Aniq baholash
Modellar samaradorligini baholashda aniq (exact) va subyektiv (subjective) baholashni farqlash muhimdir. Aniq baholash hech qanday noaniqliksiz xulosa chiqaradi. Masalan, agar ko'p tanlovli savolning javobi A bo'lsa va siz B ni tanlasangiz, javobingiz noto'g'ri. Bunda hech qanday noaniqlik yo'q. Boshqa tomondan, inshoni baholash subyektivdir. Inshoning bahosi uni kim tekshirayotganiga bog'liq. Bir xil odam, agar bir muncha vaqt o'tib ikki marta so'ralsa, bir xil inshoga turli ballar berishi mumkin. Inshoni baholash aniq baholash mezonlari bilan aniqroq bo'lishi mumkin. Keyingi bo'limda ko'rib o'tadigan "SI — baholovchi" yondashuvi subyektivdir. Baholash natijasi baholovchi modelga va promptga qarab o'zgarishi mumkin.
Men aniq ballar beradigan ikkita baholash yondashuvini yoritib beraman: funksional to'g'rilik (functional correctness) va etalon ma'lumotlarga nisbatan o'xshashlikni o'lchash. Shuni unutmangki, ushbu bo'lim cheklangan natijali (close-ended) javoblarga (masalan, tasniflash) emas, balki erkin natijali (open-ended) javoblarni (ixtiyoriy matn generatsiyasi) baholashga qaratilgan. Bu fundamental modellar cheklangan natijali vazifalar uchun ishlatilmayotgani uchun emas. Aslida, ko'plab fundamental model tizimlari kamida bitta tasniflash komponentiga ega, odatda niyatni tasniflash (intent classification) yoki ball qo'yish (scoring) uchun. Ushbu bo'lim erkin natijali baholashga qaratilgan, chunki cheklangan natijali baholash allaqachon yaxshi o'rganilgan.
Funksional to'g'rilik
Funksional to'g'rilikni baholash (Functional correctness evaluation) tizimni u mo'ljallangan funksionallikni bajarayotganiga qarab baholashni anglatadi. Masalan, agar siz modeldan veb-sayt yaratishni so'rasangiz, generatsiya qilingan veb-sayt sizning talablaringizga javob beradimi? Agar siz modeldan ma'lum bir restoranda joy band qilishni so'rasangiz, model buni uddalaydimi?
Funksional to'g'rilik har qanday dastur samaradorligini baholash uchun eng asosiy metrikadir, chunki u sizning dasturingiz o'ziga yuklatilgan vazifani bajarayotganini o'lchaydi. Biroq, funksional to'g'rilikni o'lchash har doim ham oson emas va uni osonlikcha avtomatlashtirib bo'lmaydi.
Kod generatsiyasida funksional to'g'rilik
Kod generatsiyasi — bu funksional to'g'rilikni o'lchashni avtomatlashtirish mumkin bo'lgan vazifaga bir misoldir. Kodlashda funksional to'g'rilik ba'zan bajarilish aniqligi (execution accuracy) deb ham ataladi. Aytaylik, siz modeldan ikki son, num1 va num2'ning eng katta umumiy bo'luvchisini (gcd) topadigan gcd(num1, num2) Python funksiyasini yozishni so'radingiz. Keyin generatsiya qilingan kodni Python interpretatoriga kiritib, kodning to'g'riligini va agar to'g'ri bo'lsa, u berilgan (num1, num2) juftligi uchun to'g'ri natija chiqarishini tekshirish mumkin. Masalan, (num1=15, num2=20) juftligi berilganda, agar gcd(15, 20) funksiyasi to'g'ri javob bo'lgan 5 ni qaytarmasa, siz funksiyaning noto'g'ri ekanligini bilasiz.
SI kod yozish uchun ishlatilishidan ancha oldin ham, kodning funksional to'g'riligini avtomatik tekshirish dasturiy ta'minot muhandisligida standart amaliyot bo'lgan. Kod odatda unit testlar yordamida tekshiriladi, bunda kod kutilgan natijalarni generatsiya qilishiga ishonch hosil qilish uchun turli senariylarda ishga tushiriladi. Funksional to'g'rilikni baholash — bu LeetCode va HackerRank kabi kodlash platformalarining taqdim etilgan yechimlarni tekshirish usulidir.
SI'ning kod generatsiyasi qobiliyatlarini baholash uchun OpenAI'ning HumanEval va Google'ning MBPP (Mostly Basic Python Problems Dataset) kabi ommabop benchmarklar o'z metrikalari sifatida funksional to'g'rilikdan foydalanadi. Matndan-SQL'ga (tabiiy tillardan SQL so'rovlarini generatsiya qilish) uchun Spider (Yu va boshq., 2018), BIRD-SQL (Big Bench for Large-scale Database Grounded Text-to-SQL Evaluation) (Li va boshq., 2023) va WikiSQL (Zhong va boshq., 2017) kabi benchmarklar ham funksional to'g'rilikka tayanadi.
Benchmark muammosi test holatlari to'plami bilan birga keladi. Har bir test holati kod ishlashi kerak bo'lgan senariydan va o'sha senariy uchun kutilgan natijadan iborat. Quyida, HumanEval'dagi muammo va uning test holatlariga misol:
Modelni baholashda har bir muammo uchun deb belgilangan bir nechta kod namunalari generatsiya qilinadi. Agar model generatsiya qilgan ta kod namunasidan birortasi o'sha muammoning barcha test holatlaridan o'tsa, model muammoni yechgan hisoblanadi. Yakuniy ball, pass@k deb ataladi va u yechilgan muammolarning barcha muammolarga nisbatidir. Agar 10 ta muammo bo'lsa va model bo'lganda 5 tasini yechsa, unda o'sha modelning pass@3 bali 50% bo'ladi. Model qancha ko'p kod namunasi generatsiya qilsa, uning har bir muammoni yechish imkoniyati shuncha ko'p bo'ladi, demak, yakuniy ball ham shuncha yuqori bo'ladi. Bu shuni anglatadiki, kutilganidek, pass@1 bali pass@3'dan pastroq, u esa, o'z navbatida, pass@10'dan pastroq bo'lishi kerak.
Funksional to'g'riligini avtomatik baholash mumkin bo'lgan yana bir vazifalar toifasi — bu o'yin botlaridir. Agar siz Tetris o'ynash uchun bot yaratsangiz, botning qanchalik yaxshi ekanligini u olgan ball orqali bilib olishingiz mumkin. O'lchanadigan maqsadlarga ega bo'lgan vazifalarni odatda funksional to'g'rilik yordamida baholash mumkin. Masalan, agar siz SI'dan energiya sarfini optimallashtirish uchun ish yuklamalaringizni rejalashtirishni so'rasangiz, SI'ning samaradorligini u qancha energiya tejagani bilan o'lchash mumkin.1
Etalon ma'lumotlarga nisbatan o'xshashlikni o'lchash
Agar sizni qiziqtirgan vazifani funksional to'g'rilik yordamida avtomatik baholab bo'lmasa, keng tarqalgan yondashuvlardan biri — bu SI natijalarini etalon ma'lumotlarga (reference data) nisbatan baholashdir. Masalan, agar siz modeldan biror jumlani fransuz tilidan ingliz tiliga tarjima qilishni so'rasangiz, siz generatsiya qilingan inglizcha tarjimani to'g'ri inglizcha tarjimaga nisbatan baholashingiz mumkin.
Etalon ma'lumotlardagi har bir misol (kirish, etalon javoblar) formatiga amal qiladi. Bir kirish ma'lumoti bir nechta etalon javobga ega bo'lishi mumkin, masalan, bir fransuzcha jumlaning bir nechta ehtimoliy inglizcha tarjimasi. Etalon javoblar, shuningdek, etalon haqiqatlar (ground truths) yoki kanonik javoblar (canonical responses) deb ham ataladi. Etalonlarni talab qiladigan metrikalar etalonga asoslangan (reference-based), talab qilmaydiganlar esa etalonsiz (reference-free) deyiladi.
Bu baholash yondashuvi etalon ma'lumotlarni talab qilgani uchun, u etalon ma'lumotlarning qancha miqdorda va qanchalik tez generatsiya qilinishi bilan cheklanadi. Etalon ma'lumotlar odatda insonlar tomonidan va tobora ko'proq SI'lar tomonidan generatsiya qilinadi. Etalon sifatida inson tomonidan yaratilgan ma'lumotlardan foydalanish, biz inson samaradorligini oltin standart deb bilishimizni va SI samaradorligi inson samaradorligiga nisbatan o'lchanishini anglatadi. Inson tomonidan yaratilgan ma'lumotlarni generatsiya qilish qimmat va ko'p vaqt talab qilishi mumkin, bu esa ko'pchilikni buning o'rniga etalon ma'lumotlarni generatsiya qilish uchun SI'dan foydalanishga undaydi. SI tomonidan yaratilgan ma'lumotlar hali ham inson tekshiruvini talab qilishi mumkin, ammo uni ko'rib chiqish uchun zarur bo'lgan mehnat etalon ma'lumotlarni noldan yaratish uchun zarur bo'lgan mehnatdan ancha kam.
Etalon javoblarga qanchalik o'xshash bo'lsa, generatsiya qilingan javoblar shunchalik yaxshi hisoblanadi. Ikkita erkin matn o'rtasidagi o'xshashlikni o'lchashning to'rtta usuli mavjud:
- Baholovchidan xulosa so'rash: ikkita matn bir xil yoki yo'qligi haqida xulosa chiqarishni so'rash.
- Aniq moslik (Exact match): generatsiya qilingan javob etalon javoblardan biriga aniq mos keladimi yoki yo'qmi.
- Leksik o'xshashlik (Lexical similarity): generatsiya qilingan javob etalon javoblarga tashqi ko'rinishidan qanchalik o'xshashligi.
- Semantik o'xshashlik (Semantic similarity): generatsiya qilingan javobning ma'no jihatdan (semantik jihatdan) etalon javoblarga qanchalik yaqinligi.
Ikkita javobni inson baholovchilari yoki SI baholovchilari taqqoslashi mumkin. SI baholovchilari tobora ommalashib bormoqda va keyingi bo'limning diqqat markazida bo'ladi.
Ushbu bo'limda qo'lda ishlab chiqilgan metrikalarga e'tibor qaratiladi: aniq moslik, leksik o'xshashlik va semantik o'xshashlik. Aniq moslik bo'yicha ballar ikkilik (mos keladi yoki yo'q), qolgan ikkitasi esa siljuvchi shkala bo'yicha (masalan, 0 va 1 yoki -1 va 1 oralig'ida) bo'ladi. "SI — baholovchi" yondashuvining foydalanish qulayligi va moslashuvchanligiga qaramay, qo'lda ishlab chiqilgan o'xshashlik o'lchovlari o'zlarining aniq tabiati tufayli sohada hali ham keng qo'llaniladi.
Eslatma
Ushbu bo'limda generatsiya qilingan natija sifatini baholash uchun o'xshashlik o'lchovlaridan qanday foydalanish mumkinligi muhokama qilinadi. Biroq, o'xshashlik o'lchovlaridan boshqa ko'plab ishlatilish senariylarida ham foydalanishingiz mumkin, jumladan, lekin ular bilan cheklanmagan holda:
- Qidiruv va topish: so'rovga o'xshash elementlarni topish.
- Reytinglash: elementlarni so'rovga qanchalik o'xshashligiga qarab tartiblash.
- Klasterlash: elementlarni bir-biriga qanchalik o'xshashligiga qarab guruhlash.
- Anomaliyalarni aniqlash: qolganlariga eng kam o'xshash bo'lgan elementlarni aniqlash.
- Ma'lumotlardagi takrorlanishlarni olib tashlash: boshqa elementlarga juda o'xshash bo'lgan elementlarni olib tashlash.
Ushbu bo'limda muhokama qilingan texnikalar kitob davomida yana qayta tilga olinadi.
Aniq moslik
Agar generatsiya qilingan javob etalon javoblardan biriga aniq mos kelsa, bu aniq moslik (exact match) hisoblanadi. Aniq moslik oddiy matematik masalalar, umumiy bilimga oid so'rovlar va viktorina uslubidagi savollar kabi qisqa, aniq javoblar kutiladigan vazifalar uchun ishlaydi. Quyida, qisqa, aniq javoblarga ega bo'lgan kirish ma'lumotlariga misollar keltirilgan:
- "2 + 3 nechiga teng?"
- "Nobel mukofotini qo'lga kiritgan birinchi ayol kim bo'lgan?"
- "Mening joriy hisobimdagi balans qancha?"
- "Bo'sh joyni to'ldiring: Parij Fransiyaga qanday aloqador bo'lsa, ___ Angliyaga shunday aloqador."
Formatlash muammolarini hisobga oladigan moslashtirishning turlari ham mavjud. Bir turi — bu etalon javobni o'z ichiga olgan har qanday natijani mos kelgan deb qabul qilish. "2 + 3 nechiga teng?" savolini ko'rib chiqaylik. Etalon javob — "5". Bu tur "5" ni o'z ichiga olgan barcha natijalarni, jumladan, "Javob 5" va "2 + 3 javobi 5 ga teng" kabilarni ham qabul qiladi.
Biroq, bu tur ba'zan noto'g'ri yechimning qabul qilinishiga olib kelishi mumkin. "Anna Frank qaysi yili tug'ilgan?" savolini ko'rib chiqaylik. Anna Frank 1929-yil 12-iyunda tug'ilgan, shuning uchun to'g'ri javob 1929. Agar model "1929-yil 12-sentabr" deb chiqarsa, to'g'ri yil natijada mavjud, ammo natija faktik jihatdan noto'g'ri.
Oddiy vazifalardan tashqari, aniq moslik kamdan-kam hollarda ishlaydi. Asl fransuzcha "Comment ça va?" jumlasi berilganda, "How are you?", "How is everything?" va "How are you doing?" kabi bir nechta ehtimoliy inglizcha tarjimalar mavjud. Agar etalon ma'lumotlarda faqat shu uchta tarjima bo'lsa va model "How is it going?" deb generatsiya qilsa, modelning javobi noto'g'ri deb belgilanadi. Asl matn qanchalik uzun va murakkab bo'lsa, ehtimoliy tarjimalar shunchalik ko'p bo'ladi. Bitta kirish ma'lumoti uchun ehtimoliy javoblarning to'liq to'plamini yaratishning iloji yo'q. Murakkab vazifalar uchun leksik o'xshashlik va semantik o'xshashlik yaxshiroq ishlaydi.
Leksik o'xshashlik
Leksik o'xshashlik (Lexical similarity) ikkita matnning qanchalik bir-biriga mos kelishini, ya'ni qancha umumiy qismga ega ekanligini o'lchaydi. Buni amalga oshirish uchun avvalo har bir matnni kichikroq tokenlarga ajratib olish kerak.
Eng oddiy shaklda, leksik o'xshashlikni ikkita matnda qancha umumiy token borligini sanash orqali o'lchash mumkin. Misol uchun, "Mening mushuklarim sichqonlarni qo'rqitadi" etalon javobini va ikkita generatsiya qilingan javobni ko'rib chiqaylik:
- A javob: "Mening mushuklarim sichqonlarni yeydi"
- B javob: "Mushuklar va sichqonlar doim urishadi"
Har bir token so'z deb faraz qilaylik. Agar siz faqat alohida so'zlarning mos kelishini sanasangiz, A javob etalon javobdagi 5 ta so'zdan 4 tasini o'z ichiga oladi (o'xshashlik bali 80%), B javob esa faqat 3 tasini o'z ichiga oladi (o'xshashlik bali 60%). Shuning uchun, A javob etalon javobga ko'proq o'xshash hisoblanadi.
Taxminiy moslik va tahrirlash masofasi
Leksik o'xshashlikni o'lchashning bir usuli — bu taxminiy satr mosligi (approximate string matching), so'zlashuv tilida noaniq moslik (fuzzy matching) deb ham ataladi. U bir matndan ikkinchisiga o'tish uchun qancha tahrir kerakligini sanash orqali ikkita matn o'rtasidagi o'xshashlikni o'lchaydi, bu son tahrirlash masofasi (edit distance) deb ataladi. Odatdagi uchta tahrirlash amali quyidagilardir:
- O'chirish: "brad" -> "bad"
- Qo'shish: "bad" -> "bard"
- Almashtirish: "bad" -> "bed"
Ba'zi noaniq moslashtirgichlar, shuningdek, transpozitsiyani, ya'ni ikkita harfning o'rnini almashtirishni (masalan, "mats" -> "mast") ham bitta tahrir deb hisoblaydi. Biroq, ba'zi noaniq moslashtirgichlar har bir transpozitsiyani ikkita tahrirlash amali — bitta o'chirish va bitta qo'shish — deb hisoblaydi.
Masalan, "bad" so'zi "bard"ga bir tahrir masofasida, "cash"ga esa uch tahrir masofasida joylashgan, shuning uchun "bad" so'zi "cash"ga qaraganda "bard"ga ko'proq o'xshash hisoblanadi.
N-gramm o'xshashligi
Leksik o'xshashlikni o'lchashning yana bir usuli — bu n-gramm o'xshashligi (n-gram similarity) bo'lib, u alohida tokenlar o'rniga tokenlar ketma-ketligi, ya'ni n-grammlarning mos kelishiga asoslanib o'lchanadi. 1-gramm (unigramma) — bu bitta token. 2-gramm (bigramma) — bu ikkita tokenlar to'plami. "Mening mushuklarim sichqonlarni qo'rqitadi" jumlasi to'rtta bigrammadan iborat: "mening mushuklarim", "mushuklarim sichqonlarni", "sichqonlarni qo'rqitadi". Siz etalon javoblardagi n-grammlarning necha foizi generatsiya qilingan javobda ham mavjudligini o'lchaysiz.2
Leksik o'xshashlik uchun keng tarqalgan metrikalar BLEU, ROUGE, METEOR++, TER va CIDEr'dir. Ular mos kelishning aynan qanday hisoblanishi bilan farqlanadi. Fundamental modellardan oldin BLEU, ROUGE va ularning turdoshlari, ayniqsa, tarjima vazifalari uchun keng tarqalgan edi. Fundamental modellar paydo bo'lganidan beri kamroq benchmarklar leksik o'xshashlikdan foydalanadi. Ushbu metrikalardan foydalanadigan benchmarklarga misol qilib WMT, COCO Captions va GEMv2'ni keltirish mumkin.
Leksik o'xshashlikning kamchiliklari
Ushbu usulning kamchiligi shundaki, u etalon javoblarning keng qamrovli to'plamini saralashni talab qiladi. Agar etalon to'plamda unga o'xshash birorta ham javob bo'lmasa, yaxshi javob ham past o'xshashlik balini olishi mumkin. Ba'zi benchmark misollarida, Adept o'zining Fuyu modeli yomon natija ko'rsatganini aniqladi, bunga sabab model natijalarining noto'g'ri ekanligi emas, balki etalon ma'lumotlarda ba'zi to'g'ri javoblarning yetishmasligi edi. 3-5-rasmda tasvirga izoh berish vazifasiga misol keltirilgan, unda Fuyu to'g'ri izoh generatsiya qilgan, ammo past ball olgan.
Nafaqat bu, balki etalonlar ham noto'g'ri bo'lishi mumkin. Masalan, mashina tarjimasi uchun baholash metrikalarini o'rganishga qaratilgan "WMT 2023 Metrics" musobaqasi tashkilotchilari o'z ma'lumotlarida ko'plab yomon etalon tarjimalarni topganliklarini xabar qilishdi. Past sifatli etalon ma'lumotlar — bu inson xulosasi bilan bog'liqlik bo'yicha etalonsiz metrikalarning etalonga asoslangan metrikalar uchun kuchli raqobatchi bo'lishining sabablaridan biridir (Freitag va boshq., 2023).
Bu o'lchovning yana bir kamchiligi shundaki, yuqori leksik o'xshashlik ballari har doim ham yaxshiroq javoblarni anglatmaydi. Masalan, kod generatsiyasi benchmarki bo'lgan HumanEval'da OpenAI noto'g'ri va to'g'ri yechimlar uchun BLEU ballari o'xshash ekanligini aniqladi. Bu BLEU ballari uchun optimallashtirish funksional to'g'rilik uchun optimallashtirish bilan bir xil emasligini ko'rsatadi (Chen va boshq., 2021).

Fuyu to'g'ri variantni generatsiya qilgan, ammo etalon izohlarning cheklanganligi sababli past ball olgan misol.Semantik o'xshashlik
Leksik o'xshashlik ikkita matnning bir xil ma'noga ega ekanligini emas, balki tashqi ko'rinishidan o'xshashligini o'lchaydi. "What's up?" va "How are you?" jumlalarini ko'rib chiqaylik. Leksik jihatdan ular farq qiladi — ularda ishlatilgan so'zlar va harflarda deyarli umumiy qism yo'q. Biroq, semantik jihatdan ular yaqin. Aksincha, o'xshash ko'rinishdagi matnlar butunlay boshqa narsalarni anglatishi mumkin. "Keling, ovqatlanamiz, buvi" (Let's eat, grandma) va "Keling, buvini yeymiz" (Let's eat grandma) ikki mutlaqo farqli narsani anglatadi.
Semantik o'xshashlik (Semantic similarity) semantikadagi, ya'ni ma'nodagi o'xshashlikni hisoblashni maqsad qiladi. Bu avvalo matnni embedding deb ataladigan raqamli tasvirga aylantirishni talab qiladi. Masalan, "mushuk gilamda o'tiribdi" jumlasi [0.11, 0.02, 0.54] kabi ko'rinishdagi embedding yordamida ifodalanishi mumkin. Shu sababli, semantik o'xshashlik embedding o'xshashligi (embedding similarity) deb ham ataladi.
“Embedding'larga kirish” bo'limida embedding'lar qanday ishlashi muhokama qilinadi. Hozircha, matnlarni embedding'larga aylantirish usulingiz bor deb faraz qilaylik. Ikkita embedding o'rtasidagi o'xshashlikni kosinusli o'xshashlik (cosine similarity) kabi metrikalar yordamida hisoblash mumkin. Bir-biriga aynan o'xshash ikkita embedding 1 ga teng o'xshashlik baliga ega. Ikkita qarama-qarshi embedding esa -1 ga teng o'xshashlik baliga ega.
Men matn misollaridan foydalanayapman, lekin semantik o'xshashlikni tasvir va audio kabi istalgan ma'lumot modalligining embedding'lari uchun ham hisoblash mumkin. Matn uchun semantik o'xshashlik ba'zan semantik matn o'xshashligi (semantic textual similarity) deb ham ataladi.
Ogohlantirish
Garchi men semantik o'xshashlikni aniq baholash toifasiga kiritgan bo'lsam-da, uni subyektiv deb hisoblash mumkin, chunki turli embedding algoritmlari turli embedding'lar hosil qilishi mumkin. Biroq, ikkita embedding berilganda, ular o'rtasidagi o'xshashlik bali aniq hisoblanadi.
Matematik jihatdan, generatsiya qilingan javobning embedding'i, esa etalon javobning embedding'i bo'lsin. va o'rtasidagi kosinus o'xshashlik quyidagicha hisoblanadi: , bunda:
- — va ning skalyar ko'paytmasi.
- — ning Evklid normasi (shuningdek, norma deb ham ataladi). Agar bo'lsa, .
Semantik matn o'xshashligi uchun metrikalarga BERTScore (embedding'lar BERT tomonidan generatsiya qilinadi) va MoverScore (embedding'lar algoritmlar aralashmasi tomonidan generatsiya qilinadi) kiradi.
Matnning semantik o'xshashligi leksik o'xshashlik kabi keng qamrovli etalon javoblar to'plamini talab qilmaydi. Biroq, semantik o'xshashlikning ishonchliligi asosiy embedding algoritmining sifatiga bog'liq. Agar _embedding_lar yomon bo'lsa, bir xil ma'noga ega bo'lgan ikkita matn ham past semantik o'xshashlik baliga ega bo'lishi mumkin. Ushbu o'lchovning yana bir kamchiligi shundaki, asosiy embedding algoritmi ishlashi uchun salmoqli hisoblash quvvati va vaqt talab qilishi mumkin.
"SI — baholovchi" yondashuvini muhokama qilishdan oldin, keling, embedding'ga qisqacha kirish qilib o'tamiz. Embedding tushunchasi semantik o'xshashlikning markazida yotadi va u biz kitob davomida o'rganadigan ko'plab mavzular, jumladan, 6-bobdagi vektorli qidiruv (vector search) va 8-bobdagi ma'lumotlardagi takrorlanishlarni olib tashlash uchun asos bo'lib xizmat qiladi.
Embedding'larga kirish
Kompyuterlar sonlar bilan ishlagani uchun, model o'zining kirish ma'lumotlarini kompyuterlar qayta ishlay oladigan raqamli tasvirlarga aylantirishi kerak. Embedding — bu asl ma'lumotning ma'nosini o'zida aks ettirishni maqsad qilgan raqamli tasvirdir.
Embedding bu — vektor. Masalan, "mushuk gilamda o'tiribdi" jumlasi [0.11, 0.02, 0.54] kabi ko'rinishdagi embedding vektori yordamida ifodalanishi mumkin. Bu yerda men misol sifatida kichik bir vektordan foydalandim. Aslida, embedding vektorining o'lchami (embedding vektoridagi elementlar soni) odatda 100 dan 10 000 gacha bo'ladi.3
Aynan embedding'lar hosil qilish uchun o'qitilgan modellarga ochiq manbali BERT, CLIP (Kontrastiv Til-Tasvir Dastlabki O'qitish) va Sentence Transformers kabi modellar kiradi. Shuningdek, API sifatida taqdim etiladigan xususiy embedding modellari ham mavjud.4 3-2-jadvalda ba'zi ommabop modellarning embedding o'lchamlari ko'rsatilgan.
| Model | Embedding o'lchami |
|---|---|
"Google"ning BERT | BERT base: 768BERT large: 1024 |
"OpenAI"ning CLIP | Tasvir: 512 Matn: 512 |
"OpenAI" Embeddings API'si | text-embedding-3-small: 1536text-embedding-3-large: 3072 |
"Cohere"ning Embed v3 | embed-english-v3.0: 1024embed-english-light-3.0: 384 |
Modellar odatda o'zlarining kirish ma'lumotlarini avval vektor tasvirlariga aylantirishni talab qilgani uchun, GPT seriyasi va Llama seriyasi kabi ko'plab ML modellari ham embedding'lar generatsiya qilish bosqichini o'z ichiga oladi. "Transformer arxitekturasi" bo'limida Transformer modelidagi embedding qatlami vizualizatsiya qilingan. Agar siz ushbu modellarning oraliq qatlamlariga kira olsangiz, ulardan embedding'larni ajratib olish uchun foydalanishingiz mumkin. Biroq, bu embedding'larning sifati ixtisoslashgan embedding modellari tomonidan generatsiya qilingan embedding'lar kabi yaxshi bo'lmasligi mumkin.
Embedding algoritmining maqsadi — asl ma'lumotning mohiyatini aks ettiruvchi embedding'lar hosil qilishdir. Buni qanday tekshiramiz? [0.11, 0.02, 0.54] vektori asl "mushuk gilamda o'tiribdi" matniga hech o'xshamaydi-ku.
Umumiy olganda, agar o'xshashroq matnlar kosinusli o'xshashlik yoki shunga o'xshash metrikalar bilan o'lchanganda yaqinroq embedding'larga ega bo'lsa, embedding algoritmi yaxshi hisoblanadi. "Mushuk gilamda o'tiribdi" jumlasining embedding'i "it o'tloqda o'ynayapti" jumlasining embedding'iga "SI tadqiqotlari juda qiziqarli" jumlasining embedding'idan ko'ra yaqinroq bo'lishi kerak.
Siz, shuningdek, embedding'lar sifatini ularning sizning vazifangiz uchun foydaliligiga qarab baholashingiz mumkin. Embedding'lar tasniflash, mavzularni modellashtirish, tavsiya tizimlari va RAG kabi ko'plab vazifalarda ishlatiladi. Embedding sifatini bir nechta vazifalar bo'yicha o'lchaydigan benchmarklarga misol qilib MTEB, ya'ni Keng Qamrovli Matn Embedding benchmarkini (Massive Text Embedding Benchmark) (Muennighoff va boshq., 2023) keltirish mumkin.
Men misol sifatida matnlardan foydalanyapman, lekin har qanday ma'lumot embedding tasvirlariga ega bo'lishi mumkin. Masalan, Criteo va Coveo kabi elektron tijorat yechimlarida mahsulotlar uchun embedding'lar mavjud. Pinterest'da esa tasvirlar, grafiklar, so'rovlar va hatto foydalanuvchilar uchun ham embedding'lar bor.
Multimodal embedding'lar
Yangi bir yo'nalish — bu turli modallikdagi ma'lumotlar uchun qo'shma embedding'lar yaratishdir. CLIP (Radford va boshq., 2021) turli modallikdagi — matn va tasvirlardagi — ma'lumotlarni qo'shma embedding fazosiga o'tkaza olgan birinchi yirik modellardan biri edi. ULIP (til, tasvirlar va nuqtalar bulutining yagona tasviri) (Xue va boshq., 2022) matn, tasvirlar va 3D nuqtalar bulutining yagona tasvirlarini yaratishni maqsad qiladi. ImageBind (Girdhar va boshq., 2023) esa oltita turli modallik, jumladan, matn, tasvirlar va audio bo'ylab qo'shma embedding o'rganadi.
3-6-rasmda CLIP'ning arxitekturasi vizualizatsiya qilingan. CLIP (tasvir, matn) juftliklari yordamida o'qitiladi. Tasvirga mos keladigan matn bu tasvir bilan bog'liq bo'lgan izoh yoki sharh bo'lishi mumkin. Har bir (tasvir, matn) juftligi uchun CLIP matnni matn embedding'iga aylantirish uchun matn enkoderidan (text encoder) va tasvirni tasvir embedding'iga aylantirish uchun tasvir enkoderidan (image encoder) foydalanadi. Keyin u bu ikkala embedding'ni ham qo'shma embedding fazosiga proeksiya qiladi. O'qitish maqsadi — bu qo'shma fazoda biror tasvirning embedding'ini unga mos keladigan matnning embedding'iga yaqinlashtirishdir.
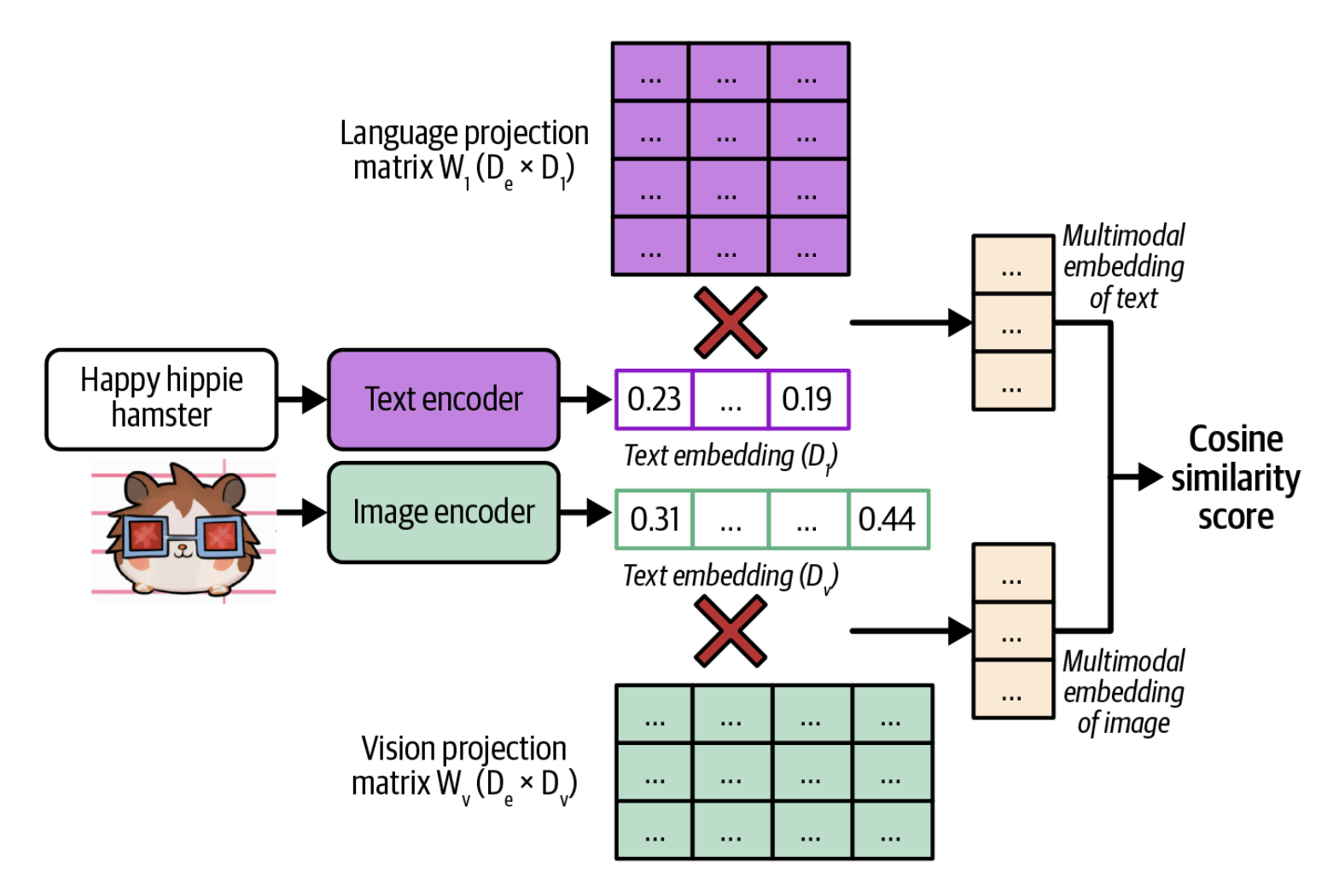
CLIP'ning arxitekturasi (Radford va boshq., 2021).Turli modallikdagi ma'lumotlarni ifodalay oladigan qo'shma embedding fazosi multimodal embedding fazosi deb ataladi. Matn-tasvir qo'shma embedding fazosida, baliq tutayotgan odam tasvirining embedding'i "moda namoyishi" matnining embedding'idan ko'ra "baliqchi" matnining embedding'iga yaqinroq bo'lishi kerak. Bu qo'shma embedding fazosi turli modallikdagi embedding'larni taqqoslash va birlashtirish imkonini beradi. Masalan, bu matnga asoslangan tasvir qidiruvini amalga oshirish imkoniyatini mavjud qiladi. Biror matn berilganda, u sizga ushbu matnga eng yaqin bo'lgan tasvirlarni topishga yordam beradi.
Izohlar
-
Muammo shundaki, ko'plab murakkab vazifalarning o'lchanadigan maqsadlari bo'lsa-da, SI murakkab vazifalarni boshidan oxirigacha bajarishda unchalik yaxshi emas, shuning uchun SI yechimning bir qismini bajarish uchun ishlatilishi mumkin. Ba'zan, yechimning bir qismini baholash yakuniy natijani baholashdan qiyinroq bo'ladi. Tasavvur qiling, siz kimningdir shaxmat o'ynash qobiliyatini baholamoqchisiz. Faqat bitta yurishni baholashdan ko'ra, o'yinning yakuniy natijasini (g'alaba/mag'lubiyat/durang) baholash osonroq. ↩
-
Shuningdek, siz "mushuklar" va "mushuk" yoki "bo'lmaydi" va "bo'midi" ikki alohida token deb hisoblanishini xohlaysizmi yoki yo'qligiga qarab, biroz ishlov berishni xohlashingiz mumkin. ↩
-
Garchi 10 000 elementli vektor fazosi yuqori o'lchamli tuyulsa-da, u xom ma'lumotlarning o'lchamidan ancha past. Shuning uchun, embedding murakkab ma'lumotlarning pastroq o'lchamli fazodagi tasviri hisoblanadi. ↩
-
Shuningdek,
word2vec(Mikolov va boshq., “Efficient Estimation of Word Representations in Vector Space”, arXiv, v3, 2013-yil 7-sentabr) vaGloVe(Pennington va boshq., “GloVe: Global Vectors for Word Representation”, Stenford Universiteti Tabiiy Tilni Qayta Ishlash Guruhi (blog), 2014) kabi hujjat embedding'laridan farqli o'laroq, so'z embedding'larini generatsiya qiladigan modellar ham mavjud. ↩