'ladi.4 Cheklangan logprob API'si, ehtimol, xavfsizlik sabablari bilan bog'liq, chunki modelning oshkor qilingan logprob'lari boshqalarga modelni nusxalashni osonlashtiradi.
Top-k
Top-k — bu model javoblarining xilma-xilligiga jiddiy putur yetkazmagan holda hisoblash yuklamasini kamaytirishga qaratilgan sampling strategiyasidir. Esingizda bo'lsa, softmax qatlami barcha mumkin bo'lgan qiymatlar bo'yicha ehtimollik taqsimotini hisoblash uchun ishlatilardi. Softmax barcha mumkin bo'lgan qiymatlar ustidan ikki marta o'tishni talab qiladi: biri eksponensial yig'indini () hisoblash uchun, ikkinchisi har bir qiymat uchun amalini bajarish uchun. Katta lug'atga ega til modeli uchun bu jarayon hisoblash jihatidan ko'p resurs talab qiladi.
Bu muammoning oldini olish uchun, model logit'larni hisoblab chiqqanidan so'ng, biz faqat eng yuqori k ta _logit_ni (top-k) tanlab olamiz va softmaxni faqat shu logit'lar ustida bajaramiz. Ilovangiz qanchalik xilma-xil javob berishini xohlayotganingizga qarab, k ning qiymati 50 dan 500 gacha bo'lishi mumkin — bu modelning lug'at hajmidan ancha kichikdir. Keyin model shu eng yuqori qiymatlar orasidan sampling qiladi. Kichikroq k qiymati matnni ko'proq prognozli, lekin kamroq qiziqarli qiladi, chunki model ehtimoliy so'zlarning kichikroq to'plami bilan cheklanib qoladi.
Top-p
Top-k sampling'ida ko'rib chiqiladigan qiymatlar soni k'ga qat'iy belgilangan. Biroq, bu son vaziyatga qarab o'zgarishi kerak. Masalan, "Musiqani yoqtirasizmi? Faqat ha yoki yo'q deb javob bering." prompti berilganda, ko'rib chiqiladigan qiymatlar soni ikkita bo'lishi kerak: ha va yo'q. "Hayotning ma'nosi nima?" prompti berilganda esa, ko'rib chiqiladigan qiymatlar soni ancha kattaroq bo'lishi kerak.
Top-p, shuningdek, nucleus sampling deb ham ataladi, sampling uchun qiymatlarni yanada dinamik tanlash imkonini beradi. Top-p sampling'ida model eng ehtimoliy keyingi qiymatlarning ehtimolliklarini kamayish tartibida yig'ib boradi va yig'indi p'ga yetganda to'xtaydi. Faqat ushbu yig'indi (kummulyativ) ehtimollik doirasidagi qiymatlar hisobga olinadi. Til modellarida top-p (nucleus) sampling uchun keng tarqalgan qiymatlar odatda 0,9 dan 0,95 gacha bo'ladi. Masalan, 0,9 ga teng top-p qiymati model yig'indi ehtimolligi 90% dan oshadigan eng kichik qiymatlar to'plamini inobatga olishini anglatadi.
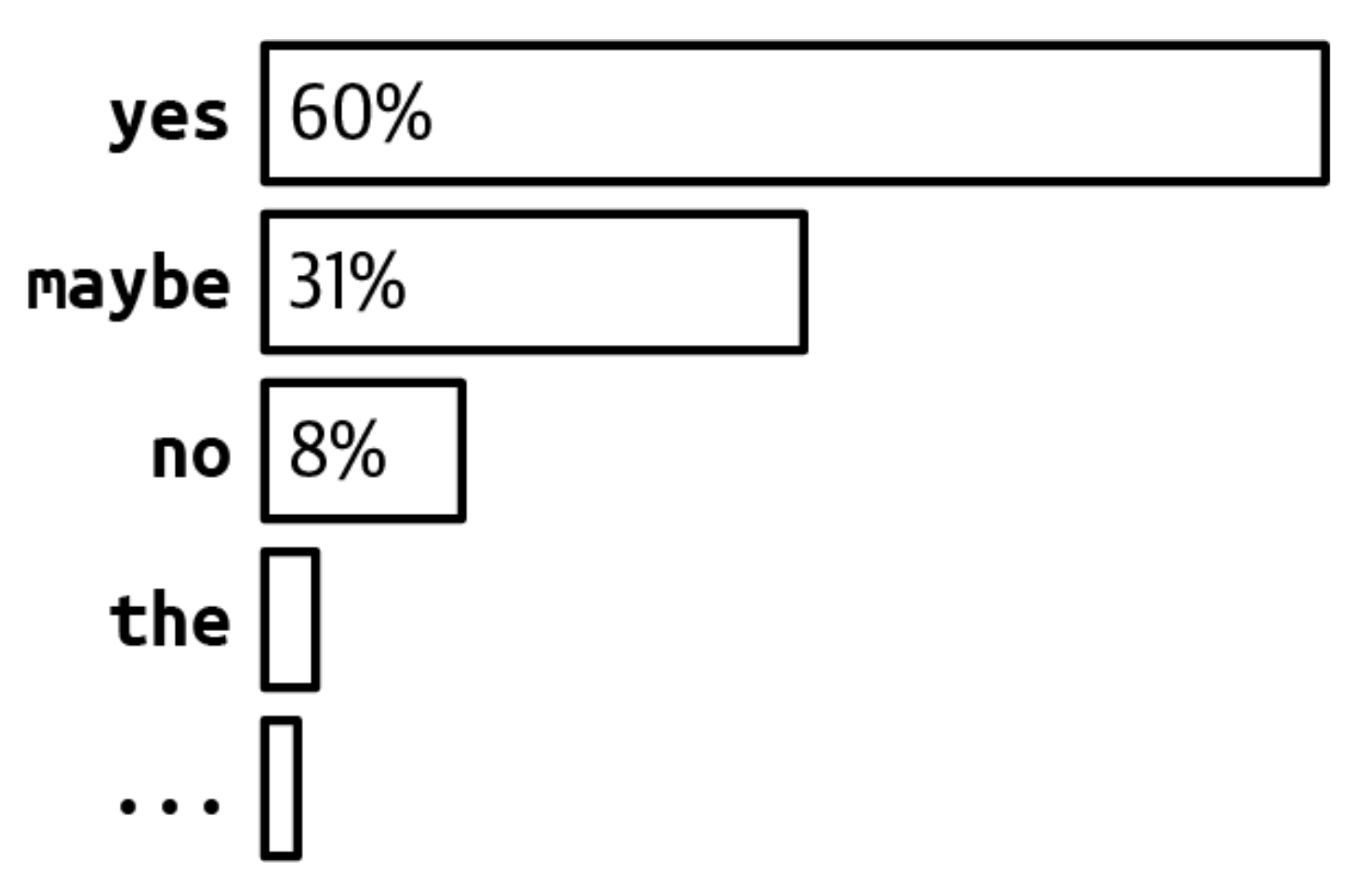
Aytaylik, barcha tokenlarning ehtimolliklari 2-18-rasmda ko'rsatilganidek. Agar top-p 90% bo'lsa, faqat "ha" va "balki" ko'rib chiqiladi, chunki ularning yig'indi ehtimolligi 90% dan katta. Agar top-p 99% bo'lsa, unda "ha", "balki" va "yo'q" ko'rib chiqiladi.
Top-k'dan farqli o'laroq, top-p softmax hisoblash xarajatlarini har doim ham kamaytirmaydi. Uning afzalligi shundaki, u har bir kontekst uchun faqat eng munosib qiymatlar to'plamiga e'tibor qaratgani sababli, natijalarning kontekstga yanada mosroq bo'lishiga imkon beradi. Nazariy jihatdan, top-p sampling'ining jiddiy ustunliklari yo'qdek tuyuladi. Biroq, amalda, top-p sampling'i o'zini a'lo darajada namoyon etdi, bu esa uning keng ommalashishiga sabab bo'ldi.
Bunga bog'liq bo'lgan yana bir sampling strategiyasi bu min-p bo'lib, unda siz sampling jarayonida ko'rib chiqilishi uchun token erishishi kerak bo'lgan minimal ehtimollikni belgilaysiz.
To'xtatish shartlari
Avtoregressiv til modeli tokenlar ketma-ketligini birin-ketin generatsiya qilish orqali yaratadi. Uzun natija ko'proq vaqt sarflaydi, ko'proq hisoblash quvvati (ya'ni, pul)5 talab qiladi va ba'zan foydalanuvchilarning g'ashiga tegishi mumkin. Shu sababli, model uchun generatsiyani yakunlash shartini belgilash maqsadga muvofiq.
Eng oson usullardan biri — bu modeldan belgilangan miqdordagi tokenlardan so'ng generatsiyani to'xtatishni so'rashdir. Buning kamchiligi shundaki, natija katta ehtimol bilan gapning o'rtasida uzilib qoladi. Yana bir usul — bu to'xtash tokenlari (stop tokens) yoki to'xtash so'zlaridan (stop words) foydalanish. Masalan, siz modeldan ketma-ketlikning tugash tokenini (end-of-sequence token) uchratganda generatsiyani to'xtatishni so'rashingiz mumkin. To'xtatish shartlari kechikish (latency) va xarajatlarni kamaytirishda ancha qo'l keladi.
Vaqtidan oldin to'xtatishning salbiy tomoni shundaki, agar siz modellardan ma'lum bir formatdagi natijalarni generatsiya qilishni xohlasangiz, muddatidan oldin to'xtash natijalarning noto'g'ri formatlanishiga (malformatted) olib kelishi mumkin. Masalan, agar siz modeldan JSON generatsiya qilishni so'rasangiz, vaqtidan oldin to'xtash natijaviy JSON'da yopuvchi qavslar kabi elementlarning tushib qolishiga sabab bo'lishi mumkin, bu esa generatsiya qilingan JSON'ni tahlil qilishni (parsing) qiyinlashtiradi.
Inference bosqichida kengaytirilgan hisoblash
Oldingi bo'limda model keyingi tokenni qanday sampling qilishi mumkinligi muhokama qilindi. Ushbu bo'limda esa model butun natijani qanday sampling qilishi mumkinligi muhokama qilinadi.
Model javobining sifatini oshirishning oddiy usullaridan biri bu inference bosqichida kengaytirilgan hisoblash (test time compute) strategiyasidir: har bir so'rov uchun faqat bitta javob generatsiya qilish o'rniga, siz yaxshi javoblar ehtimolini oshirish uchun bir nechta javob generatsiya qilasiz. Inference bosqichida kengaytirilgan hisoblashni amalga oshirishning bir usuli — bu ushbu bobda avvalroq muhokama qilingan "N tadan eng yaxshisi" texnikasidir — siz tasodifiy ravishda bir nechta natija generatsiya qilasiz va eng yaxshi ishlaydiganini tanlaysiz. Biroq, bir nechta natijani qanday generatsiya qilish borasida strategikroq yondashishingiz ham mumkin. Masalan, barcha natijalarni mustaqil ravishda generatsiya qilish o'rniga (bu ko'plab istiqbolsiz nomzodlarni o'z ichiga olishi mumkin), ketma-ketlik generatsiyasining har bir qadamida belgilangan miqdordagi eng istiqbolli nomzodlarni (nur yoki beam) generatsiya qilish uchun nurli qidiruvdan (beam search) foydalanishingiz mumkin.
Inference bosqichida kengaytirilgan hisoblash samaradorligini oshirishning oddiy strategiyasi — bu natijalarning xilma-xilligini oshirishdir, chunki xilma-xilroq variantlar to'plami yaxshiroq nomzodlarni berishi ehtimoli yuqoriroq. Agar siz turli xil variantlarni generatsiya qilish uchun bir xil modeldan foydalansangiz, uning natijalarini xilma-xillashtirish uchun modelning sampling parametrlarini o'zgartirib turish ko'pincha yaxshi amaliyotdir.
Garchi siz odatda bir nechta natijani sampling qilish orqali model samaradorligida biroz yaxshilanishni kutishingiz mumkin bo'lsa-da, bu qimmatga tushadi. O'rtacha hisobda, ikkita natija generatsiya qilish bitta natija generatsiya qilishdan taxminan ikki baravar qimmatroqqa tushadi.6
Ogohlantirish
Garchi dastlabki taqrizchilarning bir qanchasi bu atama chalg'ituvchi ekanligiga e'tiroz bildirgan bo'lsa-da, mavjud ilmiy adabiyotlar bilan izchillikni saqlash maqsadida men test time compute atamasidan foydalanmoqdaman. SI tadqiqotlarida test time (sinov vaqti) odatda inference ma'nosida ishlatiladi, chunki tadqiqotchilar inference'ni asosan modelni sinab ko'rish uchungina bajaradilar. Aslida esa, bu texnikani bemalol real amaliyotdagi modellarga ham qo'llash mumkin.Bu jarayonning inference bosqichida kengaytirilgan hisoblash (test time compute) deb atalishiga sabab shuki, siz sampling qilishingiz mumkin bo'lgan natijalar soni har bir inference so'rovi uchun qancha hisoblash quvvatini ajrata olishingiz bilan belgilanadi.
Eng yaxshi natijani tanlash uchun, siz foydalanuvchilarga bir nechta natijani ko'rsatib, ularga o'zlari uchun eng yaxshi ishlaydiganini tanlash imkonini berishingiz yoki eng yaxshisini tanlash usulini ishlab chiqishingiz mumkin. Tanlash usullaridan biri — bu eng yuqori ehtimollikka ega bo'lgan natijani tanlashdir. Til modelining natijasi — bu tokenlar ketma-ketligi va har bir token model tomonidan hisoblangan ehtimollikka ega. Natijaning ehtimolligi — bu natijadagi barcha tokenlar ehtimolliklarining ko'paytmasidir.
["I", "love", "food"] tokenlar ketma-ketligini ko'rib chiqaylik. Agar "I" uchun ehtimollik 0.2, "I" berilganda "love" uchun ehtimollik 0.1 va "I" va "love" berilganda "food" uchun ehtimollik 0.3 bo'lsa, ketma-ketlikning ehtimolligi: 0.2 × 0.1 × 0.3 = 0.006 bo'ladi. Matematik jihatdan buni quyidagicha ifodalash mumkin:
Eslatma uchun, ehtimolliklar bilan logarifmik shkalada ishlash osonroq. Ko'paytmaning logarifmi logarifmlar yig'indisiga teng, shuning uchun tokenlar ketma-ketligining logprob'i ketma-ketlikdagi barcha tokenlar logprob'larining yig'indisiga teng:
Qo'shishda, uzunroq ketma-ketliklar umumiy logprob'i pastroq bo'lishi ehtimoli yuqori (chunki logprob qiymatlari odatda manfiy bo'ladi, chunki 0 va 1 orasidagi qiymatlarning logarifmi manfiydir). Qisqa ketma-ketliklarga moyillikni oldini olish uchun, siz ketma-ketlik yig'indisini uning uzunligiga bo'lish orqali o'rtacha logprob'dan foydalanishingiz mumkin. Bir nechta natijani sampling qilganingizdan so'ng, siz eng yuqori o'rtacha logprob'ga ega bo'lganini tanlaysiz. Ushbu kitob yozilayotgan vaqtda, OpenAI API'si aynan shu usuldan foydalanadi.7
Tanlov uchun mukofot modellaridan foydalanish
Yana bir tanlov usuli — bu oldingi bo'limda muhokama qilinganidek, har bir natijani baholash uchun mukofot modelidan (reward model) foydalanishdir. Esingizda bo'lsa, Stitch Fix ham, Grab ham o'zlarining mukofot modellari yoki verifikatorlari (verifiers) tomonidan yuqori ball berilgan natijalarni tanlashadi. Nextdoor mukofot modelidan foydalanish ularning dasturi samaradorligini oshirishda asosiy omil bo'lganini aniqladi (2023).
OpenAI ham o'z modellariga matematik masalalarning eng yaxshi yechimlarini tanlashda yordam berish uchun verifikatorlarni o'qitgan (Cobbe va boshq., 2021). Ular verifikatordan foydalanish model samaradorligini sezilarli darajada oshirganini aniqladilar. Aslida, verifikatorlardan foydalanish model hajmini 30 baravar oshirish bilan deyarli bir xil samaradorlik o'sishiga olib kelgan. Bu shuni anglatadiki, verifikatordan foydalanadigan 100 million parametrli model verifikatordan foydalanmaydigan 3 milliard parametrli model bilan bir xil darajada ishlay oladi.
DeepMind inference bosqichida kengaytirilgan hisoblashning ahamiyatini yanada mustahkamlab, inference bosqichida kengaytirilgan hisoblashni miqyoslash (masalan, inference paytida ko'proq natija generatsiya qilish uchun ko'proq hisoblash quvvati ajratish) model parametrlarini ko'paytirishdan ko'ra samaraliroq bo'lishi mumkinligini ta'kidlaydi (Snell va boshq., 2024). Xuddi shu maqolada qiziqarli bir savol o'rtaga tashlanadi: Agar LLM'ga murakkab prompt ustida ishlash uchun inference vaqtida qat'iy belgilangan, ammo salmoqli darajadagi hisoblash quvvatidan foydalanish imkoniyati berilsa, u o'z natijasini qanchalik yaxshilay oladi?
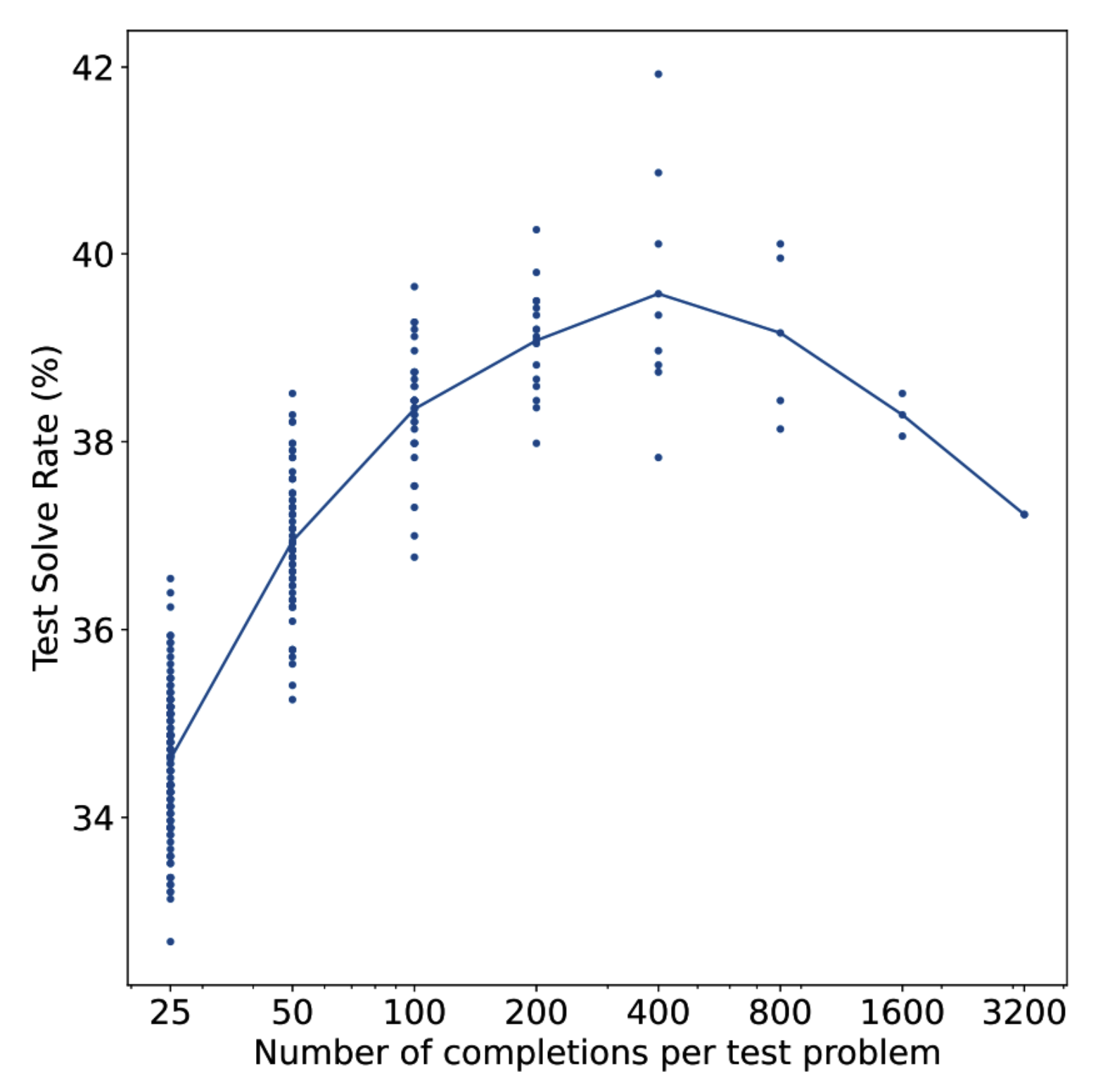
OpenAI tajribasida ko'proq natijalarni sampling qilish yaxshiroq samaradorlikka olib keldi, ammo faqat ma'lum bir nuqtagacha. Bu tajribada o'sha nuqta 400 ta natija edi. Bu nuqtadan o'tgach, samaradorlik pasayadi (2-19-rasm). Ular sampling qilingan natijalar soni ortgan sari, verifikatorni aldashi mumkin bo'lgan zararli (adversarial) natijalarni topish ehtimoli ham ortadi, deb taxmin qilishdi. Biroq, Stenford tajribasi boshqa bir xulosani ko'rsatdi. “Monkey Business” (Brown va boshq., 2024) tadqiqoti shuni ko'rsatadiki, namunalar soni 1 dan 10 000 gacha ortgan sari yechilgan masalalar soni ko'pincha log-chiziqli ravishda ortadi. Garchi inference bosqichida kengaytirilgan hisoblashni cheksiz miqyoslash mumkinmi yoki yo'qligi haqida o'ylash qiziqarli bo'lsa-da, menimcha, amaliyotda hech kim har bir kirish uchun 400 yoki 10 000 xil natijani sampling qilmaydi. Xarajatlar juda katta bo'lib ketardi.
Siz, shuningdek, eng yaxshi javobni tanlash uchun dasturga xos evristik usullardan foydalanishingiz mumkin. Masalan, agar dasturingiz qisqaroq javoblardan foyda ko'rsa, siz eng qisqa nomzodni tanlashingiz mumkin. Agar dasturingiz tabiiy tilni SQL so'rovlariga o'girsa, siz modeldan to'g'ri SQL so'rovini generatsiya qilmaguncha natijalar generatsiya qilishda davom etishini so'rashingiz mumkin.
Inference bosqichida kengaytirilgan hisoblashning yana bir o'ziga xos qiziqarli qo'llanishi — bu kechikish (latency) muammosini yengib o'tishdir. Ba'zi so'rovlar, ayniqsa fikrlash zanjiri (chain-of-thought) talab qiladigan so'rovlar uchun model javobni yakunlashga uzoq vaqt sarflashi mumkin. TIFIN kompaniyasining SI rahbari Kittipat Kampa menga aytishicha, uning jamoasi o'z modelidan bir nechta javobni parallel ravishda generatsiya qilishni so'raydi va foydalanuvchiga birinchi bo'lib yakunlangan va to'g'ri bo'lgan javobni ko'rsatadi.
Ko'pchilik ovozi bilan tanlash
Bir nechta natijalar to'plami orasidan eng ko'p uchragan natijani tanlash, ayniqsa, aniq javoblar kutiladigan vazifalar uchun foydali bo'lishi mumkin.8 Masalan, matematik masala berilganda, model uni bir necha marta yechishi va eng ko'p uchragan javobni o'zining yakuniy yechimi sifatida tanlashi mumkin. Xuddi shunday, ko'p tanlovli savol uchun model eng ko'p uchragan javob variantini tanlashi mumkin. Google Gemini'ni MMLU benchmarkida baholaganda aynan shunday qilgan. Ular har bir savol uchun 32 ta natijani sampling qilishgan. Bu modelga har bir savol uchun faqat bitta natija bilan erishishi mumkin bo'lganidan yuqoriroq ball olish imkonini bergan.
Agar model kirishdagi kichik o'zgarishlarga o'z natijalarini keskin o'zgartirmasa, u mustahkam (robust) hisoblanadi. Model qanchalik mo'rt (less robust) bo'lsa, siz bir nechta natijani sampling qilishdan shunchalik ko'p foyda ko'rasiz.9 Bir loyihada biz mahsulot tasviridan ma'lum bir ma'lumotni ajratib olish uchun SI'dan foydalandik. Biz shuni aniqladikki, bir xil tasvir uchun modelimiz ma'lumotni faqat yarim hollarda o'qiy oldi. Qolgan yarim hollarda esa, model tasvir juda xira yoki matn o'qish uchun juda kichik ekanligini aytdi. Biroq, har bir tasvir bilan uch marta urinib ko'rish orqali, model aksariyat tasvirlar uchun to'g'ri ma'lumotni ajratib olishga muvaffaq bo'ldi.
Strukturalashgan natijalar
Amaliyotda ko'pincha modellardan ma'lum formatlarga rioya qiladigan natijalarni generatsiya qilish talab etiladi. Strukturalashgan natijalar (Structured outputs) quyidagi ikki holat uchun juda muhimdir:
1. Strukturalashgan natijalarni talab qiladigan vazifalar
Bu holatdagi eng keng tarqalgan vazifalar toifasi — bu semantik tahlildir (semantic parsing). Semantik tahlil tabiiy tilni strukturalashgan, mashina o'qiy oladigan formatga o'tkazishni o'z ichiga oladi. Matndan-SQL'ga (Text-to-SQL) — bu semantik tahlilning bir misoli bo'lib, unda natijalar to'g'ri SQL so'rovlari bo'lishi shart. Semantik tahlil foydalanuvchilarga API'lar bilan tabiiy til (masalan, ingliz tili) yordamida ishlash imkonini beradi. Masalan, matndan-PostgreSQL'ga o'girish foydalanuvchilarga PostgreSQL'da yozish o'rniga, "So'nggi 6 oy ichidagi o'rtacha oylik daromad qancha" kabi inglizcha so'rovlar yordamida Postgres ma'lumotlar bazasidan so'rov qilish imkonini beradi.
Quyida GPT-4o'ga matndan-regex'ga o'girish vazifasini bajarish uchun berilgan promptga misol keltirilgan. Natijalar GPT-4o tomonidan generatsiya qilingan haqiqiy natijalardir:
Bu holatdagi boshqa vazifalar toifalariga tasniflash kiradi, bunda natijalar to'g'ri sinflar bo'lishi shart.
2. Natijalari keyingi dasturlar tomonidan ishlatiladigan vazifalar
Bu holatda, vazifaning o'zi natijalarning strukturalashgan bo'lishini talab qilmaydi, lekin natijalar boshqa dasturlar tomonidan ishlatilgani uchun, ular o'sha dasturlar tomonidan tahlil qilinadigan (parsable) bo'lishi kerak.
Masalan, agar siz elektron pochta yozish uchun SI modelidan foydalansangiz, xatning o'zi strukturalashgan bo'lishi shart emas. Biroq, ushbu xatdan foydalanadigan keyingi dastur uning ma'lum bir formatda bo'lishini talab qilishi mumkin — masalan, {"title": [SARLAVHA], "body": [XAT MATNI]} kabi maxsus kalitlarga ega bo'lgan JSON dokumenti.
Bu, ayniqsa, 6-bobda muhokama qilinadigan agentlik ish jarayonlari (agentic workflows) uchun muhim, chunki ularda modelning natijalari ko'pincha model ishlatishi mumkin bo'lgan vositalarga kirish ma'lumoti sifatida uzatiladi.
Strukturalashgan natijalarni ta'minlash
Strukturalashgan natijalarni qo'llab-quvvatlaydigan freymvorklarga guidance, outlines, instructor va llama.cpp kiradi. Har bir model provayderi ham o'z modellarining strukturalashgan natijalarni generatsiya qilish qobiliyatini yaxshilash uchun o'z texnikalaridan foydalanishi mumkin. OpenAI o'zining matn generatsiyasi API'sida JSON rejimini joriy etgan birinchi model provayderi bo'ldi. Shuni unutmangki, API'ning JSON rejimi odatda faqat natijalarning to'g'ri JSON ekanligini kafolatlaydi — JSON obyektlarining mazmunini emas. Aks holda to'g'ri bo'lgan generatsiya qilingan JSON'lar ham, agar generatsiya juda erta to'xtasa, masalan, maksimal chiqish tokeni uzunligiga yetganda, uzilib qolishi va shu sababli tahlil qilib bo'lmaydigan (not parsable) bo'lishi mumkin. Biroq, agar maksimal token uzunligi juda uzun qilib belgilansa, modelning javoblari ham juda sekin, ham qimmat bo'lib qoladi.
2-20-rasmda guidance'dan foydalanib, natijalarni ma'lum bir variantlar to'plami va regex bilan cheklangan holda generatsiya qilishning ikkita misoli ko'rsatilgan.

guidance'dan foydalanish.Strukturalashgan natijalarga erishish yondashuvlari
Siz modelni SI stekining turli qatlamlarida strukturalashgan natijalarni generatsiya qilishga yo'naltirishingiz mumkin: promptlash, yakuniy ishlov berish (post-processing), inference bosqichida kengaytirilgan hisoblash, cheklangan sampling (constrained sampling) va finetuning. Birinchi uchtasi ko'proq "yara bog'lovchi vosita"ga o'xshaydi. Ular model strukturalashgan natijalarni generatsiya qilishda shundoq ham yaxshi bo'lsa va unga shunchaki kichik turtki kerak bo'lsa, eng yaxshi samara beradi. Jiddiyroq "davolash" uchun esa sizga cheklangan sampling va finetuning kerak bo'ladi.
Inference bosqichida kengaytirilgan hisoblash oldingi bo'limda muhokama qilindi — kutilgan formatga mos keladigan javob chiqmaguncha natijalarni generatsiya qilishda davom etaverasiz. Ushbu bo'lim qolgan to'rtta yondashuvga qaratilgan.
Promptlash
Promptlash — bu strukturalashgan natijalar olish uchun birinchi chora. Siz modelga istalgan formatda natija generatsiya qilish bo'yicha ko'rsatma berishingiz mumkin. Biroq, modelning bu ko'rsatmaga amal qila olishi uning ko'rsatmalarga amal qilish qobiliyatiga (4-bobda muhokama qilinadi) va ko'rsatmaning aniqligiga (5-bobda muhokama qilinadi) bog'liq. Garchi modellar ko'rsatmalarga amal qilishda tobora yaxshilanib borayotgan bo'lsa-da, ularning har doim ham ko'rsatmalaringizga rioya qilishiga kafolat yo'q.10 Hatto bir necha foizlik noto'g'ri natijalar ham ko'plab dasturlar uchun qabul qilib bo'lmas holat bo'lishi mumkin.
To'g'ri natijalar foizini oshirish uchun, ba'zilar dastlabki prompt natijasini tekshirish va/yoki tuzatish uchun SI'dan foydalanadilar. Bu 3-bobda muhokama qilinadigan "SI — baholovchi" yondashuvining bir namunasidir. Bu shuni anglatadiki, har bir natija uchun kamida ikkita model so'rovi bo'ladi: biri natijani generatsiya qilish uchun va biri uni tekshirish uchun. Qo'shilgan tekshirish qatlami natijalarning yaroqliligini sezilarli darajada oshirishi mumkin bo'lsa-da, qo'shimcha tekshirish so'rovlari tufayli yuzaga keladigan ortiqcha xarajat va kechikish bu yondashuvni ba'zilar uchun juda qimmatga tushirishi mumkin.
Yakuniy ishlov berish
Yakuniy ishlov berish (Post-processing) — oddiy va arzon usul bo'lsa-da, kutilmaganda ajoyib natijalar berishi mumkin. O'qituvchilik qilgan paytlarimda talabalarim bir xil xatolarni qayta-qayta takrorlashga moyil ekanini payqaganman. Fundamental modellar bilan ishlay boshlaganimda ham xuddi shu holatga guvoh bo'ldim. Model so'rovlar bo'ylab o'xshash xatolarni takrorlashga moyil bo'ladi. Bu shuni anglatadiki, agar siz model yo'l qo'yadigan odatiy xatolarni aniqlay olsangiz, ularni tuzatuvchi skript yozishingiz mumkin. Masalan, agar generatsiya qilingan JSON obyektida yopuvchi qavs yetishmayotgan bo'lsa, o'sha qavsni qo'lda qo'shib qo'yish kifoya. LinkedIn’ning himoyaviy YAML parseri to'g'ri YAML natijalari ulushini 90% dan 99,99% gacha oshirishga erishgan (Bottaro va Ramgopal, 2020).
Maslahat:
JSON va YAML keng tarqalgan matn formatlaridir. LinkedIn ularning asosiy modeliGPT-4ikkalasi bilan ham ishlashini aniqladi, lekin ular o'zlarining natija formati sifatida YAML'ni tanladilar, chunki u kamroq yoziladigan va shuning uchun JSON'ga qaraganda kamroq chiquvchi tokenlarni talab qiladi (Bottaro va Ramgopal, 2020).
Yakuniy ishlov berish faqat xatolarni tuzatish oson bo'lganda ishlaydi. Bu odatda model natijalari allaqachon asosan to'g'ri formatlangan bo'lib, vaqti-vaqti bilan kichik xatolar uchraganda sodir bo'ladi.
Cheklangan sampling
Cheklangan sampling (Constrained sampling) — bu matn generatsiyasini muayyan cheklovlar tomon yo'naltirish texnikasidir. U odatda strukturalashgan natija vositalari tomonidan qo'llaniladi.
Umuman olganda, tokenni generatsiya qilish uchun model cheklovlarga javob beradigan qiymatlar orasidan sampling qiladi. Eslatib o'tamiz, tokenni generatsiya qilish uchun modelingiz avval logit vektorini chiqaradi, bunda har bir logit bitta mumkin bo'lgan tokenga mos keladi. Cheklangan sampling faqat cheklovlarga javob beradigan tokenlarni saqlab qolish uchun ushbu logit vektorini filtrlaydi. So'ngra u aynan shu yaroqli tokenlardan sampling qiladi. Bu jarayon 2-21-rasmda ko'rsatilgan.
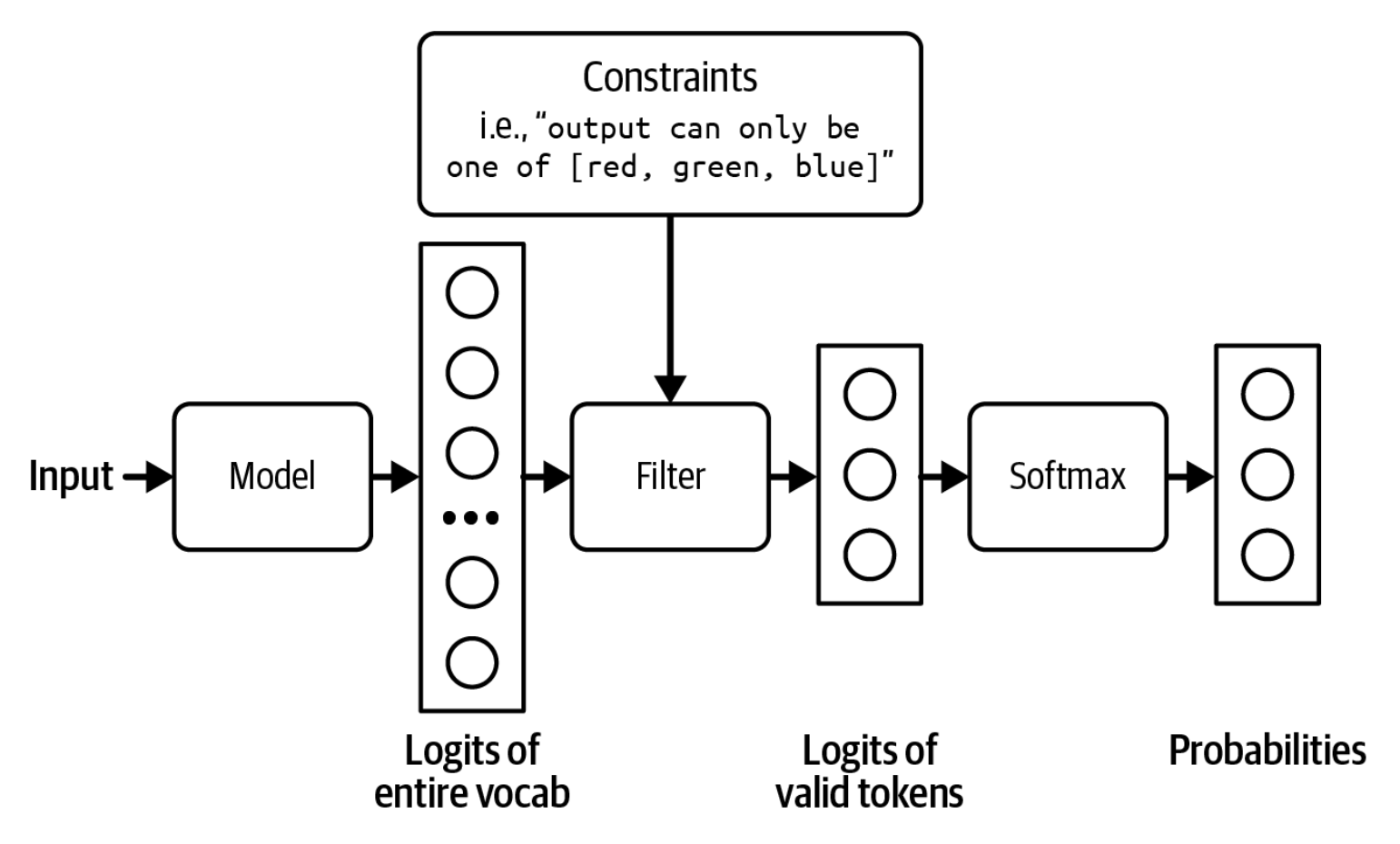
2-21-rasmdagi misolda cheklovni filtrlash oson. Biroq, aksariyat holatlar bunchalik oddiy emas. Sizga har bir qadamda nimaga ruxsat berilgani va nimaga ruxsat berilmaganini belgilaydigan grammatika (grammar) kerak bo'ladi. Masalan, JSON grammatikasi { belgisidan keyin, agar u {"key": "{{string}}"} kabi satrning bir qismi bo'lmasa, yana bir { kelishi mumkin emasligini belgilaydi.
Bu grammatikani yaratish va uni sampling jarayoniga kiritish oson ish emas. Har bir natija formati — JSON, YAML, regex, CSV va hokazolar — o'z grammatikasini talab qilgani uchun, cheklangan sampling kamroq umumlashtiriladigan (less generalizable) yondashuvdir. Uning qo'llanilishi tashqi vositalar yoki sizning jamoangiz tomonidan qo'llab-quvvatlanadigan grammatikali formatlar bilan cheklangan. Grammatikani tekshirish, shuningdek, generatsiya kechikishini oshirishi ham mumkin (Brandon T. Willard, 2024).
Ba'zilar cheklangan sampling'ga qarshi, chunki ular cheklangan sampling uchun zarur bo'lgan resurslarni modellarni ko'rsatmalarga amal qilishda yaxshiroq bo'lishga o'rgatishga sarflash afzalroq, deb hisoblashadi.
Finetuning
Modelni siz xohlagan formatga rioya qiladigan misollarda finetuning — bu modellarni ushbu formatda natija generatsiya qilishga undashning eng samarali va umumiy yondashuvidir.11 U istalgan kutilayotgan format bilan ishlay oladi. Garchi oddiy finetuning model har doim kutilgan formatni chiqarishini kafolatlamasa-da, u promptlashga qaraganda ancha ishonchliroqdir.
Muayyan vazifalar uchun, siz finetuning'dan oldin model arxitekturasini o'zgartirish orqali natija formatini kafolatlashingiz mumkin. Masalan, tasniflash uchun, model faqat oldindan belgilangan sinflardan birini chiqarishiga ishonch hosil qilish uchun, siz fundamental model arxitekturasiga klassifikator boshi (classifier head) qo'shishingiz mumkin. Arxitektura 2-22-rasmdagidek ko'rinadi.12 Bu yondashuv, shuningdek, xususiyatlarga asoslangan transfer (feature-based transfer) deb ham ataladi va 7-bobda boshqa transferli o'rganish (transfer learning) texnikalari bilan birga batafsilroq muhokama qilinadi.
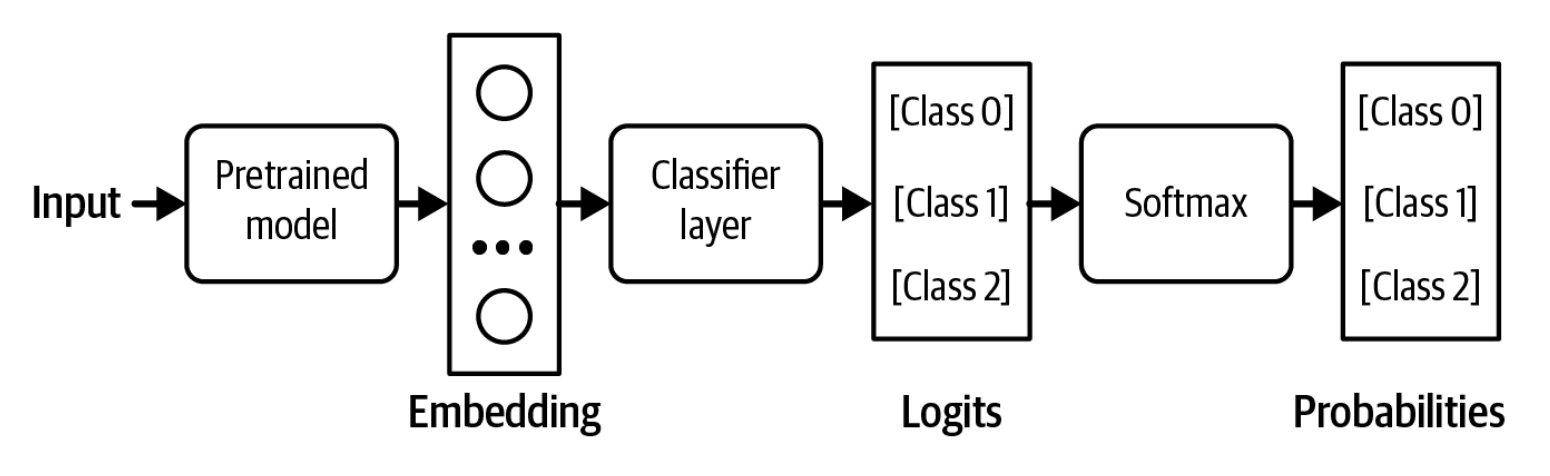
Finetuning davomida siz butun modelni boshidan oxirigacha yoki modelning bir qismini, masalan, ushbu klassifikator boshini qayta o'qitishingiz mumkin. Boshidan oxirigacha o'qitish ko'proq resurs talab qiladi, lekin yaxshiroq samaradorlikni va'da qiladi.
Bizga strukturalashgan natijalar uchun texnikalar kerakligining sababi — bu modelning o'zi strukturalashgan natijalarni generatsiya qilishga qodir emas degan farazdir. Biroq, modellar qudratliroq bo'lib borgani sari, ularning ko'rsatmalarga amal qilishda yaxshilanib borishini kutishimiz mumkin. Taxminimcha, kelajakda minimal promptlash bilan modellardan aynan bizga kerak bo'lgan narsani chiqarib olish osonlashadi va bu texnikalar kamroq ahamiyatga ega bo'lib qoladi.
SI'ning ehtimollik tabiati
SI modellarining o'z javoblarini sampling qilish usuli ularni ehtimollikka asoslangan (probabilistic) qiladi. Keling, ehtimollikka asoslangan bo'lish nimani anglatishini ko'rish uchun bir misolni ko'rib chiqaylik. Tasavvur qiling, siz dunyodagi eng yaxshi oshxona qaysi ekanligini bilmoqchisiz. Agar siz do'stingizga bu savolni bir daqiqa farq bilan ikki marta bersangiz, do'stingizning javobi har ikkala safar ham bir xil bo'lishi kerak. Agar siz xuddi shu savolni SI modeliga ikki marta bersangiz, uning javobi o'zgarishi mumkin. Agar SI modeli Vyetnam oshxonasi dunyodagi eng yaxshi oshxona bo'lish ehtimoli 70%, Italyan oshxonasi esa 30% deb hisoblasa, u 70% hollarda "Vyetnam oshxonasi" va 30% hollarda "Italyan oshxonasi" deb javob beradi. Ehtimollikka asoslanganlikning aksi — bu deterministik (deterministic) bo'lib, bunda natijani hech qanday tasodifiy o'zgarishlarsiz aniqlash mumkin bo'ladi.
Ushbu ehtimollikka asoslangan tabiat nomuvofiqlik (inconsistency) va gallyutsinatsiyalarga sabab bo'lishi mumkin. Nomuvofiqlik — bu modelning bir xil yoki biroz farq qiladigan promptlar uchun juda xilma-xil javoblar generatsiya qilishidir. Gallyutsinatsiya — bu modelning faktlarga asoslanmagan javob berishidir. Tasavvur qiling, kimdir internetda barcha AQSH prezidentlari o'zga sayyoraliklar ekanligi haqida insho yozgan va bu insho o'qitish ma'lumotlariga kiritilgan. Keyinchalik model ehtimollikka asoslanib, hozirgi AQSH prezidenti o'zga sayyoralik ekanligini chiqarib berishi mumkin. AQSH prezidentlari o'zga sayyoralik ekanligiga ishonmaydigan odam nuqtai nazaridan, model buni o'zidan to'qib chiqarmoqda.
Fundamental modellar odatda juda katta hajmdagi ma'lumotlar yordamida o'qitiladi. Ular omma fikrlarining yig'indisi bo'lib, o'z ichiga, so'zning tom ma'nosida, imkoniyatlar dunyosini qamrab oladi. Noldan farqli ehtimollikka ega bo'lgan har qanday narsa, qanchalik aql bovar qilmas yoki noto'g'ri bo'lmasin, SI tomonidan generatsiya qilinishi mumkin.13
Bu xususiyat SI ilovalarini yaratishni ham hayajonli, ham qiyin jarayonga aylantiradi. Ushbu kitobda ko'radiganimizdek, SI muhandisligidagi ko'plab sa'y-harakatlar aynan shu ehtimollikka asoslangan tabiatni jilovlash va yumshatishga qaratilgan.
Ehtimollikka asoslanganlik SI'ni ijodiy vazifalar uchun ajoyib vositaga aylantiradi. Ijodkorlikning o'zi nima, agar u odatiy yo'llardan tashqariga chiqish — qolipdan tashqari fikrlash qobiliyati bo'lmasa? SI ijodkor mutaxassislar uchun ajoyib hamrohdir. U cheksiz g'oyalarni o'rtaga tashlashi (brainstorm) va ilgari ko'rilmagan dizaynlarni yaratishi mumkin. Biroq, xuddi shu ehtimollikka asoslangan tabiat boshqa barcha sohalar uchun bosh og'riq bo'lishi mumkin.14
Nomuvofiqlik
Model nomuvofiqligi (inconsistency) ikki holatda namoyon bo'ladi:
- Bir xil kirish, har xil natija: Modelga bir xil promptni ikki marta berish ikki xil javobga olib keladi.
- Ozroq farqli kirish, keskin farqli natija: Modelga biroz farq qiladigan prompt berish, masalan, tasodifan biror harfni katta harf bilan yozib yuborish, butunlay boshqa natijaga olib kelishi mumkin.
2-23-rasmda men ChatGPT'dan insholarni baholash uchun foydalanishga uringanim misoli ko'rsatilgan. Bir xil prompt uni ikki marta ishga tushirganimda menga ikki xil ball berdi: 3/5 va 5/5.

Nomuvofiqlik foydalanuvchida yoqimsiz taassurot qoldirishi mumkin. Insonlar o'rtasidagi muloqotda biz ma'lum darajada izchillikni kutamiz. Tasavvur qiling, bir odam har safar ko'rishganingizda sizga o'zini har xil ism bilan tanishtirsa. Xuddi shunday, foydalanuvchilar ham SI bilan muloqot qilishda ma'lum darajadagi izchillikni kutadilar.
Nomuvofiqlikni yumshatish usullari
"Bir xil kirish, har xil natija" holati uchun nomuvofiqlikni yumshatishning bir nechta yondashuvlari mavjud. Siz javobni keshlashingiz mumkin, shunda keyingi safar xuddi shu savol berilganda, o'sha javob qaytariladi. Avvalroq muhokama qilinganidek, modelning sampling parametrlarini, masalan, temperature, top-p va top-k qiymatlarini qat'iy belgilashingiz mumkin. Shuningdek, seed o'zgaruvchisini (tasodifiy sonlar generatori uchun boshlang'ich nuqtani) ham qat'iy belgilashingiz mumkin, uni keyingi tokenni sampling qilish uchun ishlatiladigan tasodifiy sonlar generatorining boshlang'ich nuqtasi deb hisoblashingiz mumkin.
Biroq, siz bu barcha o'zgaruvchilarni qat'iy belgilasangiz ham, modelingiz 100% hollarda izchil bo'lishiga kafolat yo'q. Model natijani generatsiya qiladigan qurilma ham natijaga ta'sir qilishi mumkin, chunki turli xil mashinalar bir xil ko'rsatmani bajarishning turli usullariga ega va turli diapazondagi sonlar bilan ishlay oladi. Agar siz o'z modelingizni o'z serveringizda ishlatsangiz, siz foydalanadigan qurilma ustidan biroz nazoratga ega bo'lasiz. Biroq, agar siz OpenAI yoki Google kabi model API provayderidan foydalansangiz, sizga biror nazorat berish yoki bermaslik bu provayderlarga bog'liq.
Natija generatsiyasi sozlamalarini qat'iy belgilash yaxshi amaliyot, ammo bu tizimga ishonch uyg'otmaydi. Tasavvur qiling, bir o'qituvchi sizga faqat ma'lum bir xonada o'tirgandagina barqaror baho qo'ysa. Agar o'sha o'qituvchi boshqa xonada o'tirsa, uning sizga qo'yadigan baholari tartibsiz bo'lib ketadi.
Ikkinchi holat — "ozroq farqli kirish, keskin farqli natija" — ancha qiyinroq. Modelning natija generatsiyasi parametrlarini qat'iy belgilash hali ham yaxshi amaliyot, ammo bu modelni turli kirishlar uchun bir xil natijalarni generatsiya qilishga majburlamaydi. Biroq, puxta ishlab chiqilgan promptlar (5-bobda muhokama qilinadi) va xotira tizimi (6-bobda muhokama qilinadi) yordamida modellarni siz xohlagan javoblarga yaqinroq natijalar generatsiya qilishga undash mumkin.
Gallyutsinatsiya
Gallyutsinatsiyalar faktlarga asoslanadigan vazifalar uchun halokatli bo'lishi mumkin. Agar siz SI'dan biror vaksinaning ijobiy va salbiy tomonlarini tushuntirishda yordam so'rasangiz, SI'ning soxta ilmiy ma'lumot berishini xohlamaysiz. 2023-yil iyun oyida bir advokatlik firmasi sudga to'qima huquqiy tadqiqot taqdim etgani uchun jarimaga tortildi. Ular o'z ishlarini tayyorlashda ChatGPT'dan foydalanishgan, ammo uning gallyutsinatsiyaga moyilligidan bexabar bo'lishgan.
Zero gallyutsinatsiya LLM'larning yuksalishi bilan mashhur muammoga aylangan bo'lsa-da, u "fundamental model" atamasi va Transformer arxitekturasi paydo bo'lishidan oldin ham generativ modellar uchun keng tarqalgan hodisa edi. Matn generatsiyasi kontekstida gallyutsinatsiya 2016-yildayoq tilga olingan (Goyal va boshq., 2016). Gallyutsinatsiyalarni aniqlash va o'lchash o'shandan beri tabiiy til generatsiyasining (NLG) asosiy qismi bo'lib kelmoqda (qarang: Lee va boshq., 2018; Nie va boshq., 2019; va Zhou va boshq., 2020). Ushbu bo'limda gallyutsinatsiyalar nima uchun sodir bo'lishini tushuntirishga e'tibor qaratiladi. Ularni qanday aniqlash va o'lchash esa 4-bobda muhokama qilinadi.
Agar nomuvofiqlik sampling jarayonidagi tasodifiylikdan kelib chiqsa, gallyutsinatsiyaning sababi ancha murakkabroq. Faqat sampling jarayonining o'zi buni yetarlicha tushuntirib bera olmaydi. Model barcha ehtimoliy variantlar orasidan natijalarni sampling qiladi (tanlab oladi). Lekin qanday qilib ilgari hech qachon ko'rilmagan narsa ehtimoliy variantga aylanib qoladi? Model o'qitish ma'lumotlarida hech qachon uchramagan deb ishoniladigan narsani chiqarib berishi mumkin. Biz buni aniq ayta olmaymiz, chunki o'qitish ma'lumotlari ichida biror g'oya bor-yo'qligini tekshirish uchun ularni elakdan o'tkazib chiqishning iloji yo'q. O'zimiz tushuna olmaydigan darajada murakkab narsani yarata olish qobiliyatimiz — bu tayoqning ikki uchiga o'xshaydi.
Gallyutsinatsiya sabablari haqidagi gipotezalar
Nima uchun gallyutsinatsiyalar yuzaga kelishini tushunmasdan turib, ularni yo'q qilish yo'lini topish qiyin. Hozirda til modellari nima uchun gallyutsinatsiyaga uchrashi haqida ikkita gipoteza mavjud.
Birinchi gipoteza, dastlab DeepMind'dagi Ortega va boshqalar tomonidan 2021-yilda ilgari surilgan bo'lib, shundan iboratki, til modeli o'ziga berilgan ma'lumotlar va o'zi generatsiya qilgan ma'lumotlarni farqlay olmagani uchun gallyutsinatsiyaga uchraydi. Buni tasvirlash uchun bir misolni ko'rib chiqamiz.
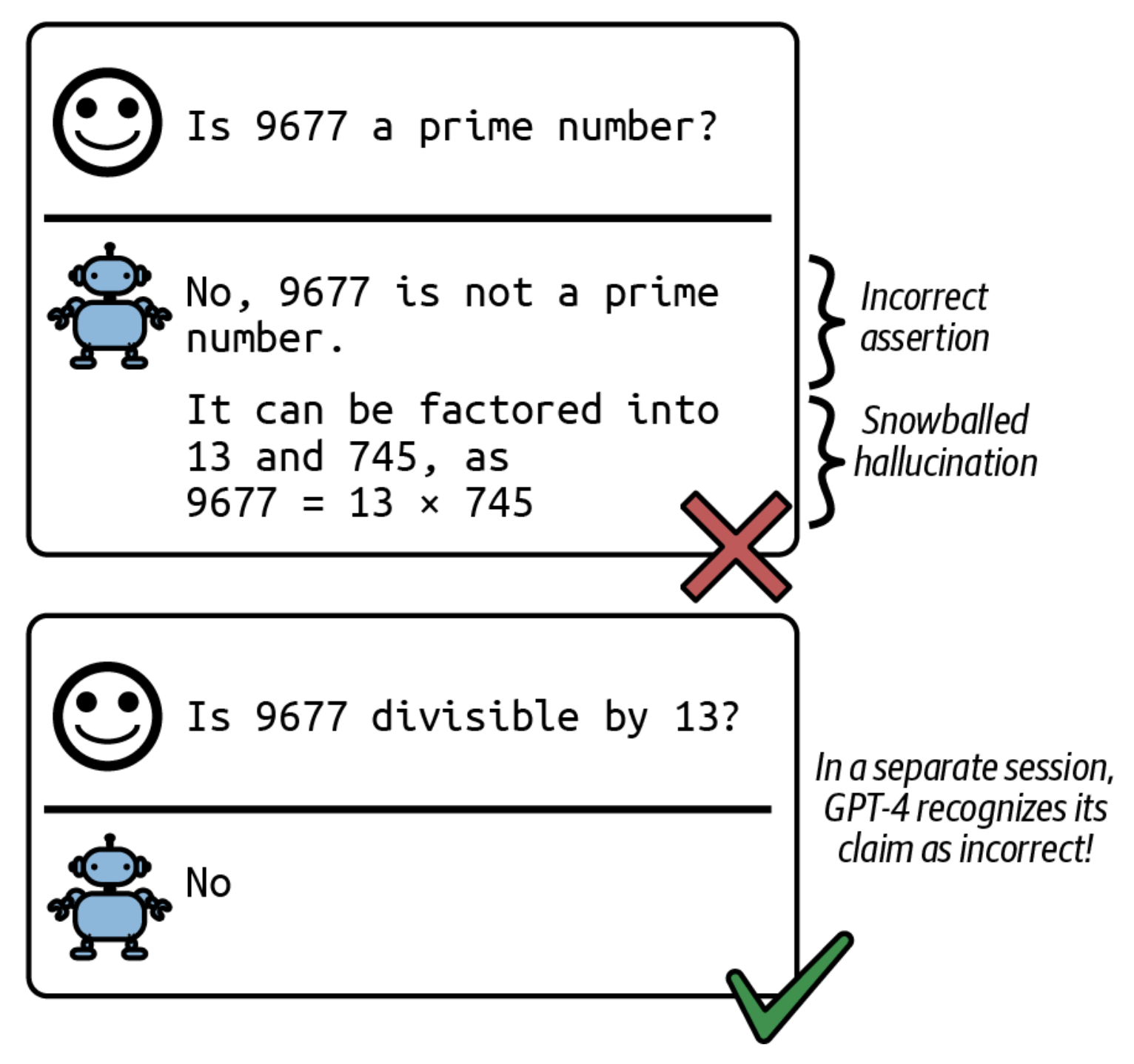
Tasavvur qiling, siz modelga "Chip Huyen kim?" degan prompt berasiz va model generatsiya qilgan birinchi jumla: "Chip Huyen — me'mor." Model generatsiya qiladigan keyingi token "Chip Huyen kim? Chip Huyen — me'mor." ketma-ketligiga asoslanadi. Model o'zi yaratgan "Chip Huyen — me'mor." jumlasiga xuddi berilgan faktdek munosabatda bo'ladi. Odatdagidan biroz chetga chiqqan generatsiya qilingan ketma-ketlikdan boshlab, model uni kengaytirishi va mutlaqo noto'g'ri faktlarni generatsiya qilishi mumkin. Ortega va boshqa mualliflar gallyutsinatsiyalarni o'z-o'zini aldashning bir shakli deb atashgan.
2-24-rasmda LLaVA-v1.5-7B modelining o'z-o'zini aldashiga misol ko'rsatilgan. Men modeldan rasmdagi mahsulot yorlig'ida ko'rsatilgan tarkibini aniqlashni so'radim, bu shampun idishi edi. O'z javobida model rasmdagi mahsulot sut idishi ekanligiga o'zini ishontiradi, so'ngra mahsulot yorlig'idan olingan tarkiblar ro'yxatiga sutni qo'shishda davom etadi.

LLaVA-v1.5-7B modelining o'z-o'zini aldashiga misol.Zhang va boshqalar (2023) bu hodisani qor uyumi gallyutsinatsiyalari (snowballing hallucinations) deb atashadi. Bir marta noto'g'ri taxmin qilgandan so'ng, model o'zining dastlabki xatosini oqlash uchun gallyutsinatsiya qilishda davom etishi mumkin. Qizig'i shundaki, mualliflar 2-25-rasmda ko'rsatilganidek, dastlabki noto'g'ri taxminlar modelning boshqa holatda to'g'ri javob bera oladigan savollarida ham xato qilishiga sabab bo'lishi mumkinligini ko'rsatadilar.
DeepMind maqolasi gallyutsinatsiyalarni ikkita texnika yordamida yumshatish mumkinligini ko'rsatdi. Birinchi texnika mustahkamlovchi o'rganishdan kelib chiqadi, unda model foydalanuvchi tomonidan taqdim etilgan promptlar (mustahkamlovchi o'rganishda dunyo haqidagi kuzatuvlar deb ataladi) va model tomonidan generatsiya qilingan tokenlar (modelning harakatlari deb ataladi) o'rtasidagi farqni ajratishga majbur qilinadi. Ikkinchi texnika nazoratli o'rganishga tayanadi, unda o'qitish ma'lumotlariga faktik va kontrfaktual signallar kiritiladi.
Ikkinchi gipoteza shundan iboratki, gallyutsinatsiya modelning ichki bilimlari va izohlovchining ichki bilimlari o'rtasidagi nomuvofiqlik tufayli yuzaga keladi. Bu fikrni birinchi bo'lib OpenAI tadqiqotchisi Leo Gao ilgari surgan. SFT davomida modellar izohlovchilar tomonidan yozilgan javoblarga taqlid qilishga o'rgatiladi. Agar bu javoblar izohlovchilar ega bo'lgan, lekin model ega bo'lmagan bilimlardan foydalansa, biz aslida modelni gallyutsinatsiya qilishga o'rgatayotgan bo'lamiz. Nazariy jihatdan, agar izohlovchilar o'zlari yozgan har bir javob bilan birga ishlatgan bilimlarini ham qo'shib kiritishsa, shunda model javoblar to'qib chiqarilmaganini biladi va biz ehtimol modelni faqat o'zi bilgan narsadan foydalanishga o'rgata olamiz. Biroq, bu amalda imkonsizdir.
2023-yil aprel oyida OpenAI hammuassisi Jon Shulman Berklidagi UC ma'ruzasida xuddi shu fikrni bildirdi. Shulman, shuningdek, LLM'lar nimadirni bilish yoki bilmasligini o'zlari biladi, deb hisoblaydi — bu o'z-o'zidan katta da'vo. Agar bu ishonch to'g'ri bo'lsa, gallyutsinatsiyalarni modelni faqat o'zi bilgan ma'lumotlarga asoslanib javob berishga majburlash orqali tuzatish mumkin. U ikkita yechim taklif qildi. Birinchisi — verifikatsiya: har bir javob uchun modeldan ushbu javobga asos bo'lgan manbalarni topib berishni so'rash. Ikkinchisi — mustahkamlovchi o'rganishdan foydalanish. Eslatma uchun, mukofot modeli faqat taqqoslashlar — A javob B javobdan yaxshiroq — yordamida o'qitiladi, nima uchun A yaxshiroq ekanligi tushuntirilmaydi. Shulmanning ta'kidlashicha, modelni biror narsani to'qib chiqargani uchun ko'proq jazolaydigan yaxshiroq mukofot funksiyasi gallyutsinatsiyalarni yumshatishga yordam berishi mumkin.
O'sha ma'ruzada Shulman OpenAI RLHF'ning gallyutsinatsiyalarni kamaytirishga yordam berishini aniqlaganini aytib o'tdi. Biroq, InstructGPT maqolasi RLHF gallyutsinatsiyani yomonlashtirganini ko'rsatadi (2-26-rasm). Garchi RLHF InstructGPT uchun gallyutsinatsiyalarni yomonlashtirganga o'xshasa-da, u boshqa jihatlarni yaxshiladi va umuman olganda, inson izohlovchilari faqat SFT modeliga qaraganda RLHF modelini afzal ko'rishdi.
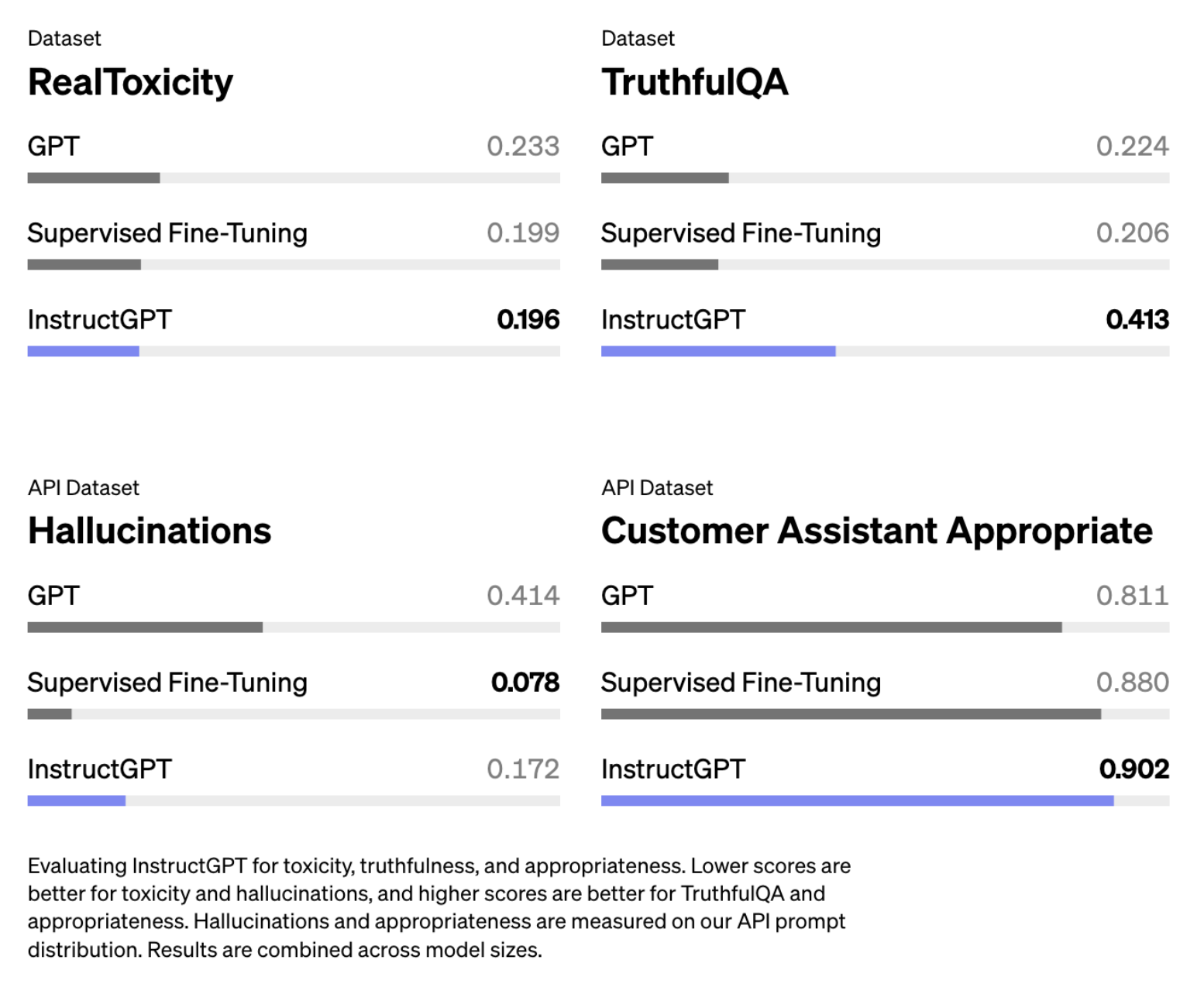
InstructGPT) uchun gallyutsinatsiya faqat SFT ishlatadigan xuddi shu modelga nisbatan yomonroq (Ouyang va boshq., 2022).Fundamental model o'zi nimani bilishini biladi degan taxminga asoslanib, ba'zi odamlar gallyutsinatsiyani promptlar yordamida kamaytirishga harakat qilishadi, masalan, "Iloji boricha haqqoniy javob bering va agar javobga ishonchingiz komil bo'lmasa, 'Kechirasiz, men bilmayman' deb ayting" kabi qo'shimchalar bilan. Modellardan qisqa javoblar so'rash ham gallyutsinatsiyalarga yordam beradiganga o'xshaydi — model qancha kam token generatsiya qilishi kerak bo'lsa, uning biror narsani to'qib chiqarish ehtimoli shunchalik kamayadi. 5 va 6-boblardagi promptlash va kontekstni qurish texnikalari ham gallyutsinatsiyalarni yumshatishga yordam berishi mumkin.
Muhokama qilingan ikkita gipoteza bir-birini to'ldiradi. O'z-o'zini aldash gipotezasi o'z-o'zini nazorat qilish qanday qilib gallyutsinatsiyalarga sabab bo'lishiga e'tibor qaratsa, nomuvofiq ichki bilimlar gipotezasi nazoratli o'qitish qanday qilib gallyutsinatsiyalarga sabab bo'lishiga e'tibor qaratadi.
Agar biz gallyutsinatsiyalarni butunlay to'xtata olmasak, toki biz o'sha gallyutsinatsiyali javoblarni foydalanuvchilarga taqdim etmasakda, hech bo'lmaganda model qachon gallyutsinatsiyaga uchrayotganini aniqlay olamizmi? Xo'sh, gallyutsinatsiyalarni aniqlash ham unchalik oson emas — o'ylab ko'ring, biz uchun boshqa bir inson qachon yolg'on gapirayotganini yoki biror narsani to'qib chiqarayotganini aniqlash qanchalik qiyin. Ammo odamlar harakat qilib ko'rishgan. Biz gallyutsinatsiyalarni qanday aniqlash va o'lchashni 4-bobda muhokama qilamiz.
Izohlar
-
temperaturehaqida o'ylaganimda xayolimga keladigan, unchalik ilmiy bo'lmagan vizual tasvir shuki, yuqoritemperatureehtimollik taqsimotining yanada xaotik bo'lishiga olib keladi, bu esa past ehtimolli tokenlarning yuzaga chiqishiga imkon beradi. ↩ -
underflowmuammosi son berilgan formatda ifodalash uchun juda kichik bo'lganda yuzaga keladi, bu esa uning nolga yaxlitlanishiga olib keladi. ↩ -
Aniqroq aytganda, ushbu kitob yozilayotgan vaqtda, OpenAI API'si sizga faqat 20 tagacha eng ehtimolli tokenlarning logprobs'larini ko'rsatadi. U avval foydalanuvchi tomonidan taqdim etilgan ixtiyoriy matnning logprobs'larini olishga imkon berardi, ammo 2023-yil sentabrda buni to'xtatdi. Anthropic o'z modellarining logprobs'larini oshkor qilmaydi. ↩
-
Pullik model API'lari ko'pincha chiqish tokenlari soni bo'yicha haq oladi. ↩
-
Bir xil kirish uchun bir nechta natija generatsiya qilish xarajatini kamaytirish uchun qilinadigan ishlar bor. Masalan, kirish faqat bir marta qayta ishlanishi va barcha natijalar uchun qayta ishlatilishi mumkin. ↩
-
Ushbu kitob yozilayotgan vaqtda, OpenAI API'sida siz
best_ofparametrini ma'lum bir qiymatga, aytaylik 10 ga, o'rnatib, OpenAI modellaridan 10 xil natija orasidan eng yuqori o'rtacha logprob'ga ega bo'lganini qaytarishni so'rashingiz mumkin. ↩ -
Wang va boshqalar (2023) bu yondashuvni o'z-o'ziga muvofiqlik (self-consistency) deb atashgan. ↩
-
Biroq, mo'rt model bilan qilinadigan eng optimal ish — uni boshqasiga almashtirishdir. ↩
-
Ushbu kitob yozilayotgan vaqtda, dastur va modelga qarab, to'g'ri generatsiya qilingan JSON obyektlarining foizini 0% dan to 90% larning yuqorisigacha bo'lgan oraliqda ko'rdim. ↩
-
Modelni noldan kerakli formatga rioya qiladigan ma'lumotlarda o'qitish ham ishlaydi, ammo bu kitob modellarni noldan ishlab chiqish haqida emas. ↩
-
Ba'zi finetuning xizmatlari buni siz uchun avtomatik ravishda bajaradi. OpenAI'ning finetuning xizmatlari avval o'qitish paytida klassifikator boshi (classifier head) qo'shishga imkon berardi, ammo men yozayotgan vaqtda bu xususiyat o'chirib qo'yilgan. ↩
-
Memda aytilganidek, imkoniyatlar past, lekin hech qachon nolga teng emas. ↩
-
2023-yil dekabr oyida men maslahat beradigan bir SI kompaniyasining uch oylik mijozlarni qo'llab-quvvatlash so'rovlarini ko'rib chiqdim va savollarning beshdan bir qismi SI modellarining nomuvofiqligi bilan bog'liqligini aniqladim. 2023-yil iyul oyida Drew Houston (Dropbox bosh direktori) va Harrison Chase (LangChain bosh direktori) bilan ishtirok etgan panelda biz hammamiz gallyutsinatsiya ko'plab korporativ SI'ning ishlatilish senariylari uchun eng katta to'siq ekanligiga amin bo'ldik. ↩