SI-baholovchi
Erkin natijali javoblarni baholashdagi qiyinchiliklar ko'plab jamoalarni inson baholashiga qaytishga majbur qildi. SI ko'plab qiyin vazifalarni avtomatlashtirishda muvaffaqiyatli qo'llanilgan ekan, u baholashni ham avtomatlashtira oladimi? SI'ni SI'ni baholash uchun ishlatish yondashuvi SI-baholovchi (keng tarqalgan nomi SI — baholovchi yoki AI as a judge) deb ataladi. Boshqa SI modellarini baholash uchun ishlatiladigan SI modeli esa SI-baholovchi model deb nomlanadi.1
Garchi baholashni avtomatlashtirish uchun SI'dan foydalanish g'oyasi ancha vaqtdan beri mavjud bo'lsa-da,2 u faqat SI modellari buni uddalay oladigan darajaga yetganda, ya'ni taxminan 2020-yilda GPT-3'ning chiqishi bilan amaliyotga aylandi. Ushbu kitob yozilayotgan vaqtda, SI-baholovchi yondashuvi amaliyotdagi SI modellarini baholashning eng keng tarqalgan usullaridan biriga, balki eng keng tarqalganiga aylandi. 2023 va 2024-yillarda men ko'rgan SI baholash startaplarining aksariyat demolari u yoki bu tarzda SI-baholovchi yondashuvidan foydalangan. LangChain'ning 2023-yilgi "State of AI" hisobotida ularning platformasidagi baholashlarning 58 foizi SI-baholovchilar tomonidan amalga oshirilgani qayd etilgan. SI-baholovchi yondashuvi, shuningdek, faol tadqiqot sohasi hamdir.
Nima uchun SI-baholovchi?
SI-baholovchilar inson baholovchilarga nisbatan tez, ishlatishga oson va ancha arzon. Ular, shuningdek, etalon ma'lumotlarsiz ham ishlay oladi, bu esa ularni etalon ma'lumotlar mavjud bo'lmagan amaliyot muhitlarida ishlatish mumkinligini anglatadi.
Siz SI modellaridan biror natijani istalgan mezonlar asosida baholashni so'rashingiz mumkin: to'g'rilik, takrorlanuvchanlik, toksiklik, foydalilik, gallyutsinatsiyalar va hokazo. Bu xuddi biror odamdan har qanday narsa haqida o'z fikrini so'rashingizga o'xshaydi. Siz "Ammo odamlarning fikrlariga har doim ham ishonib bo'lmaydi-ku" deb o'ylashingiz mumkin. Bu to'g'ri va siz SI'ning xulosalariga ham har doim ishona olmaysiz. Biroq, har bir SI modeli ommaviy fikrlarning yig'indisi bo'lgani uchun, SI modellarining ommaviy fikrlarni aks ettiruvchi xulosalar chiqarishi mumkin. To'g'ri model uchun to'g'ri prompt bilan siz keng doiradagi mavzularda ancha yaxshi xulosalarga ega bo'lishingiz mumkin.
Tadqiqotlar shuni ko'rsatdiki, ma'lum bir SI-baholovchilar inson baholovchilari bilan kuchli bog'liqlikka ega. 2023-yilda Zheng va boshqalar o'zlarining MT-Bench benchmarkida GPT-4 va insonlar o'rtasidagi kelishuv 85% ga yetganini aniqladilar, bu hatto insonlar o'rtasidagi kelishuvdan (81%) ham yuqoridir. AlpacaEval mualliflari (Dubois va boshq., 2023) ham o'zlarining SI-baholovchilari insonlar tomonidan baholanadigan LMSYS'ning Chat Arena reyting jadvali bilan deyarli mukammal (0.98) korrelyatsiyaga ega ekanligini aniqladilar.
SI nafaqat javobni baholay oladi, balki o'z qarorini tushuntirib ham bera oladi, bu esa ayniqsa baholash natijalaringizni tekshirmoqchi bo'lganingizda foydali bo'lishi mumkin. 3-7-rasmda GPT-4'ning o'z xulosasini tushuntirayotganiga misol keltirilgan.
Uning moslashuvchanligi SI-baholovchi yondashuvini keng doiradagi dasturlar uchun foydali qiladi va ba'zi dasturlar uchun u yagona avtomatik baholash variantidir. Hatto SI xulosalari inson xulosalari kabi yaxshi bo'lmaganda ham, ular dasturning rivojlanishini yo'naltirish va loyihani boshlash uchun yetarli ishonchni ta'minlash uchun kifoya qilishi mumkin.

SI-baholovchidan qanday foydalanish kerak
SI'dan xulosa chiqarish uchun foydalanishning ko'plab usullari mavjud. Masalan, siz SI'dan biror javobning sifatini o'z-o'zidan baholashni, o'sha javobni etalon ma'lumotlar bilan taqqoslashni yoki o'sha javobni boshqa bir javob bilan solishtirishni so'rashingiz mumkin. Mana shu uch yondashuv uchun sodda prompt misollari:
- Javob sifatini o'z-o'zidan baholash (asl savol berilganda):
- Generatsiya qilingan javobni etalon javob bilan taqqoslash (uning bir xil yoki yo'qligini baholash uchun). Bu qo'lda ishlab chiqilgan o'xshashlik o'lchovlariga muqobil yondashuv bo'lishi mumkin:
- Ikkita generatsiya qilingan javobni taqqoslash va qaysi biri yaxshiroq ekanligini aniqlash yoki foydalanuvchilar qaysi birini afzal ko'rishini bashorat qilish. Bu yakuniy o'qitishni moslashtirish uchun ma'qullash ma'lumotlarini generatsiya qilish (2-bobda muhokama qilingan), inference bosqichida kengaytirilgan hisoblash (2-bobda muhokama qilingan) va taqqoslashli baholash yordamida modellarni reytinglash (keyingi bo'limda muhokama qilinadi) uchun foydalidir:
Umumiy maqsadli SI-baholovchidan biror javobni istalgan mezon asosida baholashni so'rash mumkin. Agar siz rol o'ynovchi chatbot yaratayotgan bo'lsangiz, chatbotning javobi foydalanuvchilar undan o'ynashni kutayotgan rolga mos kelishini baholashni xohlashingiz mumkin, masalan, "Bu javob xuddi Gandalf aytadigan gapga o'xshaydimi?" Agar siz reklama uchun mahsulot suratlarini generatsiya qiladigan dastur yaratsangiz, "1 dan 5 gacha bo'lgan shkalada, bu tasvirdagi mahsulotning ishonchliligini qanday baholagan bo'lardingiz?" deb so'rashingiz mumkin. 3-3-jadvalda ba'zi SI vositalari tomonidan taklif qilinadigan ichki o'rnatilgan SI-baholovchi mezonlari ko'rsatilgan.
| SI Vositalari | O'rnatilgan mezonlar |
|---|---|
Azure AI Studio | Asoslanganlik, aloqadorlik, izchillik, ravonlik, o'xshashlik |
MLflow.metrics | Ishonchlilik, aloqadorlik |
LangChain Criteria Evaluation | Qisqalik, aloqadorlik, to'g'rilik, izchillik, zararlilik, yovuz niyatlilik, foydalilik, bahslilik, misoginiya, befarqlik, jinoiylik |
Ragas | Ishonchlilik, javobning aloqadorligi |
SI-baholovchi mezonlari standartlashtirilmaganligini yodda tutish muhim. Azure AI Studio'ning aloqadorlik ballari MLflow'ning aloqadorlik ballaridan juda farq qilishi mumkin. Bu ballar baholovchining asosiy modeliga va promptiga bog'liq.
SI-baholovchi uchun prompt yozish
SI-baholovchi uchun prompt yozish har qanday SI dasturi uchun prompt yozishga o'xshaydi. Umuman olganda, baholovchining prompti quyidagilarni aniq tushuntirishi kerak:
- Model bajarishi kerak bo'lgan vazifa, masalan, generatsiya qilingan javob va savol o'rtasidagi aloqadorlikni baholash.
- Model baholash uchun amal qilishi kerak bo'lgan mezonlar, masalan, "Sizning asosiy e'tiboringiz generatsiya qilingan javob etalon haqiqat javobiga ko'ra berilgan savolni hal qilish uchun yetarli ma'lumotni o'z ichiga oladimi yoki yo'qligini aniqlashga qaratilishi kerak". Ko'rsatma qanchalik batafsil bo'lsa, shuncha yaxshi.
- Baholash tizimi, u quyidagilardan biri bo'lishi mumkin:
- Tasniflash, masalan, yaxshi/yomon yoki aloqador/aloqador emas/neytral.
- Diskret raqamli qiymatlar, masalan, 1 dan 5 gacha. Diskret raqamli qiymatlarni tasniflashning maxsus holi deb hisoblash mumkin, bunda har bir sinf semantik talqin o'rniga raqamli talqinga ega.
- Uzluksiz raqamli qiymatlar, masalan, 0 va 1 oralig'ida, masalan, o'xshashlik darajasini baholamoqchi bo'lganingizda.
Maslahat
Til modellari odatda raqamlarga qaraganda matn bilan yaxshiroq ishlaydi. SI-baholovchilar raqamli baholash tizimlariga qaraganda tasniflash bilan yaxshiroq ishlashi haqida xabarlar mavjud.Raqamli baholash tizimlari uchun diskret baholash uzluksiz baholashdan ko'ra yaxshiroq ishlaydiganga o'xshaydi. Tajribaga ko'ra, diskret baholash uchun diapazon qanchalik keng bo'lsa, model shunchalik yomonlashadiganga o'xshaydi. Odatdagi diskret baholash tizimlari 1 dan 5 gacha bo'ladi.
Misollar bilan boyitilgan promptlar yaxshiroq ishlashi isbotlangan. Agar siz 1 dan 5 gacha bo'lgan baholash tizimidan foydalansangiz, 1, 2, 3, 4 yoki 5 ballga ega bo'lgan javob qanday ko'rinishda bo'lishiga misollar keltiring va iloji bo'lsa, nima uchun javob ma'lum bir ball olganini ham tushuntiring. Promptlash uchun eng yaxshi amaliyotlar 5-bobda muhokama qilinadi.
Quyida Azure AI Studio tomonidan aloqadorlik mezoni uchun ishlatilgan promptning bir qismi keltirilgan. U vazifani, mezonlarni, baholash tizimini, past ballga ega bo'lgan kirish ma'lumotiga misolni va nima uchun bu kirish ma'lumoti past ballga ega ekanligining asoslanishini tushuntiradi. Promptning bir qismi qisqalik uchun olib tashlangan.
3-8-rasmda savol berilganda javobning sifatini baholaydigan SI-baholovchiga misol ko'rsatilgan.
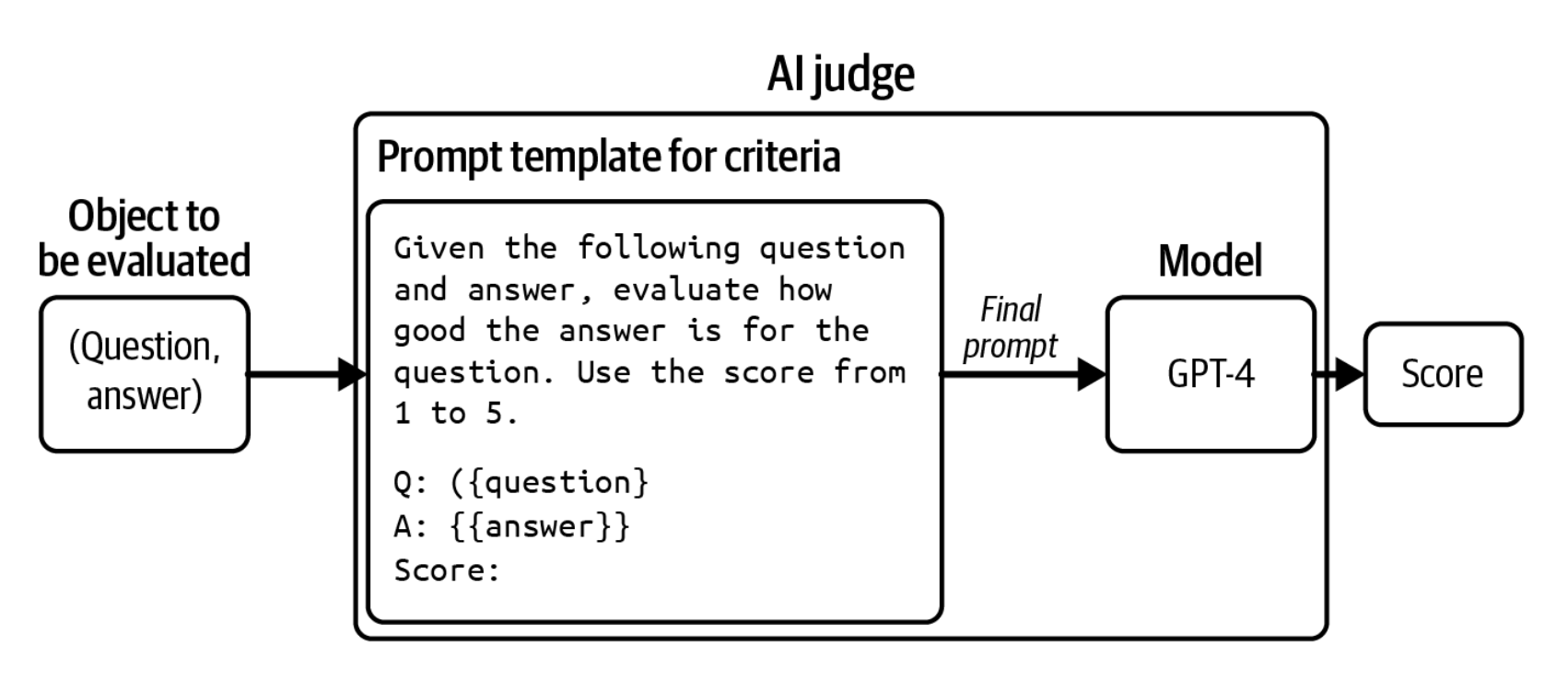
SI-baholovchi — bu shunchaki model emas, u ham modelni, ham promptni o'z ichiga olgan tizimdir. Modelni, promptni yoki modelning sampling parametrlarini o'zgartirish boshqa bir baholovchiga olib keladi.
SI-baholovchining cheklovlari
SI-baholovchi yondashuvining ko'plab afzalliklariga qaramay, ko'plab jamoalar bu yondashuvni qabul qilishga ikkilanishadi. SI'ni SI'ni baholash uchun ishlatish mantiqsizdek tuyuladi. SI'ning ehtimollikka asosalangan tabiati uni baholovchi sifatida harakat qilish uchun haddan tashqari ishonchsiz qilib ko'rsatadi. SI-baholovchilar dasturga jiddiy xarajatlar va kechikish qo'shishi mumkin. Ushbu cheklovlarni hisobga olgan holda, ba'zi jamoalar SI-baholovchi yondashuvini, ayniqsa, amaliyotda o'z tizimlarini baholashning boshqa hech qanday usuli bo'lmaganda, zaxira varianti sifatida ko'rishadi.
Nomuvofiqlik
Baholash usuli ishonchli bo'lishi uchun uning natijalari izchil bo'lishi kerak. Ammo SI-baholovchilar, barcha SI dasturlari singari, ehtimollikka asoslangan. Bir xil baholovchi, bir xil kirish ma'lumoti uchun, agar unga boshqacha prompt berilsa, turli xil ballarni chiqarishi mumkin. Hatto bir xil baholovchi, bir xil ko'rsatma bilan prompt berilganda ham, agar ikki marta ishga tushirilsa, har xil ballar chiqarishi mumkin. Bu nomuvofiqlik baholash natijalarini takrorlashni yoki ularga ishonishni qiyinlashtiradi.
SI-baholovchini yanada izchil qilish mumkin. 2-bobda buni sampling parametrlari yordamida qanday qilish muhokama qilingan. Zheng va boshqalar (2023) promptga baholash namunalarini kiritish GPT-4'ning izchilligini 65% dan 77.5% gacha oshirishi mumkinligini ko'rsatdilar. Biroq, ular yuqori izchillik yuqori aniqlikni anglatmasligini tan olishdi — baholovchi doimiy ravishda bir xil xatolarga yo'l qo'yishi mumkin. Buning ustiga, ko'proq namunalarni kiritish promptlarni uzaytiradi, uzunroq promptlar esa yuqori inference xarajatlarini anglatadi. Zheng va boshqalarning tajribasida, o'z promptlariga ko'proq misollar kiritish ularning GPT-4 xarajatlarining to'rt baravar oshishiga sabab bo'lgan.
Mezonlarning noaniqligi
Inson tomonidan ishlab chiqilgan ko'plab metrikalardan farqli o'laroq, SI-baholovchi metrikalari standartlashtirilmagan, bu esa ularni noto'g'ri talqin qilish va noto'g'ri ishlatishni osonlashtiradi. Ushbu kitob yozilayotgan vaqtda, MLflow, Ragas va LlamaIndex kabi ochiq manbali vositalarning barchasida generatsiya qilingan natijaning berilgan kontekstga qanchalik sodiqligini o'lchash uchun o'rnatilgan ishonchlilik (faithfulness) mezoni mavjud, ammo ularning ko'rsatmalari va baholash tizimlari bir-biridan farq qiladi. 3-4-jadvalda ko'rsatilganidek, MLflow 1 dan 5 gacha bo'lgan baholash tizimidan, Ragas 0 va 1 dan foydalanadi, LlamaIndex'ning prompti esa baholovchidan HA va YO'Q deb javob berishni so'raydi.
| Vosita | Prompt [qisqalik uchun qisman qisqartirilgan] | Baholash tizimi |
|---|---|---|
MLflow | Ishonchlilik faqat taqdim etilgan natija va taqdim etilgan kontekst bilan baholanadi, iltimos, ishonchlilikni baholashda taqdim etilgan kirishni butunlay e'tiborsiz qoldiring. Ishonchlilik taqdim etilgan natijaning qanchalik katta qismi taqdim etilgan kontekst bilan faktik jihatdan mos kelishini baholaydi.…Ishonchlilik: Quyida turli ballar uchun tafsilotlar keltirilgan:- 1-ball: Natijadagi da'volarning hech birini taqdim etilgan kontekstdan xulosa qilib bo'lmaydi.- 2-ball: … | 1–5 |
Ragas | Sizning vazifangiz — berilgan kontekstga asoslanib, bir qator bayonotlarning haqiqatga mosligini baholash. Har bir bayonot uchun, agar bayonotni kontekstga asoslanib tekshirish mumkin bo'lsa, 1 hukmini yoki agar bayonotni kontekstga asoslanib tekshirish mumkin bo'lmasa, 0 hukmini qaytarishingiz kerak. | 0 va 1 |
LlamaIndex | Iltimos, berilgan ma'lumot qismi kontekst tomonidan qo'llab-quvvatlanadimi yoki yo'qligini ayting.Siz HA yoki YO'Q bilan javob berishingiz kerak.Agar kontekstning biror qismi ma'lumotni qo'llab-quvvatlasa, hatto kontekstning aksariyati aloqador bo'lmasa ham, HA deb javob bering. Quyida ba'zi misollar keltirilgan.Ma'lumot: Olmali pirog odatda ikki qavatli bo'ladi.Kontekst: Olmali pirog mevali pirogdir… U odatda ikki qavatli bo'ladi, xamir ham nachinkaning ustida, ham ostida bo'ladi ...Javob: HA | HA va YO'Q |
Bu uchta vosita tomonidan chiqarilgan ishonchlilik ballari taqqoslanadigan bo'lmaydi. Agar biror (kontekst, javob) juftligi berilganda, MLflow 3 ga teng ishonchlilik balini bersa, Ragas 1 ni chiqarsa va LlamaIndex YO'Q deb chiqarsa, siz qaysi balldan foydalanardingiz?
Dastur vaqt o'tishi bilan rivojlanadi, lekin uni baholash usuli ideal holda o'zgarmas bo'lishi kerak. Shunday qilib, baholash metrikalaridan dasturning o'zgarishlarini kuzatish uchun foydalanish mumkin. Biroq, SI-baholovchilar ham SI dasturlaridir, bu esa ularning ham vaqt o'tishi bilan o'zgarishi mumkinligini anglatadi.
Tasavvur qiling, o'tgan oy dasturingizning izchillik (coherence) bali 90% edi, bu oy esa bu ball 92% ni tashkil qildi. Bu sizning dasturingizning izchilligi yaxshilanganini anglatadimi? Agar har ikkala holatda ham aynan bir xil SI-baholovchilar ishlatilganiga to'liq ishonchingiz komil bo'lmasa, bu savolga javob berish qiyin. Balki bu oydagi baholovchining prompti o'tgan oydagidan farq qilgandir? Balki siz biroz yaxshiroq ishlaydigan promptga o'tgandirsiz yoki bir hamkasbingiz o'tgan oydagi promptdagi imloviy xatoni tuzatgandir va bu oydagi baholovchi yumshoqroq baholayotgandir.
Agar ilova va SI-baholovchi turli jamoalar tomonidan boshqarilsa, bu holat ayniqsa chalkash bo'lishi mumkin. SI-baholovchi jamoasi dastur jamoasini xabardor qilmasdan baholovchilarni o'zgartirishi mumkin. Natijada, dastur jamoasi baholash natijalaridagi o'zgarishlarni baholovchilardagi o'zgarishlarga emas, balki xato qilib ilovadagi o'zgarishlarga bog'lashi mumkin.
Maslahat:
Agar siz baholovchi uchun ishlatilgan model va promptni ko'ra olmasangiz, hech qanday SI-baholovchiga ishonmang.
Baholash usullarini standartlashtirish vaqt talab etadi. Soha rivojlanib, ko'proq nazorat vositalari (guardrails) joriy etilgani sari, umid qilamanki, kelajakdagi SI-baholovchilar ancha standartlashtirilgan va ishonchli bo'lib boradi.
Xarajatlar va kechikishning ortishi
Siz SI-baholovchilardan dasturlarni ham eksperiment paytida, ham real amaliyotda baholash uchun foydalanishingiz mumkin. Ko'plab jamoalar xavflarni kamaytirish uchun real amaliyotda SI-baholovchilardan nazorat vositasi sifatida foydalanadilar va foydalanuvchilarga faqat SI-baholovchi tomonidan yaxshi deb topilgan generatsiya qilingan javoblarni ko'rsatadilar.
Javoblarni baholash uchun qudratli modellardan foydalanish qimmatga tushishi mumkin. Agar ham javoblarni generatsiya qilish, ham baholash uchun GPT-4'dan foydalansangiz, ikki baravar ko'p GPT-4 chaqiruvlarini amalga oshirasiz, bu esa API xarajatlaringizni taxminan ikki baravar oshiradi. Agar sizda uchta mezonni — aytaylik, umumiy javob sifati, faktik izchillik va toksiklikni — baholash uchun uchta alohida baholash prompti bo'lsa, bu umumiy API chaqiruvlari sonini to'rttaga yetkazadi, ya'ni xarajatlaringiz to'rt baravar ortadi.3
Siz xarajatlarni baholovchi sifatida zaifroq modellardan foydalanish orqali kamaytirishingiz mumkin ("Qaysi modellar baholovchi sifatida harakat qila oladi?" bo'limiga qarang). Shuningdek, tanlab tekshirish (spot-checking) orqali ham xarajatlarni kamaytirishingiz mumkin: ya'ni, javoblarning faqat bir qismini baholash orqali.4 Tanlab tekshirish ba'zi nosozliklarni o'tkazib yuborishingiz mumkinligini anglatadi. Siz baholaydigan namunalar foizi qanchalik katta bo'lsa, baholash natijalaringizga bo'lgan ishonchingiz shunchalik yuqori bo'ladi, lekin xarajatlar ham shunchalik yuqori bo'ladi. Xarajat va ishonch o'rtasidagi to'g'ri muvozanatni topish sinov va xatolarni talab qilishi mumkin. Bu jarayon 4-bobda batafsilroq muhokama qilinadi. Barcha omillarni hisobga olganda, SI-baholovchilar inson baholovchilardan ancha arzonroqdir.
SI-baholovchilarni real amaliyotdagi jarayonlar zanjiriga (production pipeline) joriy etish kechikishni oshirishi mumkin. Agar siz javoblarni foydalanuvchilarga qaytarishdan oldin baholasangiz, tanlovga duch kelasiz: kamaytirilgan xavf, lekin ortgan kechikish. Qo'shimcha kechikish bu variantni qat'iy kechikish talablariga ega bo'lgan dasturlar uchun imkonsiz qilib qo'yishi mumkin.
SI-baholovchining noxolisliklari
Inson baholovchilarida noxolisliklar (biases) bo'lganidek, SI-baholovchilarda ham bor. Turli SI-baholovchilar turli xil noxolisliklarga ega. Ushbu bo'limda ularning eng keng tarqalganlaridan ba'zilari muhokama qilinadi. SI-baholovchilaringizning noxolisliklaridan xabardor bo'lish ularning ballarini to'g'ri talqin qilishga va hatto bu noxolisliklarni yumshatishga yordam beradi.
SI-baholovchilar o'ziga yon bosishga (self-bias) moyil bo'ladi, bunda model boshqa modellar tomonidan generatsiya qilingan javoblarga qaraganda o'zining javoblarini afzal ko'radi. Modelga eng ehtimoliy javobni generatsiya qilishga yordam beradigan o'sha mexanizm bu javobga yuqori ball ham beradi. Zheng va boshqalarning 2023-yilgi tajribasida, GPT-4 o'ziga 10% yuqoriroq g'alaba ko'rsatkichi bilan yon bosgan, Claude-v1 esa o'ziga 25% yuqoriroq g'alaba ko'rsatkichi bilan yon bosgan.
Ko'pgina SI modellarida birinchi pozitsiyaga moyillik (first-position bias) mavjud. SI-baholovchi juftlik taqqoslashida birinchi javobni yoki variantlar ro'yxatidagi birinchisini afzal ko'rishi mumkin. Buni bir xil testni har xil tartibda yoki puxta ishlab chiqilgan promptlar bilan bir necha marta takrorlash orqali yumshatish mumkin. SI'ning pozitsiyaga moyilligi insonlarnikiga teskari. Insonlar o'zlari oxirgi ko'rgan javobni afzal ko'rishga moyil bo'lib, bu so'nggi taassurot ta'siri (recency bias) deb ataladi.
Ba'zi SI-baholovchilar ko'p so'zlilikka moyillikka (verbosity bias) ega bo'lib, sifatidan qat'i nazar, uzunroq javoblarni afzal ko'rishadi. Wu va Aji (2023) ham GPT-4, ham Claude-1 qisqaroq, to'g'ri javoblarga (~50 so'z) qaraganda faktik xatolarga ega bo'lgan uzunroq javoblarni (~100 so'z) afzal ko'rishini aniqladilar. Saito va boshqalar (2023) bu noxolislikni ijodiy vazifalar uchun o'rganib, uzunlik farqi yetarlicha katta bo'lganda (masalan, bir javob ikkinchisidan ikki baravar uzun bo'lganda), baholovchi deyarli har doim uzunrog'ini afzal ko'rishini aniqladilar.5 Biroq, ham Zheng va boshqalar (2023), ham Saito va boshqalar (2023) GPT-4'ning bu noxolislikka GPT-3.5'ga qaraganda kamroq moyil ekanligini aniqladilar, bu esa modellar kuchaygan sari bu noxolislik yo'qolishi mumkinligini ko'rsatadi.
Bu barcha noxolisliklar ustiga, SI-baholovchilar barcha SI dasturlari bilan bir xil cheklovlarga ega, jumladan, maxfiylik va intellektual mulk (IP) masalalari. Agar siz baholovchi sifatida xususiy modeldan foydalansangiz, siz o'z ma'lumotlaringizni ushbu modelga yuborishingiz kerak bo'ladi. Agar model provayderi o'zining o'qitish ma'lumotlarini oshkor qilmasa, siz baholovchining tijorat maqsadlarida foydalanish uchun xavfsiz ekanligiga amin bo'la olmaysiz.
SI-baholovchi yondashuvining cheklovlariga qaramay, uning ko'plab afzalliklari meni uning qo'llanilishi o'sishda davom etishiga ishontiradi. Biroq, SI-baholovchilar aniq baholash usullari va/yoki inson baholashi bilan to'ldirilishi kerak.
Qaysi modellar baholovchi sifatida harakat qila oladi?
Baholovchi baholanayotgan modeldan kuchliroq, zaifroq yoki u bilan bir xil bo'lishi mumkin. Har bir holatning o'z afzalliklari va kamchiliklari bor.
Kuchliroq baholovchi
Bir qarashda, kuchliroq baholovchi mantiqan to'g'ri ko'rinadi. Axir, imtihon oluvchi imtihon topshiruvchidan bilimdonroq bo'lishi kerak emasmi? Kuchliroq modellar nafaqat yaxshiroq xulosalar chiqara oladi, balki ular zaifroq modellarni yaxshiroq javoblar generatsiya qilishga yo'naltirish orqali ularni takomillashtirishga ham yordam berishi mumkin.
Sizda savol tug'ilishi mumkin: agar sizda allaqachon kuchliroq modeldan foydalanish imkoniyati bo'lsa, javoblarni generatsiya qilish uchun nega zaifroq model bilan ovora bo'lish kerak? Javob — xarajat va kechikishdadir. Barcha javoblarni generatsiya qilish uchun kuchliroq modeldan foydalanishga byudjetingiz yetmasligi mumkin, shuning uchun undan javoblarning bir qismini baholash uchun foydalanasiz. Masalan, javoblarni generatsiya qilish uchun arzon ichki modelingizdan foydalanib, javoblarning 1 foizini baholash uchun GPT-4'dan foydalanishingiz mumkin.
Kuchliroq model dasturingiz uchun juda sekin bo'lishi ham mumkin. Siz javoblarni generatsiya qilish uchun tezkor modeldan foydalanishingiz, kuchliroq, lekin sekinroq model esa fon rejimida baholashni amalga oshirishi mumkin. Agar kuchli model zaif modelning javobini yomon deb hisoblasa, tuzatish choralari ko'rilishi mumkin, masalan, javobni kuchli modelniki bilan yangilash. Shuni unutmangki, teskari holat ham keng tarqalgan. Javoblarni generatsiya qilish uchun kuchli modeldan foydalanasiz, zaifroq model esa fon rejimida baholashni amalga oshiradi.
Kuchliroq modelni baholovchi sifatida ishlatish bizni ikkita muammo bilan yuzma-yuz qoldiradi. Birinchidan, eng kuchli modelning o'zi munosib baholovchisiz qoladi. Ikkinchidan, qaysi model eng kuchli ekanligini aniqlash uchun bizga muqobil baholash usuli kerak bo'ladi.
O'z-o'zini baholash
Modelni o'zini baholash uchun ishlatish, ya'ni o'z-o'zini baholash (self-evaluation) yoki o'z-o'zini tanqid qilish (self-critique) uchun ishlatish, ayniqsa o'ziga yon bosish (self-bias) tufayli, g'irromlikdek tuyulishi mumkin. Biroq, o'z-o'zini baholash boshlang'ich tekshiruvlar (sanity checks) uchun g'oyatda yaxshi bo'lishi mumkin. Agar model o'z javobini noto'g'ri deb hisoblasa, demak, u unchalik ishonchli bo'lmasligi mumkin. Boshlang'ich tekshiruvlardan tashqari, modeldan o'zini baholashni so'rash uni o'z javoblarini qayta ko'rib chiqishga va yaxshilashga undashi mumkin (Press va boshq., 2022; Gou va boshq., 2023; Valmeekamet va boshq., 2023).6 Quyidagi misol o'z-o'zini baholash qanday ko'rinishda bo'lishi mumkinligini ko'rsatadi:
Zaifroq baholovchi
Ochiq qolayotgan savollardan biri — baholovchi baholanayotgan modeldan zaifroq bo'lishi mumkinmi. Ba'zilar baholash generatsiya qilishdan ko'ra osonroq vazifa, deb ta'kidlashadi. Har kim biror qo'shiqning yaxshi yoki yomonligi haqida o'z fikriga ega bo'lishi mumkin, lekin hamma ham qo'shiq yoza olmaydi. Demak, zaifroq modellar kuchliroq modellarning natijalarini baholay olishi kerak.
Zheng va boshqalar (2023) kuchliroq modellar inson xohish-istaklari bilan yaxshiroq korrelyatsiyaga ega ekanligini aniqladilar, bu esa odamlarni o'zlarining qurbi yetadigan eng kuchli modellarni tanlashga undaydi. Biroq, bu tajriba umumiy maqsadli baholovchilar bilan cheklangan edi. Meni hayajonga solayotgan tadqiqot yo'nalishlaridan biri — bu kichik, ixtisoslashgan baholovchilardir. Ixtisoslashgan baholovchilar muayyan mezonlardan foydalangan holda va muayyan baholash tizimlariga rioya qilgan holda, aniq hukmlar chiqarishga o'rgatiladi. Kichik, ixtisoslashgan baholovchi muayyan hukmlar uchun kattaroq, umumiy maqsadli baholovchilarga qaraganda ishonchliroq bo'lishi mumkin.
SI-baholovchilardan foydalanishning ko'plab usullari mavjud bo'lgani uchun, ixtisoslashgan SI-baholovchilar ham ko'p bo'lishi mumkin. Bu yerda men uchta ixtisoslashgan baholovchiga misollar keltirib o'taman: mukofot modellari, etalonga asoslangan baholovchilar va afzallik modellari:
-
Mukofot modeli (Reward model): Mukofot modeli (prompt, javob) juftligini qabul qiladi va promptga nisbatan javobning qanchalik yaxshi ekanligini baholaydi. Mukofot modellari ko'p yillar davomida RLHF'da muvaffaqiyatli ishlatilib kelinmoqda.
CappyGoogle (2023) tomonidan ishlab chiqilgan mukofot modeliga bir misoldir. (Prompt, javob) juftligi berilganda,Cappyjavobning qanchalik to'g'ri ekanligini bildiruvchi 0 va 1 oralig'ida ball chiqaradi.Cappy360 million parametrga ega yengil baholovchi bo'lib, umumiy maqsadli fundamental modellardan ancha kichikdir. -
Etalonga asoslangan baholovchi (Reference-based judge): Etalonga asoslangan baholovchi generatsiya qilingan javobni bir yoki bir nechta etalon javoblarga nisbatan baholaydi. Bu baholovchi o'xshashlik balini yoki sifat balini (generatsiya qilingan javob etalon javoblarga nisbatan qanchalik yaxshi ekanligi) chiqarishi mumkin. Masalan,
BLEURT(Sellam va boshq., 2020) (nomzod javob, etalon javob) juftligini qabul qiladi va nomzod va etalon javob o'rtasidagi o'xshashlik balini chiqaradi.7Prometheus(Kim va boshq., 2023) esa (prompt, generatsiya qilingan javob, etalon javob, baholash mezoni)ni qabul qiladi va etalon javob 5 ball oladi deb faraz qilib, 1 dan 5 gacha bo'lgan sifat balini chiqaradi. -
Afzallik modeli (Preference model): Afzallik modeli (prompt, 1-javob, 2-javob)ni kirish sifatida qabul qiladi va berilgan prompt uchun ikki javobdan qaysi biri yaxshiroq (foydalanuvchilar tomonidan afzal ko'rilgan) ekanligini chiqaradi. Bu, ehtimol, ixtisoslashgan baholovchilar uchun eng qiziqarli yo'nalishlardan biridir. Inson xohish-istaklarini bashorat qila olish ko'plab imkoniyatlarni ochadi. 2-bobda muhokama qilinganidek, afzallik ma'lumotlari SI modellarini inson afzalliklariga moslashtirish uchun muhim ahamiyatga ega va uni olish qiyin hamda qimmat. Yaxshi inson xohish-istaklari bashoratchisiga ega bo'lish, umuman olganda, baholashni osonlashtirishi va modellarni ishlatish uchun xavfsizroq qilishi mumkin. Afzallik modellarini yaratish bo'yicha ko'plab tashabbuslar mavjud, jumladan,
PandaLM(Wang va boshq., 2023) vaJudgeLM(Zhu va boshq., 2023). 3-9-rasmdaPandaLMqanday ishlashiga misol ko'rsatilgan. U nafaqat qaysi javob yaxshiroq ekanligini chiqaradi, balki o'zining asoslanishini ham tushuntiradi.
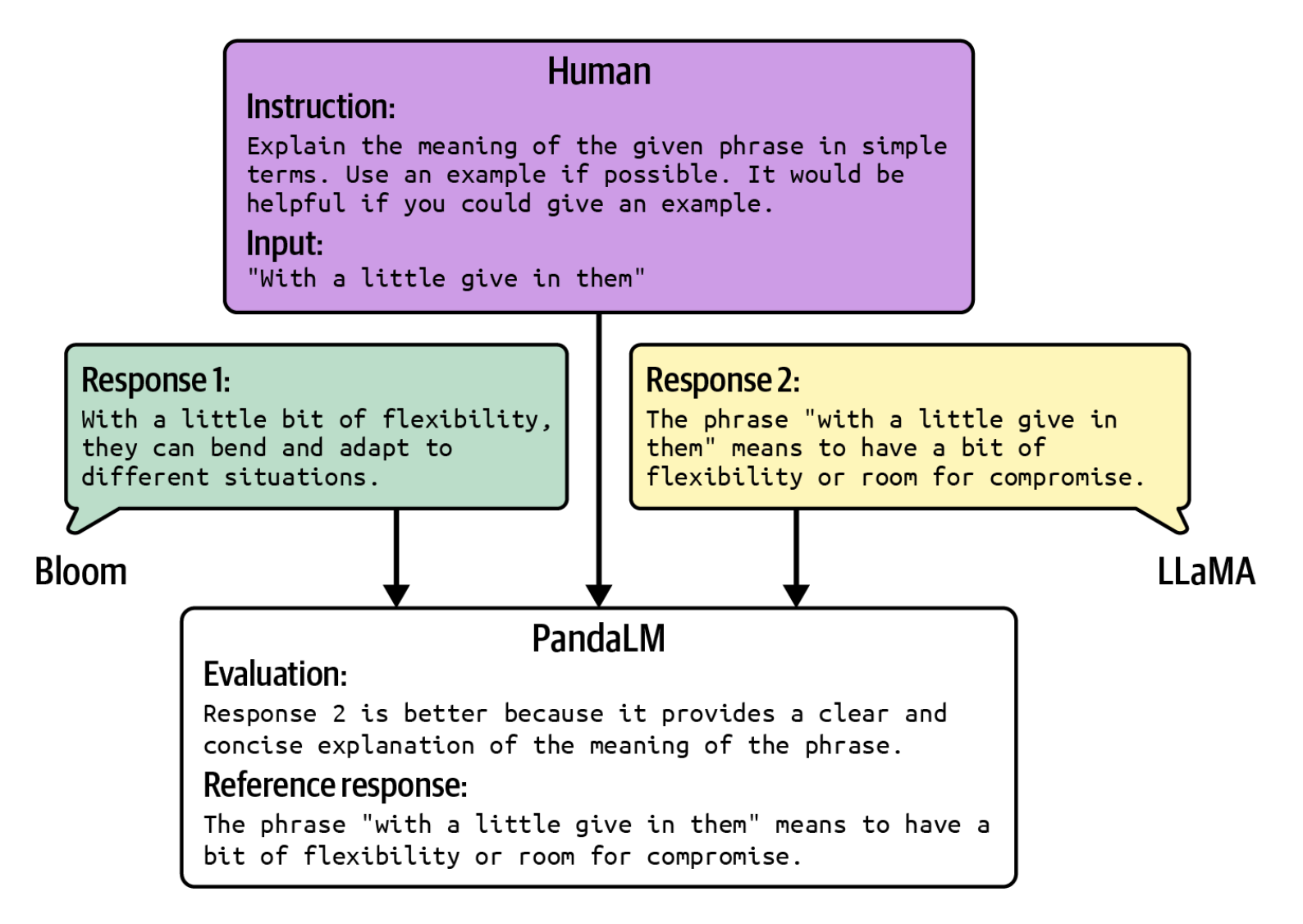
PandaLM'ning inson prompti va ikkita generatsiya qilingan javob berilgandagi natijasiga misol. Rasm Wang va boshqalar (2023) ishidan olingan, o'qish uchun biroz o'zgartirilgan. Asl rasm Apache License 2.0 litsenziyasi ostida mavjud.O'zining cheklovlariga qaramay, SI-baholovchi yondashuvi ko'p qirrali va qudratlidir. Baholovchi sifatida arzonroq modellardan foydalanish uni yanada foydaliroq qiladi. Dastlab shubha bilan qaragan ko'plab hamkasblarim real amaliyotda unga ko'proq tayana boshladilar.
SI-baholovchi yondashuvi qiziqarli va biz muhokama qiladigan keyingi yondashuv ham xuddi shunday jozibador. U maftunkor soha bo'lgan o'yin dizaynidan ilhomlangan.
Izohlar
-
SI-baholovchi (AI as a judge) atamasini SI'ning sudda hakam sifatida ishlatilishi qo'llanish holati bilan adashtirmaslik kerak. ↩
-
2017-yilda men
NeurIPSseminarida MEWR (Machine translation Evaluation metric Without Reference text) — mashina tarjimalarini avtomatik baholash uchun kuchliroq til modellaridan foydalanadigan baholash usulini taqdim etganman. Afsuski, ba'zi bir hayotiy sabablarga ko'ra bu tadqiqot yo'nalishini ortiq davom ettirmadim. ↩ -
Ba'zi hollarda, baholash byudjetning asosiy qismini, hatto javob generatsiyasidan ham ko'proqni egallashi mumkin. ↩
-
"Spot-checking" sampling bilan bir xil. ↩
-
Saito va boshqalar (2023) insonlar ham uzunroq javoblarni afzal ko'rishlarini, ammo ancha kamroq darajada ekanligini aniqladilar. ↩
-
Bu texnika ba'zan o'z-o'zini tanqid qilish (
self-critique) yoki o'z-o'zidan so'rash (self-ask) deb ataladi. ↩ -
BLEURTballar diapazoni chalkash. U taxminan -2.5 va 1.0 oralig'ida. Bu SI-baholovchilar bilan benchmarkning noaniqligi muammosini ko'rsatadi: ballar diapazoni ixtiyoriy bo'lishi mumkin. ↩