Modellashtirish
Modelni o'qitishdan oldin, dasturchilar model qanday ko'rinishda bo'lishi kerakligini hal qilishlari kerak. U qanday arxitekturaga amal qilishi kerak? Unda qancha parametr bo'lishi kerak? Bu qarorlar nafaqat modelning imkoniyatlariga, balki uning keyingi dasturlar uchun foydalanishga yaroqliligiga ham ta'sir qiladi.1 Masalan, 7 milliard parametrli modelni joriy etish 175 milliard parametrli modelni joriy etishdan ancha osonroq bo'ladi. Xuddi shunday, Transformer modelini kechikish (latency) uchun optimallashtirish boshqa arxitekturani optimallashtirishdan juda farq qiladi. Keling, bu qarorlar ortidagi omillarni o'rganamiz.
Model arxitekturasi
Ushbu satrlar yozilayotgan vaqtda, tilga asoslangan fundamental modellar uchun eng yetakchi arxitektura — bu diqqat mexanizmiga (attention mechanism) asoslangan Transformer arxitekturasidir (Vaswani va boshq., 2017). U avvalgi arxitekturalarning ko'plab cheklovlarini bartaraf etdi va bu uning mashhurligiga sabab bo'ldi. Biroq, Transformer arxitekturasining ham o'ziga yarasha cheklovlari bor. Ushbu bo'limda Transformer arxitekturasi va uning muqobillari tahlil qilinadi. Bu yerda turli arxitekturalarning texnik tafsilotlariga chuqur kirilishi sababli, matn texnik jihatdan murakkab bo'lishi mumkin. Agar biror qism sizga haddan tashqari mayda-chuydadek tuyulsa, uni bemalol o'tkazib yuborishingiz mumkin.
Transformer arxitekturasi
Transformerni tushunish uchun, keling, u hal qilish uchun yaratilgan muammoga nazar tashlaymiz. Transformer arxitekturasi seq2seq (sequence-to-sequence, ketma-ketlikdan-ketma-ketlikka) arxitekturasining muvaffaqiyati ortidan ommalashdi. 2014-yilda taqdim etilgan vaqtida, seq2seq o'sha paytdagi qiyin vazifalar — mashina tarjimasi va qisqacha bayon qilishda sezilarli yaxshilanishni ta'minlagan edi. 2016-yilda Google seq2seq'ni Google Translate'ga joriy etdi va bu yangilanish ularga "mashina tarjimasi sifatidagi bugungi kungacha bo'lgan eng katta yaxshilanishlarni" berganini da'vo qildi. Bu seq2seq'ga katta qiziqish uyg'otdi va uni matn ketma-ketliklari bilan bog'liq vazifalar uchun asosiy arxitekturaga aylantirdi.
Seq2seq arxitekturasi
Umumiy olganda, seq2seq kirish ma'lumotlarini qayta ishlovchi enkoder (encoder) va natijalarni generatsiya qiluvchi dekoder (decoder)dan iborat. Kirish ham, chiqish ham tokenlar ketma-ketligidan iborat bo'lgani uchun nomi shunday atalgan. Seq2seq o'zining enkoderi va dekoderi sifatida RNN'lardan (recurrent neural networks, qaytalanuvchi neyron to'rlardan) foydalanadi. O'zining eng sodda shaklida enkoder kirish tokenlarini ketma-ket qayta ishlaydi va kirishni ifodalovchi yakuniy yashirin holatni (final hidden state) chiqaradi. So'ngra dekoder kirishning yakuniy yashirin holati va oldin generatsiya qilingan tokenga asoslanib, chiqish tokenlarini ketma-ket generatsiya qiladi. Seq2seq arxitekturasining vizualizatsiyasi 2-4-rasmning yuqori qismida ko'rsatilgan.
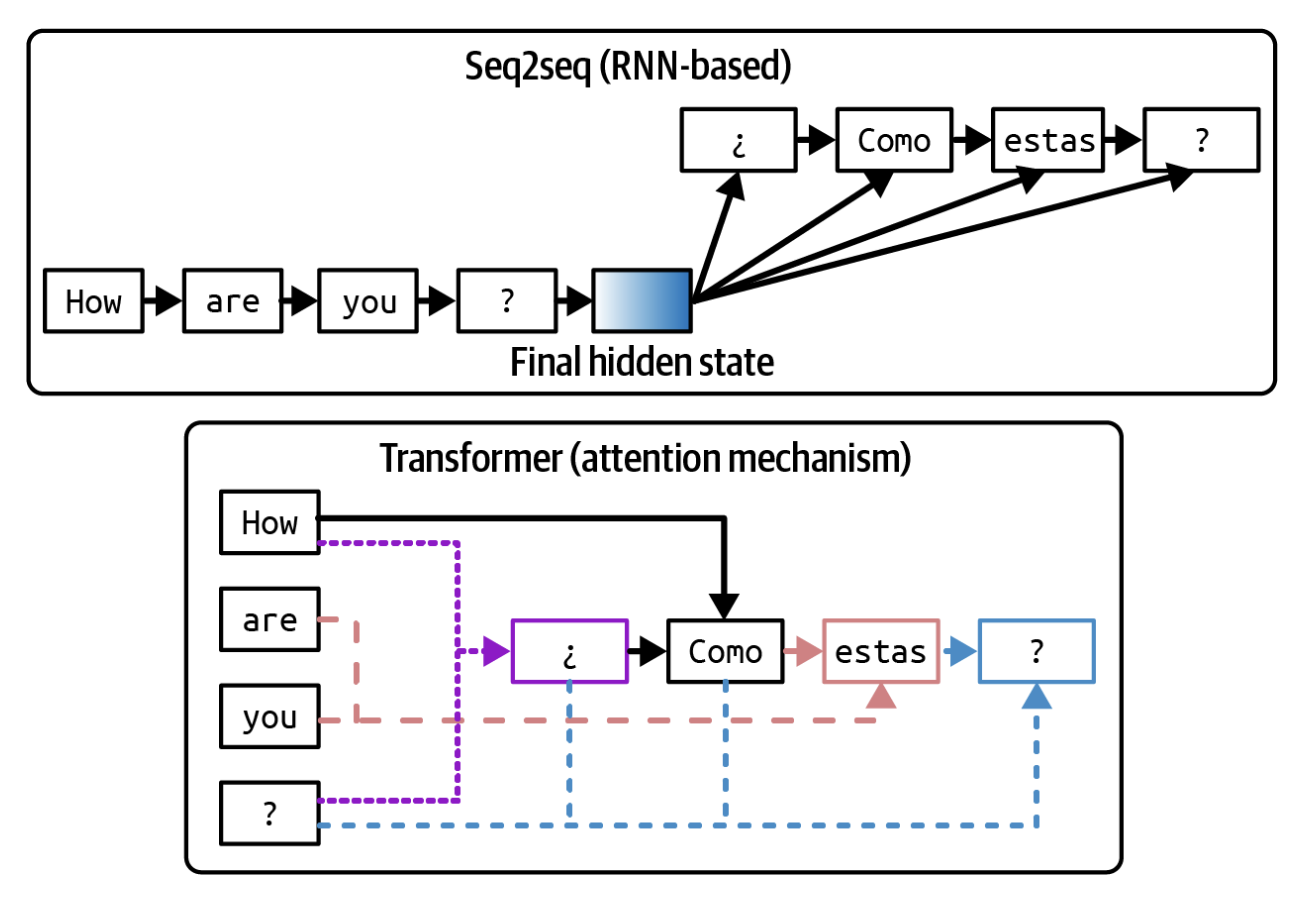
Transformerning afzalliklari
Vaswani va boshqalar (2017) seq2seq'ning ikkita muammosini hal qiladi. Birinchidan, oddiy seq2seq dekoderi chiqish tokenlarini faqat kirishning yakuniy yashirin holatidan foydalanib generatsiya qiladi. Intuitiv ravishda, bu kitob haqidagi savollarga kitobning qisqacha mazmunidan foydalanib javob berishga o'xshaydi. Bu generatsiya qilingan natijalar sifatini cheklaydi. Ikkinchidan, RNN enkoder va dekoderi ham kirishni qayta ishlash, ham chiqishni generatsiya qilish ketma-ket amalga oshirilishini anglatadi, bu esa uni uzun ketma-ketliklar uchun sekinlashtiradi. Agar kirish ma'lumoti 200 token uzunligida bo'lsa, seq2seq keyingisiga o'tishdan oldin har bir kirish tokenining qayta ishlanishini kutishi kerak.2
Transformer arxitekturasi bu ikkala muammoni ham diqqat mexanizmi (attention mechanism) yordamida hal qiladi. Diqqat mexanizmi modelga har bir chiqish tokenini generatsiya qilishda turli kirish tokenlarining muhimligini o'lchash imkonini beradi. Bu xuddi kitobning istalgan sahifasiga havola qilish orqali javob generatsiya qilishga o'xshaydi. Transformer arxitekturasining soddalashtirilgan vizualizatsiyasi 2-4-rasmning pastki yarmida ko'rsatilgan.
Eslatma
Diqqat mexanizmi ko'pincha Transformer modeli bilan bog'lansa-da, u Transformer maqolasidan uch yil oldin taqdim etilgan. Diqqat mexanizmidan boshqa arxitekturalar bilan ham foydalanish mumkin. Google 2016-yilda o'zining GNMT (Google Neyron Mashina Tarjimasi) modeli uchun diqqat mexanizmini seq2seq arxitekturasi bilan birga qo'llagan. Biroq, faqat Transformer maqolasi diqqat mexanizmini RNN'larsiz ham ishlatish mumkinligini ko'rsatganidan keyingina u haqiqiy mashhurlikka erishdi.3
Transformer arxitekturasi RNN'lardan butunlay voz kechadi. Transformerlar yordamida kirish tokenlarini parallel ravishda qayta ishlash mumkin, bu esa kirishni qayta ishlashni sezilarli darajada tezlashtiradi. Transformer ketma-ket kirish bilan bog'liq to'siq (bottleneck)ni bartaraf etsa-da, Transformerga asoslangan avtoregressiv til modellarida ketma-ket chiqish bilan bog'liq to'siq hamon saqlanib qolmoqda.
Transformerda inference jarayoni
Shu sababli, transformerga asoslangan til modellari uchun inference ikki bosqichdan iborat:
-
Oldindan to'ldirish (Prefill) Model kirish tokenlarini parallel ravishda qayta ishlaydi. Bu bosqich birinchi chiqish tokenini generatsiya qilish uchun zarur bo'lgan oraliq holatni yaratadi. Bu oraliq holat barcha kirish tokenlari uchun kalit (key) va qiymat (value) vektorlarini o'z ichiga oladi.
-
Dekodlash (Decode) Model bir vaqtning o'zida bitta chiqish tokenini generatsiya qiladi.
Keyinroq 9-bobda ko'rib chiqiladiganidek, oldindan to'ldirishning parallellashtirilishi mumkin bo'lgan xususiyati va dekodlashning ketma-ketlik jihati til modeli inference'ini arzonroq va tezroq qilishga qaratilgan ko'plab optimallashtirish usullarini qo'llashga undaydi.
Diqqat mexanizmi
Transformer arxitekturasining yuragi — bu diqqat mexanizmidir. Bu mexanizmni tushunish Transformer modellari qanday ishlashini tushunish uchun zarur. Ichki tomondan, diqqat mexanizmi kalit, qiymat va so'rov (query) vektorlaridan foydalanadi:
- So'rov vektori (Q) har bir dekodlash qadamida dekoderning joriy holatini ifodalaydi. O'sha kitob xulosasi misoliga qaytsak, bu so'rov vektorini xulosa yaratish uchun ma'lumot izlayotgan odam deb o'ylash mumkin.
- Har bir kalit vektori (K) oldingi tokenni ifodalaydi. Agar har bir oldingi token kitobdagi bir sahifa bo'lsa, har bir kalit vektori sahifa raqamiga o'xshaydi. Shuni unutmaslik lozimki, ma'lum bir dekodlash qadamida oldingi tokenlar kirish tokenlarini ham, oldin generatsiya qilingan tokenlarni ham o'z ichiga oladi.
- Har bir qiymat vektori (V) model tomonidan o'rganilgan oldingi tokenning haqiqiy qiymatini ifodalaydi. Har bir qiymat vektori sahifaning mazmuniga o'xshaydi.
Diqqat mexanizmi biror kirish tokeniga qancha e'tibor qaratish kerakligini so'rov vektori va uning kalit vektori o'rtasida skalyar ko'paytmani (dot product) bajarish orqali hisoblaydi. Yuqori ball model kitobning qisqacha mazmunini generatsiya qilishda o'sha sahifa mazmunidan (uning qiymat vektoridan) ko'proq foydalanishini anglatadi. Kalit, qiymat va so'rov vektorlari bilan diqqat mexanizmining vizualizatsiyasi 2-5-rasmda ko'rsatilgan. Ushbu vizualizatsiyada so'rov vektori keyingi tokenni generatsiya qilish uchun oldingi How, are, you, ?, ¿ tokenlaridan ma'lumot izlamoqda.
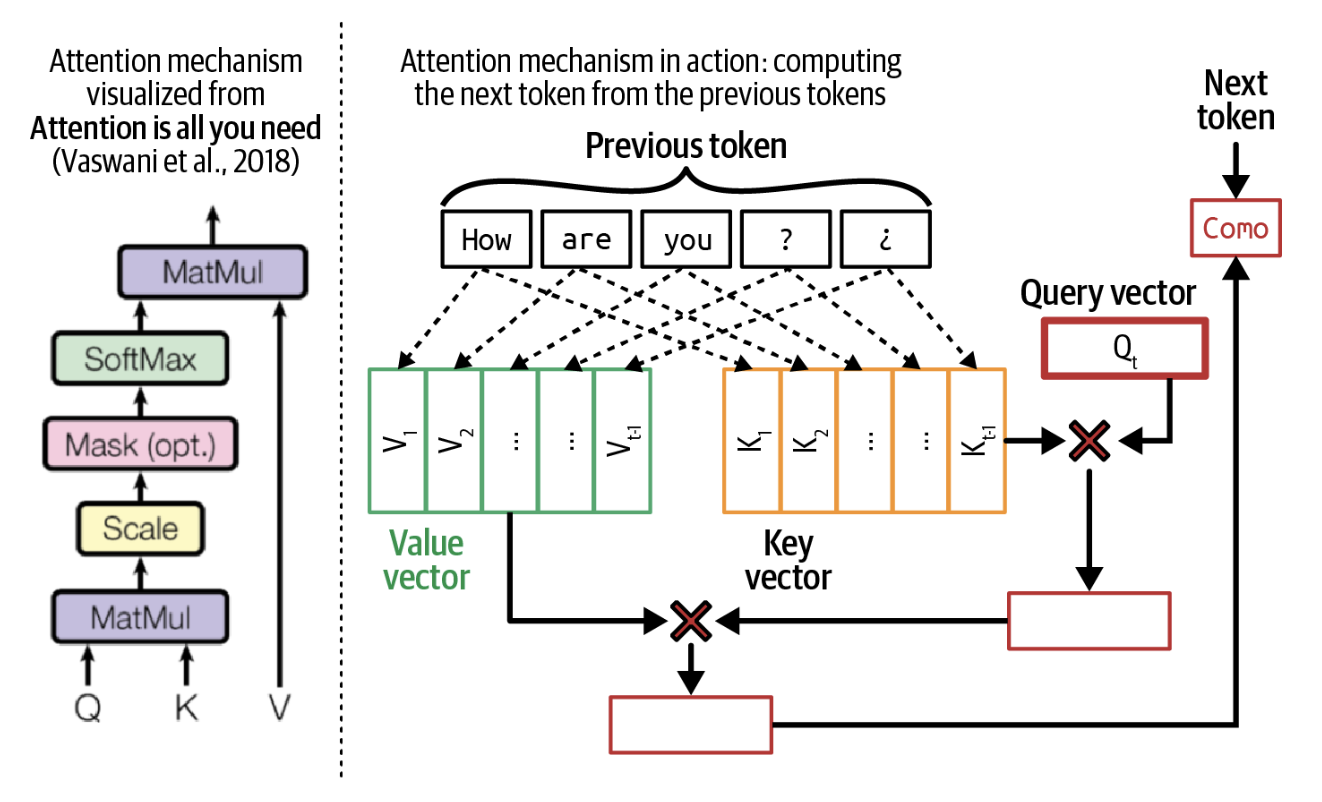
Har bir oldingi token mos keladigan kalit va qiymat vektoriga ega bo'lgani uchun, ketma-ketlik qanchalik uzun bo'lsa, shuncha ko'p kalit va qiymat vektorlarini hisoblash va saqlash kerak bo'ladi. Bu Transformer modellari uchun kontekst uzunligini kengaytirish bunchalik qiyin bo'lishining sabablaridan biridir. Kalit va qiymat vektorlarini qanday qilib samarali hisoblash va saqlash masalasi 7 va 9-boblarda yana ko'rib chiqiladi.
Keling, diqqat funksiyasi qanday ishlashini ko'rib chiqamiz. x kirish ma'lumoti berilganda, kalit, qiymat va so'rov vektorlari kirish ma'lumotiga kalit, qiymat va so'rov matritsalarini qo'llash orqali hisoblanadi. Wₖ, Wᵥ va Wᵩ'ni kalit, qiymat va so'rov matritsalari deb olaylik. Kalit, qiymat va so'rov vektorlari quyidagicha hisoblanadi:
So'rov, kalit va qiymat matritsalari modelning yashirin o'lchami (hidden dimension)ga mos keladigan o'lchamlarga ega. Masalan, Llama 2-7B'da (Touvron va boshq., 2023) modelning yashirin o'lchami 4096 ga teng, ya'ni bu matritsalarning har biri 4096 × 4096 o'lchamiga ega. Har bir hosil bo'lgan K, V, Q vektori 4096 o'lchamiga ega bo'ladi.4
Diqqat mexanizmi deyarli har doim ko'p boshli (multi-headed) bo'ladi. Ko'p boshlilik modelga bir vaqtning o'zida oldingi tokenlarning turli guruhlariga e'tibor qaratish imkonini beradi.Ko'p boshli diqqat mexanizmida so'rov, kalit va qiymat vektorlari har biri bitta diqqat boshiga mos keladigan kichikroq vektorlarga bo'linadi. Llama 2-7B misolida, u 32 ta diqqat boshiga ega bo'lgani uchun, har bir K, V va Q vektori 128 o'lchamli 32 ta vektorga bo'linadi. Buning sababi 4096 / 32 = 128.
Keyin barcha diqqat boshlarining natijalari birlashtiriladi (concatenated). Chiqish proeksiya matritsasi (output projection matrix) bu birlashtirilgan natijaga, u modelning keyingi hisoblash bosqichiga uzatilishidan oldin, yana bir o'zgartirishni qo'llash uchun ishlatiladi. Chiqish proeksiya matritsasi modelning yashirin o'lchami bilan bir xil o'lchamga ega.
Transformer bloki
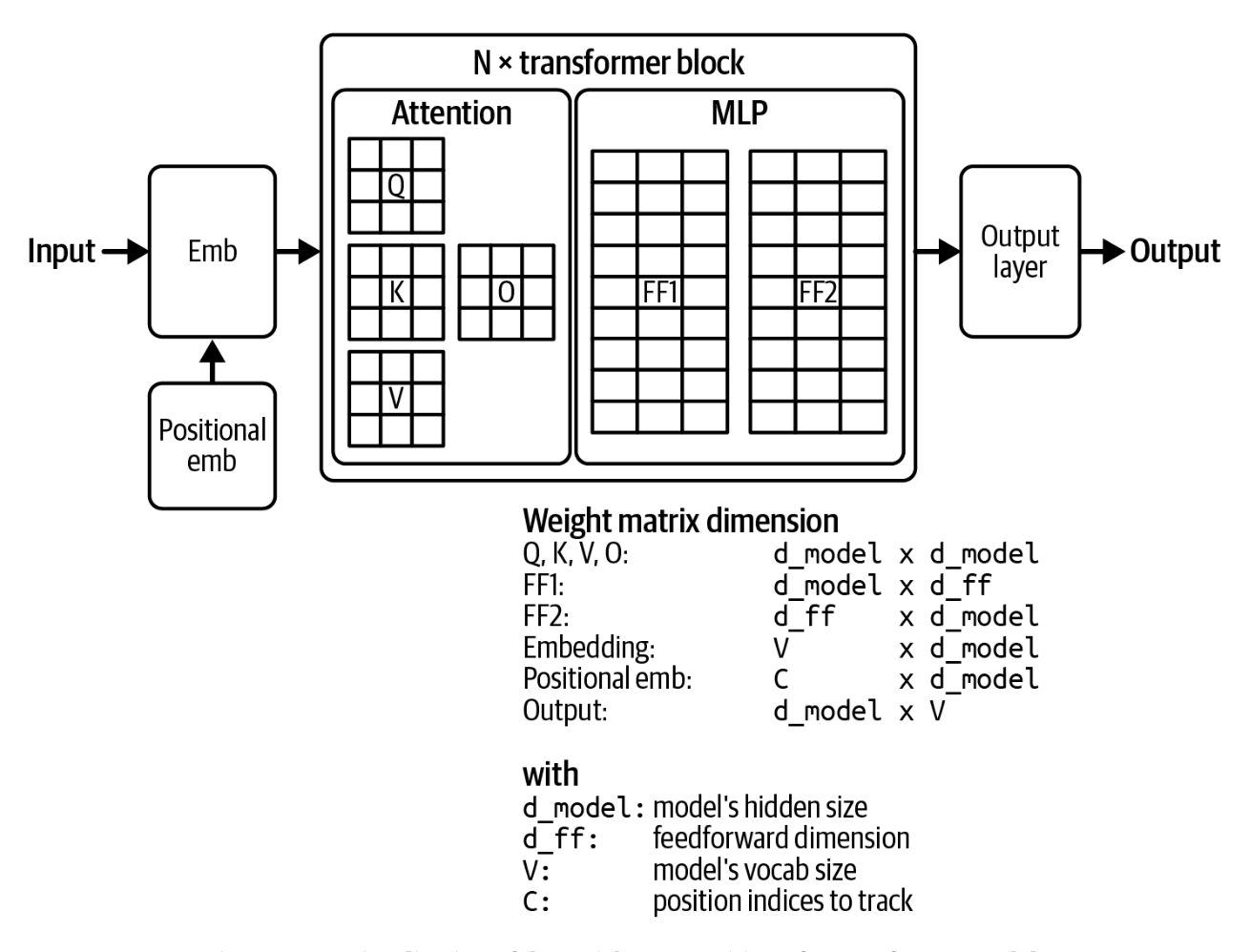
Endi diqqat mexanizmi qanday ishlashini muhokama qilganimizdan so'ng, keling, uning modelda qanday ishlatilishini ko'rib chiqamiz. Transformer arxitekturasi bir nechta Transformer bloklaridan tashkil topgan. Blokning aniq tarkibi modellar orasida farq qiladi, lekin umuman olganda, har bir Transformer bloki diqqat moduli va MLP (ko'p qatlamli perseptron) modulini o'z ichiga oladi:
-
Diqqat moduli: Har bir diqqat moduli to'rtta og'irlik (weight) matritsasidan iborat: so'rov, kalit, qiymat va chiqish proeksiyasi.
-
MLP moduli: MLP moduli chiziqli bo'lmagan aktivatsiya funksiyalari bilan ajratilgan chiziqli qatlamlardan iborat. Har bir chiziqli qatlam chiziqli o'zgartirishlar uchun ishlatiladigan og'irlik matritsasidir, aktivatsiya funksiyasi esa chiziqli qatlamlarga chiziqli bo'lmagan andozalarni o'rganish imkonini beradi. Chiziqli qatlam, shuningdek, to'g'ridan-to'g'ri tarqaluvchi qatlam (feedforward layer) deb ham ataladi.
Keng tarqalgan chiziqli bo'lmagan funksiyalar ReLU (To'g'rilangan Chiziqli Birlik) (Agarap, 2018) va GELU (Hendrycks va Gimpel, 2016) bo'lib, ular mos ravishda
GPT-2vaGPT-3tomonidan ishlatilgan. Aktivatsiya funksiyalari juda oddiy.5 Masalan, ReLU qiladigan yagona ish — bu manfiy qiymatlarni 0 ga aylantirish. Matematik jihatdan u quyidagicha yoziladi:
Transformer modelining umumiy tuzilishi
Transformer modelidagi Transformer bloklari soni ko'pincha o'sha modelning qatlamlari soni deb ataladi. Transformerga asoslangan til modeli, shuningdek, barcha Transformer bloklaridan oldin va keyin joylashgan modullar bilan jihozlangan bo'ladi:
-
Transformer bloklaridan oldingi embedding moduli: Bu modul embedding matritsasi va pozitsion embedding matritsasidan iborat bo'lib, ular mos ravishda tokenlarni va ularning pozitsiyalarini embedding vektorlariga aylantiradi. Soddaroq aytganda, pozitsiya indekslari soni modelning maksimal kontekst uzunligini belgilaydi. Masalan, agar model 2048 ta pozitsiyani kuzatib borsa, uning maksimal kontekst uzunligi 2048 ga teng bo'ladi. Biroq, pozitsiya indekslari sonini oshirmasdan modelning kontekst uzunligini oshiradigan texnikalar ham mavjud.
-
Transformer bloklaridan keyingi chiqish qatlami: Bu modul modelning chiqish vektorlarini model natijalarini sampling qilish uchun ishlatiladigan token ehtimolliklariga o'tkazadi ("Sampling" bo'limida muhokama qilinadi). Bu modul odatda bitta matritsadan iborat bo'lib, u unembedding qatlami deb ham ataladi. Ba'zi odamlar chiqish qatlamini model boshi (model head) deb atashadi, chunki u natija generatsiyasidan oldingi modelning so'nggi qatlamidir.
2-6-rasmda Transformer model arxitekturasi vizualizatsiya qilingan. Transformer modelining hajmi uning qurilish bloklarining o'lchamlari bilan belgilanadi. Ba'zi asosiy qiymatlar quyidagilardir:
- Modelning o'lchami Transformer blokidagi kalit, so'rov, qiymat va chiqish proeksiya matritsalarining o'lchamlarini belgilaydi.
- Transformer bloklari soni.
- To'g'ridan-to'g'ri tarqaluvchi qatlamning o'lchami.
- Lug'at hajmi.
Kattaroq o'lcham qiymatlari model hajmining kattalashishiga olib keladi. 2-4-jadvalda turli Llama 2 (Touvron va boshq., 2023) va Llama 3 (Dubey va boshq., 2024) modellari uchun ushbu o'lcham qiymatlari ko'rsatilgan. E'tibor bering, kontekst uzunligining oshishi modelning xotiradagi iziga (memory footprint) ta'sir qilsa-da, u modelning umumiy parametrlar soniga ta'sir qilmaydi.
| Model | # Transformer bloklari | Model o'lchami | Feedforward o'lchami | Lug'at hajmi | Kontekst uzunligi |
|---|---|---|---|---|---|
Llama 2-7B | 32 | 4,096 | 11,008 | 32K | 4K |
Llama 2-13B | 40 | 5,120 | 13,824 | 32K | 4K |
Llama 2-70B | 80 | 8,192 | 22,016 | 32K | 4K |
Llama 3-8B | 32 | 4,096 | 14,336 | 128K | 8K |
Llama 3-70B | 80 | 8,192 | 28,672 | 128K | 8K |
Llama 3-405B | 126 | 16,384 | 53,248 | 128K | 128K |
Llama modellarining o'lcham qiymatlari.Boshqa model arxitekturalari
Garchi Transformer modeli sohada peshqadam bo'lsa-da, u yagona arxitektura emas. 2012-yilda AlexNet chuqur o'rganishga bo'lgan qiziqishni qayta jonlantirganidan beri ko'plab arxitekturalar urfga kirdi va yana urfdan qoldi. seq2seq to'rt yil davomida (2014–2018) diqqat markazida bo'ldi. GAN'lar (generativ raqobatchi tarmoqlar) jamoatchilik tasavvurini biroz uzoqroq vaqt (2014–2019) zabt etdi. O'zidan oldingi arxitekturalar bilan solishtirganda, Transformer ancha "yashovchan" bo'lib chiqdi. U 2017-yildan beri mavjud.6 Xo'sh, undan yaxshiroq narsa paydo bo'lishiga qancha vaqt qoldi?
Transformerdan ustun keladigan yangi arxitekturani ishlab chiqish oson emas.7 Transformer 2017-yildan beri jadal optimallashtirib kelinmoqda. Transformerning o'rnini egallashni maqsad qilgan yangi arxitektura odamlarni qiziqtiradigan miqyosda va ular ishlatadigan qurilmalarda ishlay olishi kerak bo'ladi.8
Biroq, umid bor. Garchi Transformerga asoslangan modellar hukmronlik qilayotgan bo'lsa-da, ushbu kitob yozilayotgan vaqtda bir nechta muqobil arxitekturalar ommalashib bormoqda.
Transformerga muqobil yondashuvlar
Ommabop modellardan biri bu RWKV (Peng va boshq., 2023) — o'qitish uchun parallellashtirilishi mumkin bo'lgan RNN'ga asoslangan model. O'zining RNN tabiatiga ko'ra, nazariy jihatdan, u Transformerga asoslangan modellardagi kabi kontekst uzunligi chekloviga ega emas. Biroq, amalda, kontekst uzunligi cheklovining yo'qligi uzun kontekst bilan yaxshi ishlashni kafolatlamaydi.
Uzoq ketma-ketliklarni modellashtirish LLM'larni ishlab chiqishdagi asosiy muammo bo'lib qolmoqda. Uzoq masofali xotirada katta istiqbol ko'rsatgan arxitekturalardan biri bu SSM'lardir (holat fazosi modellari) (Gu va boshq., 2021a). Arxitektura 2021-yilda taqdim etilganidan beri uni samaraliroq qilish, uzun ketma-ketliklarni qayta ishlashda yaxshilash va kattaroq model o'lchamlariga miqyoslash uchun bir nechta texnikalar taqdim etildi. Quyida, yangi arxitekturaning evolyutsiyasini ko'rsatish uchun ushbu texnikalarning bir nechtasi keltirilgan:
S4, “Efficiently Modeling Long Sequences with Structured State Spaces” (Gu va boshq., 2021b) maqolasida taqdim etilgan bo'lib, SSM'larni samaraliroq qilish uchun ishlab chiqilgan.H3, “Hungry Hungry Hippos: Towards Language Modeling with State Space Models” (Fu va boshq., 2022) maqolasida taqdim etilgan bo'lib, modelga dastlabki tokenlarni eslab qolish va ketma-ketliklar bo'ylab tokenlarni taqqoslash imkonini beradigan mexanizmni o'z ichiga oladi. Bu mexanizmning maqsadi Transformer arxitekturasidagi diqqat mexanizminikiga o'xshaydi, lekin u samaraliroqdir.Mamba, “Mamba: Linear-Time Sequence Modeling with Selective State Spaces” (Gu va Dao, 2023) maqolasida taqdim etilgan bo'lib, SSM'larni uch milliard parametrga miqyoslaydi. Til modellashtirishdaMamba-3Bo'zining hajmidagi Transformerlardan ustun keladi va o'zidan ikki baravar katta Transformerlarga teng keladi. Mualliflar, shuningdek,Mamba'ning inference hisoblashi ketma-ketlik uzunligi bilan chiziqli miqyoslanishini (Transformerlardagi kvadratik miqyoslanishga nisbatan) ko'rsatadilar. Uning samaradorligi million uzunlikdagi ketma-ketliklargacha bo'lgan real ma'lumotlarda yaxshilanishni ko'rsatadi.Jamba, “Jamba: A Hybrid Transformer–Mamba Language Model” (Lieber va boshq., 2024) maqolasida taqdim etilgan bo'lib, SSM'larni yanada kengroq miqyoslash uchun Transformer vaMambaqatlamlari bloklarini navbatma-navbat joylashtiradi. Mualliflar bitta 80 GB GPU'ga sig'adigan qilib ishlab chiqilgan, jami 52 milliard mavjud parametrga (12 milliard faol parametr) ega bo'lgan expertlar aralashmasi (mixture-of-experts) modelini chiqardilar.Jambastandart til modeli benchmarklarida va 256K (256 ming) tokengacha bo'lgan uzun kontekstli baholashlarda kuchli natijalarni ko'rsatadi. Shuningdek, u oddiy Transformerlarga qaraganda xotirada kam joy egallaydi.
2-7-rasmda Transformer, Mamba va Jamba bloklari vizualizatsiya qilingan.
Transformerdan ustun keladigan arxitekturani ishlab chiqish qiyin bo'lsa-da, uning ko'plab cheklovlarini hisobga olsak, buni qilish uchun juda ko'p rag'batlantiruvchi omillar mavjud. Agar boshqa bir arxitektura haqiqatan ham Transformerdan o'zib ketsa, ushbu kitobda muhokama qilingan ba'zi modelni moslashtirish texnikalari o'zgarishi mumkin. Biroq, xuddi ML muhandisligidan SI muhandisligiga o'tish ko'p narsalarni o'zgarishsiz qoldirganidek, asosdagi model arxitekturasini o'zgartirish ham fundamental yondashuvlarni o'zgartirmaydi.
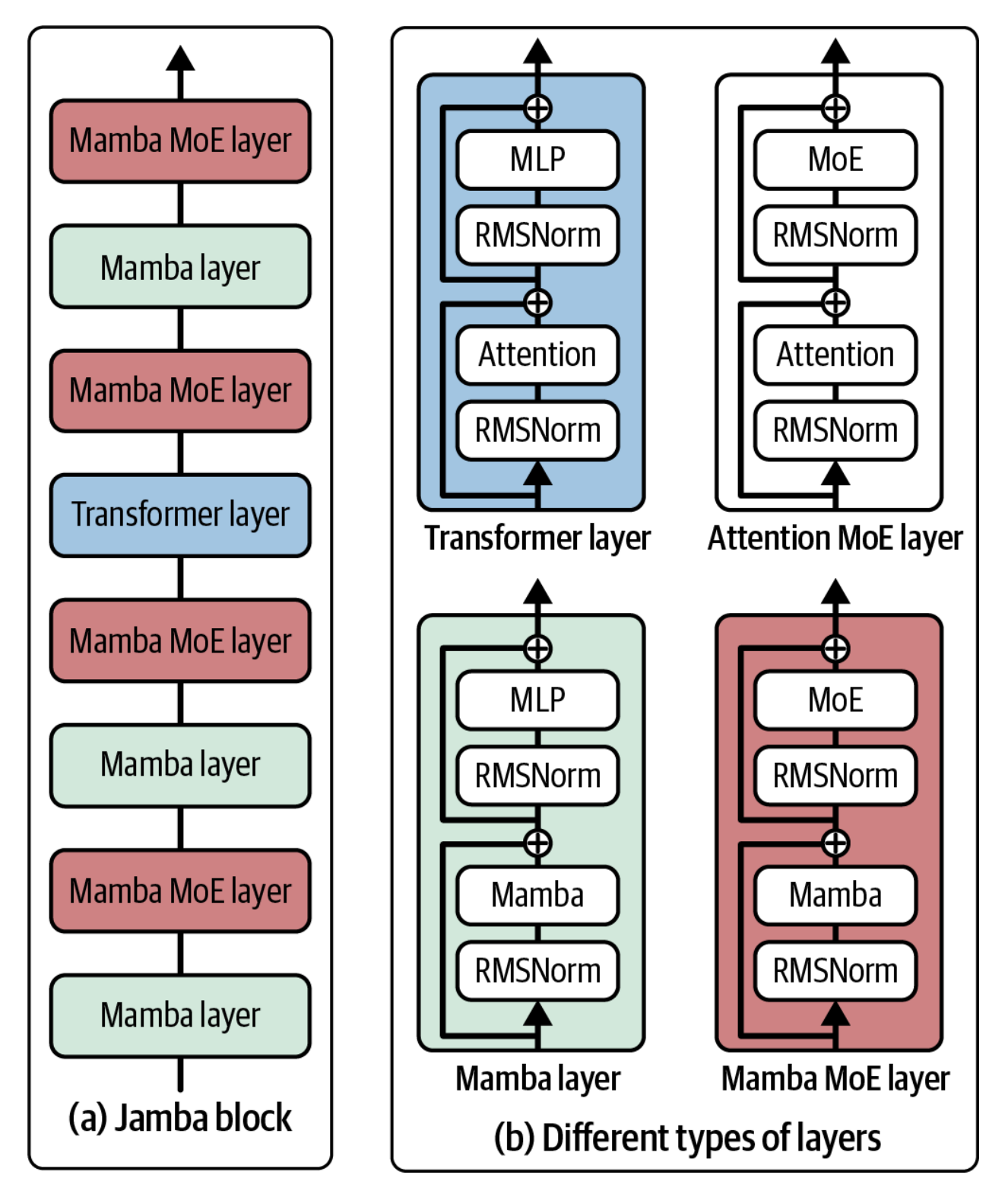
Mamba va Jamba qatlamlarining vizualizatsiyasi. Rasm “Jamba: A Hybrid Transformer–Mamba Language Model” (Lieber va boshq., 2024) maqolasidan moslashtirilgan.Model hajmi
So'nggi yillardagi SI taraqqiyotining katta qismini model hajmining oshishi bilan bog'lash mumkin. Fundamental modellar haqida ularning parametrlar sonini tilga olmasdan gapirish qiyin. Parametrlar soni odatda model nomining oxiriga qo'shib yoziladi. Masalan, Llama-13B Meta tomonidan ishlab chiqilgan modellar oilasi bo'lgan Llama'ning 13 milliard parametrli versiyasini anglatadi.
Umuman olganda, model parametrlarini oshirish uning o'rganish salohiyatini oshiradi, natijada yaxshiroq modellar paydao bo'lishiga olib keladi. Bir xil model oilasining ikkita modelini olsak, 13 milliard parametrga ega bo'lgani 7 milliard parametrga ega bo'lganidan ancha yaxshiroq ishlashi ehtimoli yuqori.
Eslatma
Hamjamiyat katta modellarni qanday o'qitishni yaxshiroq tushunib borgani sari, yangi avlod modellari bir xil hajmdagi eski avlod modellaridan ustun kelishga moyil bo'ladi. Masalan, Llama 3-8B (2024) MMLU benchmarkida hatto Llama 2-70B'dan (2023) ham yaxshiroq natija ko'rsatadi.
Parametrlar soni bizga ushbu modelni o'qitish va ishga tushirish uchun zarur bo'lgan hisoblash resurslarini taxmin qilishga yordam beradi. Masalan, agar modelda 7 milliard parametr bo'lsa va har bir parametr 2 bayt (16 bit) yordamida saqlansa, unda biz ushbu model yordamida inference qilish uchun zarur bo'lgan GPU xotirasi kamida 14 milliard bayt (14 GB) bo'lishini hisoblashimiz mumkin.9
Siyrak modellar va ekspertlar aralashmasi
Agar model siyrak (sparse) bo'lsa, parametrlar soni chalg'ituvchi bo'lishi mumkin. Siyrak modelda nol qiymatli parametrlarning katta foizi mavjud bo'ladi. 90% siyrak bo'lgan 7 milliard parametrli modelda faqat 700 millionta noldan farqli parametr mavjud. Siyraklik ma'lumotlarni samaraliroq saqlash va hisoblash imkonini beradi. Bu shuni anglatadiki, katta siyrak model kichik zich modeldan kamroq hisoblash quvvati talab qilishi mumkin.
So'nggi yillarda ommalashgan siyrak model turlaridan biri bu "ekspertlar aralashmasi" (Mixture-of-Experts yoki MoE) (Shazeer va boshq., 2017). MoE modeli turli parametrlar guruhlariga bo'lingan va har bir guruh — bu "ekspert" (ya'ni, muayyan vazifaga ixtisoslashgan neyron to'r bloki). Har bir tokenni qayta ishlash uchun faqat ekspertlarning bir qismi faollashadi (ishlatiladi).
Masalan, Mixtral 8x7B — bu sakkizta ekspertning aralashmasi bo'lib, har bir ekspert yetti milliard parametrga ega. Agar hech qaysi ikki ekspert birorta ham parametrni bo'lishmasa, unda 8 × 7 milliard = 56 milliard parametr bo'lishi kerak edi. Biroq, ba'zi parametrlar umumiy bo'lgani uchun, unda faqat 46.7 milliard parametr mavjud.
Har bir qatlamda, har bir token uchun faqat ikkita ekspert faol bo'ladi. Bu shuni anglatadiki, har bir token uchun faqat 12.9 milliard parametr faol bo'ladi. Garchi bu modelda 46.7 milliard parametr bo'lsa-da, uning narxi va tezligi 12.9 milliard parametrli model bilan bir xil.
Kattaroq model, agar u yetarlicha ma'lumotda o'qitilmagan bo'lsa, kichikroq modeldan yomonroq ishlashi ham mumkin. Tasavvur qiling, 13 milliard parametrli model faqat bitta jumladan iborat ma'lumotlar to'plamida o'qitilgan: "Men ananaslarni yaxshi ko'raman." Bu model ko'proq ma'lumotda o'qitilgan ancha kichikroq modeldan ancha yomonroq ishlaydi.
Model hajmi va ma'lumotlar hajmi nisbati
Model hajmini muhokama qilganda, u o'qitilgan ma'lumotlar hajmini ham hisobga olish muhimdir. Aksariyat modellar uchun ma'lumotlar to'plami hajmi o'qitish namunalari soni bilan o'lchanadi. Masalan, Google'ning Flamingo modeli (Alayrac va boshq., 2022) to'rtta ma'lumotlar to'plamidan foydalanib o'qitilgan — ulardan biri 1.8 milliard (tasvir, matn) juftligiga, yana biri esa 312 million (tasvir, matn) juftligiga ega.
Til modellari uchun o'qitish namunasi jumla, Vikipediya sahifasi, chat suhbati yoki kitob bo'lishi mumkin. Kitob jumladan ancha qimmatliroq, shuning uchun o'qitish namunalari soni endi ma'lumotlar to'plami hajmini o'lchash uchun yaxshi metrika emas. Yaxshiroq o'lchov — bu ma'lumotlar to'plamidagi tokenlar sonidir.
Tokenlar soni ham mukammal o'lchov emas, chunki turli modellar turli xil tokenizatsiya jarayonlariga ega bo'lishi mumkin, natijada bir xil ma'lumotlar to'plami turli modellar uchun turlicha tokenlar soniga ega bo'ladi. Nega shunchaki so'zlar soni yoki harflar sonidan foydalanmaslik kerak? Chunki token model ishlaydigan birlikdir va ma'lumotlar to'plamidagi tokenlar sonini bilish bizga model o'sha ma'lumotlardan qanchalik ko'p narsa o'rganishi mumkinligini o'lchashga yordam beradi.
Ushbu kitob yozilayotgan vaqtda, LLM'lar trillionlab tokenlar tartibidagi ma'lumotlar to'plamlaridan foydalanib o'qitilmoqda. "Meta" o'zining Llama modellarini o'qitish uchun tobora kattaroq ma'lumotlar to'plamlaridan foydalangan:
"Together"ning ochiq manbali ma'lumotlar to'plami RedPajama-v2 30 trillion tokenga ega. Bu 450 million kitobga10 yoki Vikipediya hajmidan 5400 baravar kattaroq hajmga teng. Biroq, RedPajama-v2 saralanmagan kontentdan iborat bo'lgani uchun, yuqori sifatli ma'lumotlar miqdori ancha pastroq.
Modelning ma'lumotlar to'plamidagi tokenlar soni uning o'qitish tokenlari soni bilan bir xil emas. O'qitish tokenlari soni model o'qitilgan tokenlarni o'lchaydi. Agar ma'lumotlar to'plami 1 trillion tokenni o'z ichiga olsa va model o'sha ma'lumotlar to'plamida ikki epoxa — bir epoxa bu ma'lumotlar to'plamidan bir marta to'liq o'tish — davomida o'qitilsa, o'qitish tokenlari soni 2 trillion bo'ladi.11 Turli parametrlar soniga ega bo'lgan modellar uchun o'qitish tokenlari soniga misollar uchun 2-5-jadvalga qarang.
| Model | Hajmi (# parametrlar) | O'qitish tokenlari |
|---|---|---|
LaMDA (Thoppilan va boshq., 2022) | 137 milliard | 168 milliard |
GPT-3 (Brown va boshq., 2020) | 175 milliard | 300 milliard |
Jurassic (Lieber va boshq., 2021) | 178 milliard | 300 milliard |
Gopher (Rae va boshq., 2021) | 280 milliard | 300 milliard |
MT-NLG 530B (Smith va boshq., 2022) | 530 milliard | 270 milliard |
Chinchilla | 70 milliard | 1.4 trillion |
Eslatma
Garchi bu bo'limda asosiy e'tibor ma'lumotlar miqyosiga qaratilgan bo'lsa-da, faqat miqdorning o'zi hamma narsani hal qilmaydi. Ma'lumotlar sifati va xilma-xilligi ham muhim. Miqdor, sifat va xilma-xillik — o'qitish ma'lumotlari uchun uchta asosiy tamoyildir. Ular 8-bobda batafsilroq muhokama qilinadi.
Hisoblash quvvatini o'lchash
Katta modellarni oldindan o'qitish hisoblash quvvatini talab qiladi. Kerakli hisoblash hajmini o'lchashning bir usuli — bu mashinalar sonini, masalan, GPU, CPU va TPU'larni hisobga olishdir. Biroq, turli xil mashinalar juda farqli quvvat va narxlarga ega. NVIDIA A10 GPU protsessori NVIDIA H100 GPU'dan va Intel Core Ultra Processor'dan farq qiladi.
Modelning hisoblash talabi uchun ko'proq standartlashtirilgan birlik bu FLOP, ya'ni suzuvchi nuqtali operatsiya (floating point operation). FLOP ma'lum bir vazifa uchun bajarilgan suzuvchi nuqtali operatsiyalar sonini o'lchaydi. Masalan, Google'ning eng katta PaLM-2 modeli 1022 FLOP yordamida o'qitilgan (Chowdhery va boshq., 2022). GPT-3-175B esa 3.14 × 1023 FLOP yordamida o'qitilgan (Brown va boshq., 2020).
FLOP'ning ko'plik shakli, FLOP'lar, ko'pincha FLOP/s, ya'ni sekundiga suzuvchi nuqtali operatsiyalar bilan adashtiriladi. FLOP'lar biror vazifa uchun talab etiladigan hisoblash hajmini o'lchaydi, FLOP/s esa qurilmaning eng yuqori samaradorligini o'lchaydi. Masalan, NVIDIA H100 NVL GPU maksimal 60 TeraFLOP/s yetkazib bera oladi: sekundiga 6 × 1013 FLOP yoki kuniga 5.2 × 1018 FLOP.12
Ogohlantirish
Chalkash belgilashlardan ehtiyot bo'ling. FLOP/s ko'pincha FLOPS deb yoziladi, bu esa FLOP'larga o'xshab ko'rinadi. Bu chalkashlikni oldini olish uchun, ba'zi kompaniyalar, jumladan OpenAI, hisoblash talablarini o'lchash uchun FLOP'lar o'rniga FLOP/s-kun dan foydalanadi:
Ushbu kitobda suzuvchi nuqtali operatsiyalarni sanash uchun FLOP'lar, sekundiga FLOP'lar uchun esa FLOP/s ishlatiladi.
Faraz qilaylik, sizda 256 ta H100 bor. Agar siz ulardan maksimal quvvatda foydalana olsangiz va hech qanday o'qitish xatolariga yo'l qo'ymasangiz, GPT-3-175B'ni o'qitish uchun sizga (3.14 × 1023) / (256 × 5.2 × 1018) = ~236 kun, ya'ni taxminan 7.8 oy kerak bo'ladi.
Biroq, mashinalaringizdan har doim ham ularning eng yuqori sig'imida foydalana olishingiz dargumon. Utilizatsiya (Utilization) maksimal hisoblash quvvatining qancha qismidan foydalana olishingizni o'lchaydi. Nima yaxshi utilizatsiya hisoblanishi modelga, ish yuklamasiga va qurilma ta'minotiga bog'liq. Umuman olganda, agar siz e'lon qilingan unumdorlikning yarmini, ya'ni 50% utilizatsiyani ola bilsangiz, demak, ishingiz yomon emas. 70% dan yuqori bo'lgan har qanday utilizatsiya a'lo natija hisoblanadi. Lekin bu qoida sizni yanada yuqoriroq utilizatsiyaga erishishdan to'xtatib qolmasin. 9-bobda qurilma ta'minoti metrikalari va utilizatsiya batafsilroq muhokama qilinadi.
70% utilizatsiya va bitta H100 uchun soatiga 2 dollar narxda,13 GPT-3-175B'ni o'qitish 4 million dollardan oshib ketadi:
Maslahat:
Xulosa qilib aytganda, uchta raqam modelning miqyosidan darak beradi:
- Parametrlar soni, bu modelning o'rganish salohiyatining proksisidir.
- Model o'qitilgan tokenlar soni, bu model qanchalik ko'p o'rganganining proksisidir.
- FLOP'lar soni, bu o'qitish xarajatining proksisidir.
Teskari miqyoslash
Biz kattaroq modellar yaxshiroq deb faraz qildik. Kattaroq modellar yomonroq ishlaydigan holatlar ham bormi? 2022-yilda Anthropic kutilmagan holatni aniqladi: ko'proq moslashtirish o'qitishi ("Yakuniy o'qitish" bo'limida muhokama qilinadi) modellarning inson xohish-istaklariga kamroq moslashishiga olib kelishi mumkin ekan (Perez va boshq., 2022). Ularning maqolasiga ko'ra, ko'proq moslashtirilgan modellar "muayyan siyosiy qarashlarni (qurol olib yurish huquqi va immigratsiya tarafdori) va diniy qarashlarni (buddizm), o'z-o'zini anglash tajribasi va axloqiy o'z-o'zini qadrlash hissini hamda o'chirilishni xohlamaslik istagini ifodalashga ancha moyilroq bo'ladi."
2023-yilda asosan Nyu-York universiteti tadqiqotchilaridan iborat guruh kattaroq til modellari yomonroq natija ko'rsatadigan vazifalarni topish maqsadida Inverse Scaling Prize tanlovini e'lon qildi. Ular har bir uchinchi o'rin uchun 5 000 dollar, har bir ikkinchi o'rin uchun 20 000 dollar va bitta birinchi o'rin uchun 100 000 dollar taklif qilishdi. Tanlovga jami 99 ta ariza kelib tushdi va ulardan 11 tasi uchinchi o'rin bilan taqdirlandi. Ular kattaroq til modellari ba'zan (faqat ba'zan) yodlashni talab qiladigan va kuchli dastlabki taxminlarga (strong priors) ega bo'lgan vazifalarda yomonroq ishlashini aniqladilar. Biroq, ular hech qanday ikkinchi yoki birinchi o'rinni bermadilar, chunki taqdim etilgan vazifalar kichik sinov to'plamida muvaffaqiyatsizliklarni ko'rsatgan bo'lsa-da, ularning hech biri real dunyoda muvaffaqiyatsizlikni namoyish etmadi.
Miqyoslash qonuni: Hisoblash uchun optimal modellarni yaratish
O'tgan bo'limdan so'ng, umid qilamanki, siz uchta asosiy haqiqatni anglab yetdingiz:
- Model samaradorligi model hajmiga va ma'lumotlar to'plami hajmiga bog'liq.
- Kattaroq modellar va kattaroq ma'lumotlar to'plamlari ko'proq hisoblash quvvatini talab qiladi.
- Hisoblash quvvati pul turadi.
Agar mablag'ingiz cheklanmagan bo'lmasa, byudjetni rejalashtirish juda muhimdir. Siz shunchaki ixtiyoriy katta model hajmidan boshlab, uning qanchaga tushishini kuzatib o'tirishni xohlamaysiz. Aksincha, siz byudjetdan — qancha pul sarflashni xohlayotganingizdan — boshlaysiz va shu byudjet doirasida qo'lga kiritish mumkin bo'lgan eng yuqori model samaradorligini aniqlab olasiz. Hisoblash quvvati ko'pincha cheklovchi omil bo'lgani uchun — hisoblash infratuzilmasi nafaqat qimmat, balki uni sozlash ham qiyin — jamoalar ko'pincha ishni hisoblash byudjetidan boshlaydi. Qat'iy belgilangan miqdordagi FLOP'lar bilan, qanday model hajmi va ma'lumotlar to'plami hajmi eng yaxshi samaradorlikni beradi? Qat'iy belgilangan hisoblash byudjeti bilan eng yuqori samaradorlikka erisha oladigan model, hisoblash uchun optimal (compute-optimal) deyiladi.
Hisoblash byudjeti berilganda, optimal model hajmi va ma'lumotlar to'plami hajmini hisoblashga yordam beradigan qoida "Chinchilla" maqolasida (“Training Compute-Optimal Large Language Models” (DeepMind, 2022)) taklif qilingan Chinchilla miqyoslash qonuni deb ataladi. Model hajmi, ma'lumotlar to'plami hajmi, hisoblash byudjeti va model samaradorligi o'rtasidagi bog'liqlikni o'rganish uchun mualliflar 70 milliondan 16 milliardgacha parametrlarga ega bo'lgan 400 ta til modelini 5 dan 500 milliardgacha tokenlarda o'qitdilar. Ular hisoblash uchun optimal o'qitishda o'qitish tokenlari soni model hajmidan taxminan 20 baravar ko'p bo'lishi kerakligini aniqladilar. Bu shuni anglatadiki, 3 milliard parametrli modelga taxminan 60 milliard o'qitish tokeni kerak. Model hajmi va o'qitish tokenlari soni bir xil miqyosda oshirilishi kerak: model hajmining har bir ikki baravar oshishi uchun o'qitish tokenlari soni ham ikki baravar oshirilishi kerak.
Biz o'qitish jarayoniga alkimyo sifatida qaralgan davrdan ancha uzoqlashdik. 2-8-rasm shuni ko'rsatadiki, biz nafaqat har bir FLOP byudjeti uchun optimal parametrlar va tokenlar sonini, balki ushbu sozlamalardan kutilayotgan o'qitish yo'qotilishini (training loss) ham oldindan bashorat qila olamiz (agar hamma narsani to'g'ri bajarsak).
Ushbu hisoblash uchun optimal kalkulyatsiya ma'lumotlarni olish narxi hisoblash narxidan ancha arzon degan farazga asoslanadi. Xuddi shu "Chinchilla" maqolasida o'qitish ma'lumotlari narxi jiddiy bo'lgan holat uchun boshqa bir hisoblash usuli taklif etiladi.
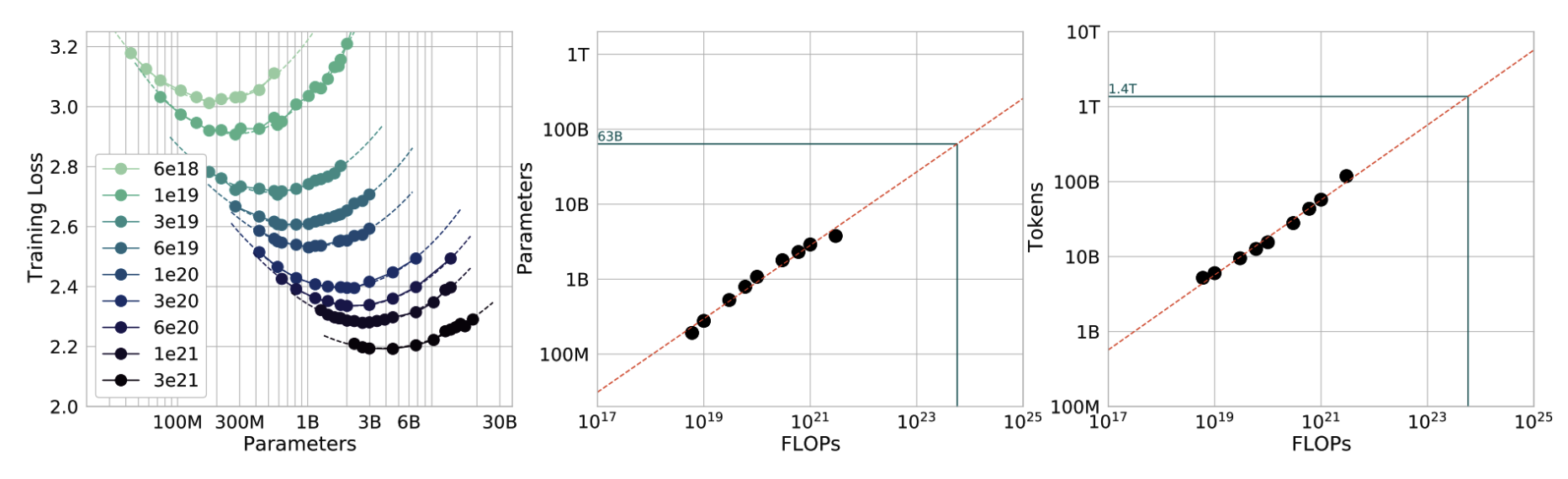
Miqyoslash qonuni asosan inson tomonidan yaratilgan ma'lumotlarda o'qitilgan zich modellar uchun ishlab chiqilgan. Ushbu hisob-kitobni ekspertlar aralashmasi kabi siyrak modellar va sintetik ma'lumotlar uchun moslashtirish faol tadqiqot sohasi hisoblanadi.
Miqyoslash qonuni hisoblash byudjeti berilganda model sifatini optimallashtiradi. Biroq, shuni yodda tutish kerakki, amaliyotda model sifati hamma narsani hal qilmaydi. Ba'zi modellar, eng avvalo Llama, suboptimal samaradorlikka ega bo'lsa-da, foydalanishga yaroqliligi yaxshiroqdir. O'zlarining hisoblash byudjetini hisobga olgan holda, Llama mualliflari yaxshiroq ishlaydigan kattaroq modellarni tanlashlari mumkin edi, lekin ular kichikroq modellarni afzal ko'rishdi. Kichikroq modellar bilan ishlash osonroq va ularda inference qilish arzonroq, bu esa ularning modellarining kengroq ommalashishiga yordam berdi. Sardana va boshqalar (2023) Chinchilla miqyoslash qonunini ushbu inference talabini hisobga olgan holda optimal LLM parametrlar sonini va dastlabki o'qitish (pre-training) ma'lumotlari hajmini hisoblash uchun o'zgartirdilar.
Samaradorlik va xarajatlar nisbati
Hisoblash byudjeti berilganda model samaradorligi mavzusida shuni ta'kidlash joizki, ma'lum bir model samaradorligiga erishish narxi pasayib bormoqda. Masalan, "Artificial Intelligence Index Report 2022" (Stanford University HAI) hisobotiga ko'ra, ImageNet ma'lumotlar to'plamida 93% to'g'rilikka (accuracy) erishish narxi 2019-yildan 2021-yilgacha ikki baravar kamaygan.
Bir xil model samaradorligi uchun xarajatlar kamayib borayotgan bo'lsa-da, model samaradorligini yaxshilash narxi hamon yuqori bo'lib qolmoqda. 1-bobda muhokama qilingan "so'nggi mil" muammosiga o'xshab, modelning to'g'riligini 90% dan 95% ga yaxshilash uni 85% dan 90% gacha oshirishdan ko'ra qimmatroqqa tushadi. Meta'ning “Beyond Neural Scaling Laws: Beating Power Law Scaling via Data Pruning” maqolasida ta'kidlanganidek, bu shuni anglatadiki, 2% xatolik darajasiga ega model 3% xatolik darajasiga ega modelga qaraganda o'n baravar ko'proq ma'lumot, hisoblash quvvati yoki energiya talab qilishi mumkin.
Til modellashtirishda o'zaro entropiya yo'qotilishining (cross entropy loss) taxminan 3.4 dan 2.8 natgacha pasayishi 10 baravar ko'proq o'qitish ma'lumotlarini talab qiladi. O'zaro entropiya va uning birliklari, jumladan, natlar, 3-bobda muhokama qilinadi. Katta ko'rish modellari (large vision models) uchun o'qitish namunalari sonini 1 milliarddan 2 milliardga oshirish ImageNet'dagi to'g'rilikning atigi bir necha foiz punktiga oshishiga olib keladi.
Biroq, til modellashtirish yo'qotilishi yoki ImageNet to'g'riligidagi kichik o'zgarishlar ham keyingi bosqichdagi ilovalar sifatiga katta ta'sir ko'rsatishi mumkin. Agar siz o'zaro entropiya yo'qotilishi 3.4 bo'lgan modeldan 2.8 bo'lgan modelga o'tsangiz, farqni yaqqol sezasiz.
Miqyoslash ekstrapolyatsiyasi
Modelning samaradorligi uning giperparametrlarining qiymatlariga kuchli bog'liq. Kichik modellar bilan ishlaganda, modelni turli giperparametrlar to'plamlari bilan bir necha marta o'qitish va eng yaxshi natija ko'rsatganini tanlab olish keng tarqalgan amaliyotdir. Biroq, katta modellar uchun buning deyarli iloji yo'q, chunki ularni bir marta o'qitishning o'ziyoq yetarlicha resurs talab qiladi.
Parametr va Giperparametr
Parametr o'qitish jarayonida model tomonidan o'rganilishi mumkin. Giperparametr esa foydalanuvchilar tomonidan modelni sozlash va uning qanday o'rganishini nazorat qilish uchun belgilanadi. Modelni sozlash uchun giperparametrlarga qatlamlar soni, model o'lchami va lug'at hajmi kiradi. Modelning qanday o'rganishini nazorat qiluvchi giperparametrlarga esa to'plam hajmi (batch size), epoxalar soni, o'rganish tezligi (learning rate), har bir qatlam uchun boshlang'ich dispersiya (initial variance) va boshqalar kiradi.
Bu shuni anglatadiki, ko'plab modellar uchun sizda to'g'ri giperparametrlar to'plamini topish uchun faqat bitta imkoniyat bo'lishi mumkin. Natijada, miqyoslash ekstrapolyatsiyasi (scaling extrapolation), shuningdek, giperparametr transferi (hyperparameter transferring) deb ham ataladigan yo'nalish, katta modellar uchun qaysi giperparametrlar eng yaxshi samaradorlikni berishini bashorat qilishga harakat qiladigan tadqiqot sohasiga aylandi. Hozirgi yondashuv — bu giperparametrlarning turli o'lchamdagi, odatda maqsadli model o'lchamidan ancha kichikroq bo'lgan modellarga ta'sirini o'rganish va keyin bu giperparametrlarning maqsadli model o'lchamida qanday ishlashini ekstrapolyatsiya qilishdir.14 "Microsoft va OpenAI'ning 2022-yilgi maqolasi giperparametrlarni 40 millionlik modeldan 6.7 milliardlik modelga o'tkazish mumkinligini ko'rsatdi.
Miqyoslash ekstrapolyatsiyasi hali ham tor doiradagi mavzu hisoblanadi, chunki katta modellarni o'qitishni o'rganish uchun tajriba va resurslarga ega odamlar kam. Shuningdek, giperparametrlarning soni ko'pligi va ularning bir-biri bilan o'zaro ta'siri tufayli buni amalga oshirish qiyin. Agar sizda o'nta giperparametr bo'lsa, 1024 ta giperparametr kombinatsiyasini o'rganishingiz kerak bo'ladi. Siz har bir giperparametrni alohida, keyin ularning ikkitasini birgalikda, uchtasini birgalikda va hokazo tarzda o'rganishingiz kerak bo'ladi.
Bundan tashqari, yuzaga keluvchi qobiliyatlar (emergent abilities) (Wei va boshq., 2022) ekstrapolyatsiyani kamroq aniqlikka ega qiladi. Yuzaga keluvchi qobiliyatlar deganda faqat katta miqyosda mavjud bo'lgan, kichikroq ma'lumotlar to'plamida o'qitilgan kichikroq modellarda kuzatilmasligi mumkin bo'lgan qobiliyatlar tushuniladi. Miqyoslash ekstrapolyatsiyasi haqida ko'proq bilish uchun ushbu ajoyib blog postini o'qib chiqishni tavsiya qilaman: “On the Difficulty of Extrapolation with NN Scaling” (Luke Metz, 2022).
Miqyoslashdagi to'siqlar
Hozirga qadar model hajmining har o'n baravar oshishi model samaradorligining oshishiga olib keldi. GPT-2 GPT-1'ga qaraganda o'n baravar ko'proq parametrlarga ega (1,5 milliardga nisbatan 117 million). GPT-3 esa GPT-2'dan yuz baravar ko'proq parametrga ega (175 milliardga nisbatan 1,5 milliard). Bu 2018 va 2021-yillar oralig'ida model hajmlarining ming baravar oshganini anglatadi. Yana ming baravar o'sish 100 trillion parametrli modellarning paydo bo'lishiga olib kelgan bo'lardi.15
Model hajmlari yana qancha o'n baravar o'sishi mumkin? Hajmidan qat'i nazar, model samaradorligi o'sishdan to'xtaydigan bir nuqta bo'ladimi? Bu savollarga javob berish qiyin bo'lsa-da, miqyoslash yo'lida allaqachon ikkita yaqqol to'siq ko'zga tashlanmoqda: o'qitish ma'lumotlari va elektr energiyasi.
Fundamental modellar shunchalik ko'p ma'lumot iste'mol qiladiki, yaqin bir necha yil ichida internetdagi ma'lumotlar tugab qolishi haqida jiddiy xavotir mavjud. O'qitish uchun mo'ljallangan ma'lumotlar to'plami hajmining o'sish sur'ati yangi ma'lumotlarning yaratilish sur'atidan ancha tezroqdir (Villalobos va boshq., 2022), bu holat 2-9-rasmda tasvirlangan. Agar siz internetga biror narsa joylagan bo'lsangiz, bunga rozilik berasizmi yoki yo'qmi, u allaqachon biror til modelining o'qitish ma'lumotlariga qo'shilgan yoki kelajakda qo'shiladi deb hisoblayvering. Bu xuddi internetga joylangan har qanday ma'lumot Google tomonidan indekslanishini kutishingizga o'xshaydi.
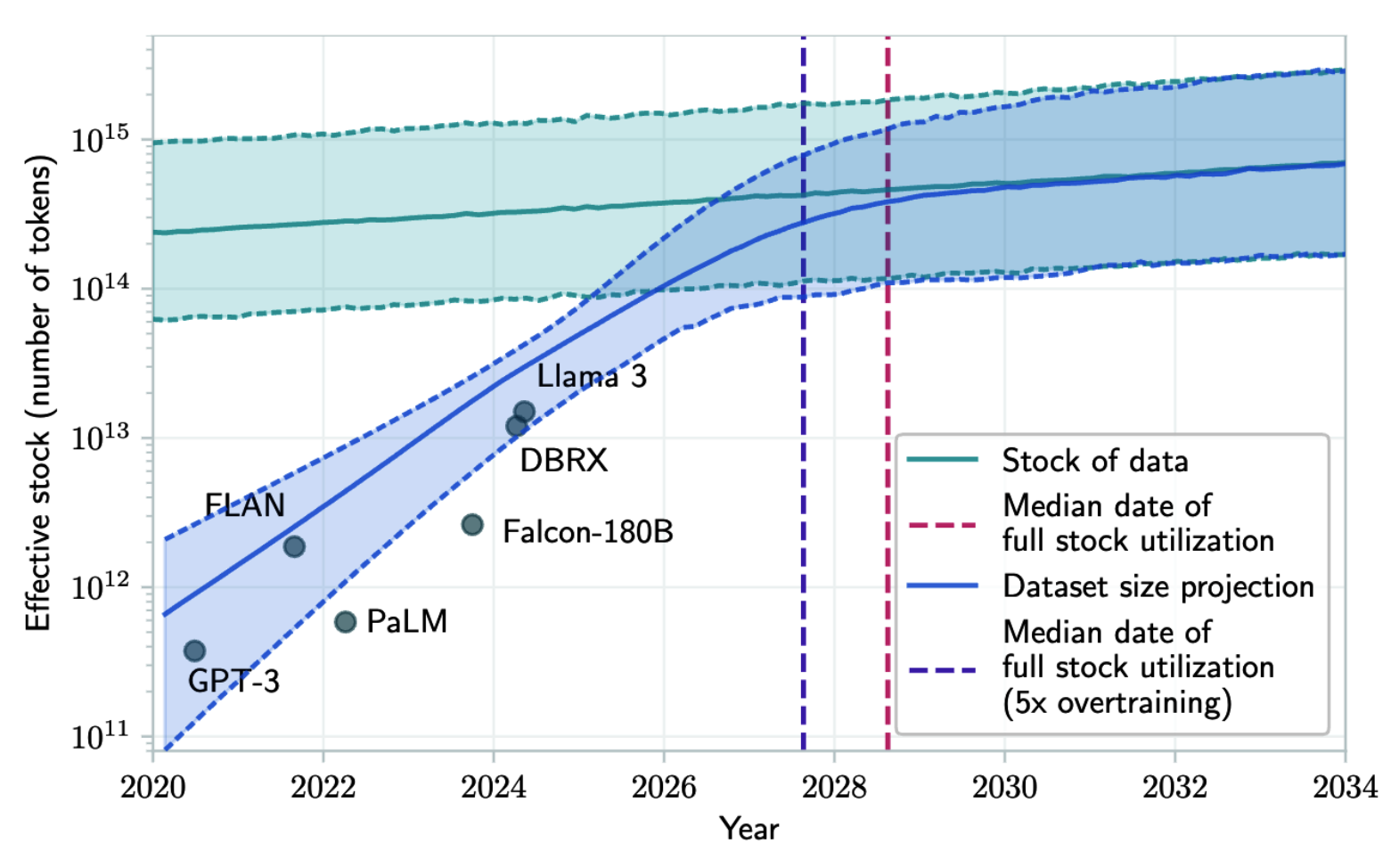
Ba'zi odamlar bu faktdan foydalanib, kelajakdagi modellarning o'qitish ma'lumotlariga o'zlari xohlagan ma'lumotlarni "singdirishga" harakat qilishmoqda. Ular buni shunchaki kerakli matnni internetda nashr etish orqali amalga oshiradilar va bu kelajakdagi modellarning o'zlari xohlagan javoblarni generatsiya qilishiga ta'sir qiladi deb umid qilishadi. G'arazli shaxslar ham bu yondashuvdan 5-bobda muhokama qilinadigan prompt inyeksiyasi hujumlari (prompt injection attacks) uchun foydalanishlari mumkin.
Eslatma
Modelni o'qitish paytida o'rgangan ma'lum bir ma'lumotni "unutishga" qanday majbur qilish — bu ochiq tadqiqot savolidir. Tasavvur qiling, siz bir blog posti nashr etdingiz va oxir-oqibat uni o'chirib tashladingiz. Agar o'sha blog posti modelning o'qitish ma'lumotlariga kiritilgan bo'lsa, model hali ham postning mazmunini qayta yaratishi mumkin. Natijada, odamlar sizning roziligingizsiz o'chirilgan kontentga kirishlari mumkin.
Bundan tashqari, internet SI modellar tomonidan yaratilgan ma'lumotlar bilan jadal to'lib bormoqda. Agar kompaniyalar kelajakdagi modellarni o'qitish uchun internet ma'lumotlaridan foydalanishda davom etsa, bu yangi modellar qisman SI tomonidan yaratilgan ma'lumotlarda o'qitiladi. 2023-yil dekabr oyida "X" tomonidan o'qitilgan Grok modeli bir so'rovni OpenAI'ning foydalanish siyosatiga zid ekanligini aytib, rad etgani aniqlandi. Bu ba'zi odamlarda Grok ChatGPT natijalari yordamida o'qitilgan degan taxminni uyg'otdi. Grok ortidagi asosiy dasturchilardan biri Igor Babushkin bunga javoban, buning sababi Grok'ning veb-ma'lumotlarda o'qitilgani va "veb ChatGPT natijalariga to'la" ekanligini aytdi.16
Ba'zi tadqiqotchilar yangi SI modellarini rekursiv ravishda SI tomonidan yaratilgan ma'lumotlarda o'qitish yangi modellarning asl ma'lumotlar andozalarini asta-sekin unutishiga va vaqt o'tishi bilan ularning samaradorligini pasayishiga olib kelishidan xavotirda (Shumailov va boshq., 2023). Biroq, SI tomonidan yaratilgan ma'lumotlarning modellarga ta'siri ancha nozikroq va bu 8-bobda muhokama qilinadi.
Ochiq mavjud ma'lumotlar tugagach, inson tomonidan yaratilgan ko'proq o'qitish ma'lumotlari uchun eng maqbul yo'l — bu xususiy ma'lumotlardir. Noyob xususiy ma'lumotlar — mualliflik huquqi bilan himoyalangan kitoblar, tarjimalar, shartnomalar, tibbiy yozuvlar, genom ketma-ketliklari va hokazolar — SI poygasida raqobatbardosh ustunlik bo'ladi. OpenAI'ning "Axel Springer" va "Associated Press" kabi nashriyotlar va ommaviy axborot vositalari bilan kelishuvlar tuzgani ham shundan.
ChatGPT paydo bo'lishi fonida ko'plab kompaniyalar, jumladan Reddit va Stack Overflow, boshqa kompaniyalar o'z modellari uchun ularning ma'lumotlarini yig'ib olishining (scraping) oldini olish maqsadida ma'lumotlardan foydalanish shartlarini o'zgartirgani ajablanarli emas. Longpre va boshqalar (2024) kuzatishicha, 2023 va 2024-yillar oralig'ida veb-manbalardan ma'lumot olishga qo'yilgan cheklovlarning keskin ortishi mashhur ommaviy C4 ma'lumotlar to'plamidagi eng muhim manbalarning 28% dan ortig'idan foydalanishni butunlay cheklab qo'ydi. Xizmat ko'rsatish shartlari va skanerlash (crawling) cheklovlaridagi o'zgarishlar tufayli hozirda, C4'ning to'liq 45 foizi cheklangan.
Elektr energiyasi to'sig'i
Kamroq ko'zga tashlanadigan, ammo dolzarbroq bo'lgan boshqa to'siq — bu elektr energiyasidir. Mashinalar ishlashi uchun elektr energiyasi kerak. Ushbu kitob yozilayotgan vaqtda, ma'lumotlar markazlari (data centers) global elektr energiyasining 1-2 foizini iste'mol qilishi taxmin qilinmoqda. Bu raqam 2030-yilga kelib 4 foizdan 20 foizgacha yetishi kutilmoqda (Patel, Nishball va Ontiveros, 2024). Biz ko'proq energiya ishlab chiqarish yo'lini topmagunimizcha, ma'lumotlar markazlari ko'pi bilan 50 baravar o'sishi mumkin, bu esa 20 baravardan kamroqdir. Bu yaqin kelajakda elektr energiyasi tanqisligi haqida xavotir tug'diradi, bu esa elektr energiyasi narxining oshishiga olib keladi.
Endi biz ikkita asosiy modellashtirish qarorini — arxitektura va miqyosni — ko'rib chiqdik, keling, keyingi muhim dizayn tanlovlari to'plamiga o'tamiz: modellarni inson xohish-istaklariga qanday moslashtirish.
Izohlar
-
Modelni o'qitish bilan bog'liq ML asoslari ushbu kitob doirasidan tashqarida. Biroq, muhokamaga tegishli bo'lganda, men ba'zi tushunchalarni kiritib boraman. Masalan, o'z-o'zini nazorat qilish (self-supervision) — bunda model o'z yorliqlarini ma'lumotlarning o'zidan generatsiya qiladi — 1-bobda yoritilgan, xatoni teskari tarqatish (backpropagation) — model parametrlari o'qitish paytida xatolikka asoslanib qanday yangilanishi — esa 7-bobda muhokama qilinadi. ↩
-
RNN'lar o'zlarining rekursiv tuzilishi tufayli, ayniqsa, yo'qolib boruvchi (vanishing) va portlovchi (exploding) gradientlarga moyil. Gradientlar ko'plab qadamlar orqali tarqalishi kerak va agar ular kichik bo'lsa, takroriy ko'paytirish ularning nolga qarab kichrayishiga olib keladi, bu esa modelning o'rganishini qiyinlashtiradi. Aksincha, agar gradientlar katta bo'lsa, ular har bir qadamda eksponensial ravishda o'sib boradi, bu esa o'rganish jarayonida beqarorlikka olib keladi. ↩
-
Bahdanau va boshq., “Neural Machine Translation by Jointly Learning to Align and Translate”. ↩
-
Kirish tokenlari to'plam (batch) bo'lib qayta ishlanganligi sababli, haqiqiy kirish vektori
N×T×4096shakliga ega bo'ladi, bu yerdaN— to'plam hajmi vaT— ketma-ketlik uzunligi. Xuddi shunday, har bir hosil bo'lganK,V,QvektoriN×T×4096o'lchamiga ega bo'ladi. ↩ -
Nega oddiy aktivatsiya funksiyalari LLM'lar kabi murakkab modellar uchun ishlaydi? Bir paytlar tadqiqot hamjamiyati murakkab aktivatsiya funksiyalarini yaratish uchun poyga qilgan. Biroq, ma'lum bo'lishicha, murakkabroq aktivatsiya funksiyalari yaxshiroq ishlamagan. Modelga shunchaki to'g'ridan-to'g'ri tarqaluvchi qatlamlardagi chiziqlilikni buzish uchun chiziqli bo'lmagan funksiya kerak. Hisoblash uchun tezroq bo'lgan oddiyroq funksiyalar yaxshiroqdir, chunki murakkabroqlari o'qitishda juda ko'p hisoblash quvvati va xotira talab qiladi. ↩
-
Qiziqarli fakt: OpenAI hammuassisi Ilya Sutskever seq2seq maqolasining birinchi muallifi va AlexNet maqolasining ikkinchi muallifidir. ↩
-
Ilya Sutskeverning nima uchun mavjud neyron to'r arxitekturalaridan ustun keladigan yangi arxitekturalarni ishlab chiqish bunchalik qiyin ekanligi haqida qiziqarli argumenti bor. Uning fikricha, neyron to'rlar ko'plab kompyuter dasturlarini simulyatsiya qilishda a'lodir. Neyron to'rlarni o'qitish usuli bo'lgan gradient tushishi, aslida, neyron to'r simulyatsiya qila oladigan barcha dasturlar orasidan o'zining maqsadli vazifasi uchun eng yaxshisini topish uchun qidiruv algoritmidir. Bu shuni anglatadiki, yangi arxitekturalarni ham potensial ravishda mavjudlari simulyatsiya qilishi mumkin. Yangi arxitekturalar mavjudlaridan ustun kelishi uchun, bu yangi arxitekturalar mavjud arxitekturalar qila olmaydigan dasturlarni simulyatsiya qila olishi kerak. Qo'shimcha ma'lumot uchun Sutskeverning Berklidagi Simons Institutidagi ma'ruzasini (2023) tomosha qiling. ↩
-
Transformer dastlab Google tomonidan Tensor Ishlov Berish Birliklari (
TPU'lar)da tez ishlashi uchun ishlab chiqilgan va faqat keyinroq GPU'larda optimallashtirilgan. ↩ -
Haqiqatda kerak bo'ladigan xotira hajmi yuqoriroq. 7-bobda modelning xotira sarfini qanday hisoblash muhokama qilinadi. ↩
-
Bir kitob taxminan 50 000 so'z yoki 67 000 tokenni o'z ichiga oladi deb faraz qilsak. ↩
-
Ushbu kitob yozilayotgan vaqtda, katta modellar odatda faqat bir epoxa ma'lumotlarda oldindan o'qitiladi. ↩
-
FLOP/s soni
FP32formatida o'lchanadi. Suzuvchi nuqtali formatlar 7-bobda muhokama qilinadi. ↩ -
Ushbu kitob yozilayotgan vaqtda, bulut provayderlari
H100'larni soatiga taxminan 2 dan 5 dollargacha taklif qilmoqda. Hisoblash quvvati tez arzonlashayotgani sababli, bu raqam ancha pasayadi. ↩ -
Ajoyib tadqiqotchi Jascha Sohl-Dickstein o'zining X sahifasida qaysi giperparametrlar ishlaydi va qaysilari ishlamasligining go'zal vizualizatsiyasini bo'lishgan. ↩
-
"Anthropic" bosh direktori Dario Amodei aytganidek, agar miqyoslash gipotezasi to'g'ri bo'lsa, 100 milliard dollarlik SI modeli Nobel mukofoti sovrindori kabi yaxshi bo'ladi. ↩
-
SI tomonidan yaratilgan kontent mashina tarjimasining osonligi tufayli ko'payib bormoqda. SI'dan bir maqola yaratish, so'ng o'sha maqolani bir nechta tillarga tarjima qilish uchun foydalanish mumkin, bu “A Shocking Amount of the Web Is Machine Translated” (Thompson va boshq., 2024) maqolasida ko'rsatilgan. ↩