Fundamental modellarni baholashdagi qiyinchiliklar
ML modellarini baholash har doim qiyin bo'lgan. Fundamental modellar paydo bo'lishi bilan esa, baholash yanada murakkablashdi. Fundamental modellarni baholash an'anaviy ML modellarini baholashdan ko'ra qiyinroq ekanligining bir nechta sabablari bor.
Birinchidan, SI modellar qanchalik aqlli bo'lib borgani sari, ularni baholash shunchalik qiyinlashadi. Ko'pchilik birinchi sinf o'quvchisining matematik yechimi noto'g'ri ekanligini ayta oladi. Lekin doktorlik darajasidagi matematik yechim uchun buni qila oladiganlar kam.1 Agar kitob xulosasi bema'ni bo'lsa, uning yomon ekanligini aytish oson, lekin xulosa izchil bo'lsa, buni qilish ancha qiyinroq. Xulosa sifatini tekshirish uchun, avval kitobni o'qib chiqishingiz kerak bo'lishi mumkin. Bu bizni bir natijaga olib keladi: murakkab vazifalar uchun baholash ancha ko'p vaqt talab qilishi mumkin. Siz endi javobni shunchaki qanday eshitilishiga qarab baholay olmaysiz. Sizga faktlarni tekshirish, mulohaza yuritish va hatto sohaviy bilimlarni jalb qilish ham kerak bo'ladi.
Ikkinchidan, fundamental modellarning erkin natijali tabiati modelni etalon javoblar (ground truths) asosida baholashning an'anaviy yondashuvini samarasiz qiladi. An'anaviy ML bilan, aksariyat vazifalar cheklangan natijali (close-ended) bo'ladi. Masalan, tasniflash modeli faqat kutilgan toifalar orasidan javob qaytara oladi. Tasniflash modelini baholash uchun uning natijalarini kutilgan natijalar bilan solishtirish mumkin. Agar kutilgan natija X toifasi bo'lsa-yu, modelning natijasi Y toifasi bo'lsa, demak model xato qilgan. Biroq, erkin natijali vazifa uchun, berilgan bitta kirish ma'lumotiga juda ko'p to'g'ri javoblar bo'lishi mumkin. Solishtirish uchun barcha to'g'ri javoblarning to'liq ro'yxatini tuzib chiqishning imkoni yo'q.
Uchinchidan, aksariyat fundamental modellarga "qora quti" sifatida qaraladi. Buning sababi yo model provayderlari model tafsilotlarini oshkor qilmaslikni tanlashadi, yoki ilova ishlab chiquvchilari ularni tushunish uchun yetarli tajribaga ega bo'lmaydilar. Model arxitekturasi, o'qitish ma'lumotlari va o'qitish jarayoni kabi tafsilotlar modelning kuchli va zaif tomonlari haqida ko'p narsani ochib berishi mumkin. Bu tafsilotlarsiz, siz modelni faqat uning natijalarini kuzatish orqali baholay olasiz.
Shu bilan birga, ommaga taqdim etilgan baholash benchmarklari fundamental modellarni baholash uchun yetarli emasligi ma'lum bo'ldi. Ideal holda, baholash benchmarklari model imkoniyatlarining to'liq ko'lamini qamrab olishi kerak. SI rivojlanib borar ekan, benchmarklar ham unga yetib olish uchun rivojlanishi zarur. Model mukammal ballga erishganda, benchmark ushbu model uchun to'yingan (saturated) bo'ladi. Fundamental modellar bilan, benchmarklar tezda to'yinib bormoqda. GLUE (General Language Understanding Evaluation) benchmarki 2018-yilda chiqdi va atigi bir yilda to'yinib qoldi, bu esa 2019-yilda SuperGLUEning joriy etilishini taqozo etdi. Xuddi shunday, NaturalInstructions (2021) o'rnini Super-NaturalInstructions (2022) egalladi. Ko'plab dastlabki fundamental modellar tayangan kuchli benchmark bo'lgan MMLU (2020) esa, asosan, MMLU-Pro (2024) bilan almashtirildi.
Va nihoyat, eng muhimi, umumiy maqsadli modellar uchun baholash doirasi kengaydi. Maxsus vazifali modellar bilan baholash modelning o'zi o'qitilgan vazifadagi samaradorligini o'lchashni o'z ichiga oladi. Biroq, umumiy maqsadli modellar bilan baholash nafaqat modelning ma'lum vazifalardagi samaradorligini baholash, balki model qila oladigan yangi vazifalarni kashf etish haqida hamdir va bular inson imkoniyatlaridan tashqariga chiqadigan vazifalarni ham o'z ichiga olishi mumkin. Baholash SI'ning salohiyati va cheklovlarini o'rganishdek qo'shimcha mas'uliyatni o'z zimmasiga oladi.
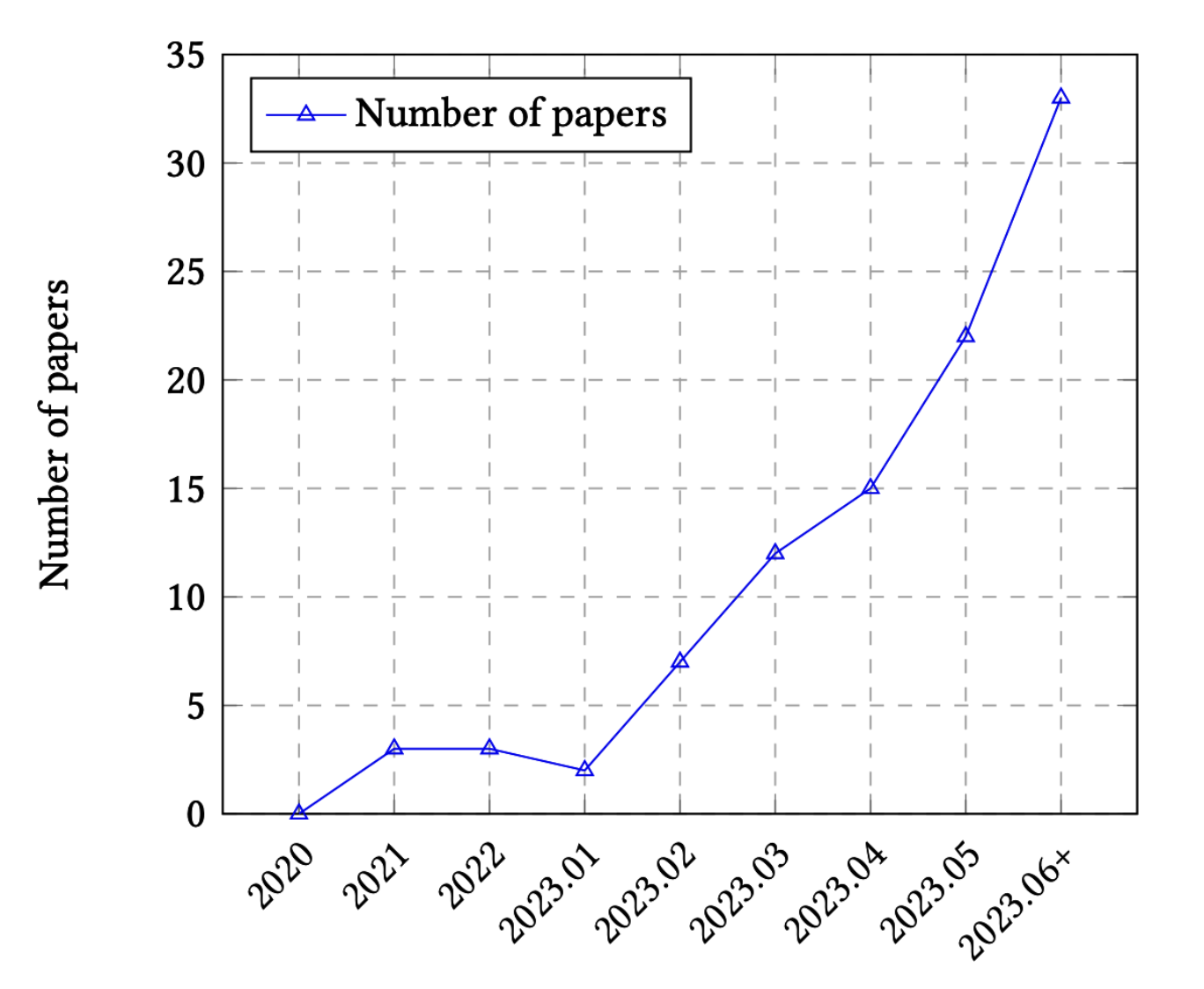
Yaxshi xabar shundaki, baholashdagi yangi qiyinchiliklar ko'plab yangi usullar va benchmarklarning paydo bo'lishiga turtki bo'ldi. 3-1-rasmda ko'rsatilishicha, LLM baholashiga oid nashr etilgan maqolalar soni 2023-yilning birinchi yarmida har oy eksponensial ravishda o'sgan — oyiga 2 ta maqoladan deyarli 35 ta maqolagacha.
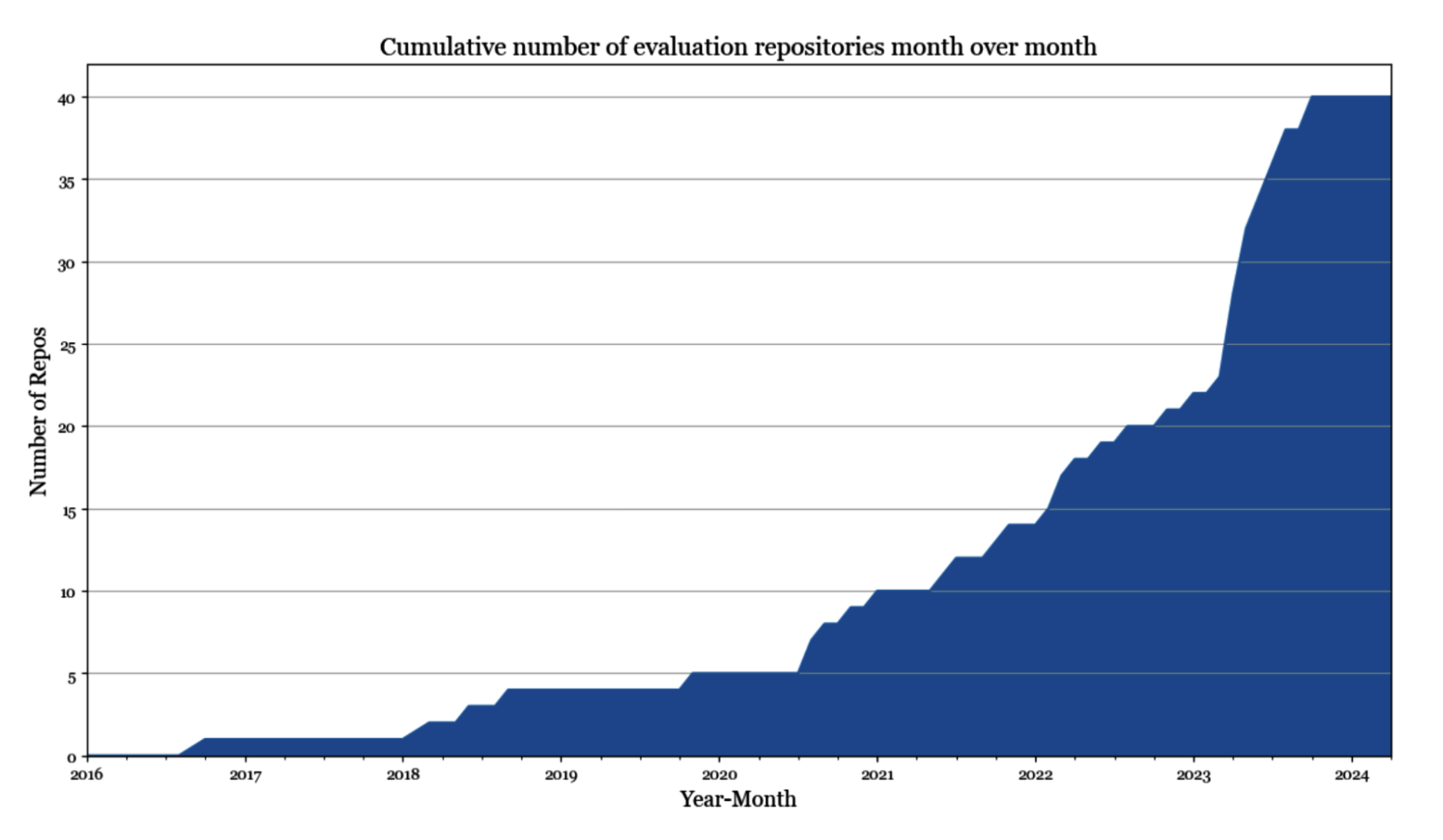
GitHub'dagi yulduzchalar soni bo'yicha saralangan eng yaxshi 1000 ta SI bilan bog'liq repozitoriylarni shaxsan tahlil qilganimda, baholashga bag'ishlangan 50 dan ortiq repozitoriyni topdim (2024-yil may holatiga ko'ra).2 Baholash repozitoriylari sonini ularning yaratilgan sanasi bo'yicha chizib chiqqanda, o'sish egri chizig'i eksponensial ko'rinishga ega bo'ladi (3-2-rasm).
Yomon xabar shundaki, baholashga bo'lgan qiziqishning ortishiga qaramay, u SI muhandisligi jarayonlari zanjirining qolgan qismiga bo'lgan qiziqishdan ortda qolmoqda. DeepMind'dan Balduzzi va boshqalar o'z maqolalarida ta'kidlaganidek, "algoritmlarni ishlab chiqishga nisbatan baholash usullarini ishlab chiqishga tizimli e'tibor kam qaratilgan." Maqolaga ko'ra, tajriba natijalari deyarli faqat algoritmlarni yaxshilash uchun ishlatiladi va baholashni yaxshilash uchun kamdan-kam ishlatiladi. Baholashga sarmoyalarning yetishmasligini tan olgan holda, Anthropic siyosatchilarni yangi baholash metodologiyalarini ishlab chiqish va mavjud baholashlarning mustahkamligini tahlil qilish uchun davlat tomonidan moliyalashtirish va grantlarni ko'paytirishga chaqirdi.
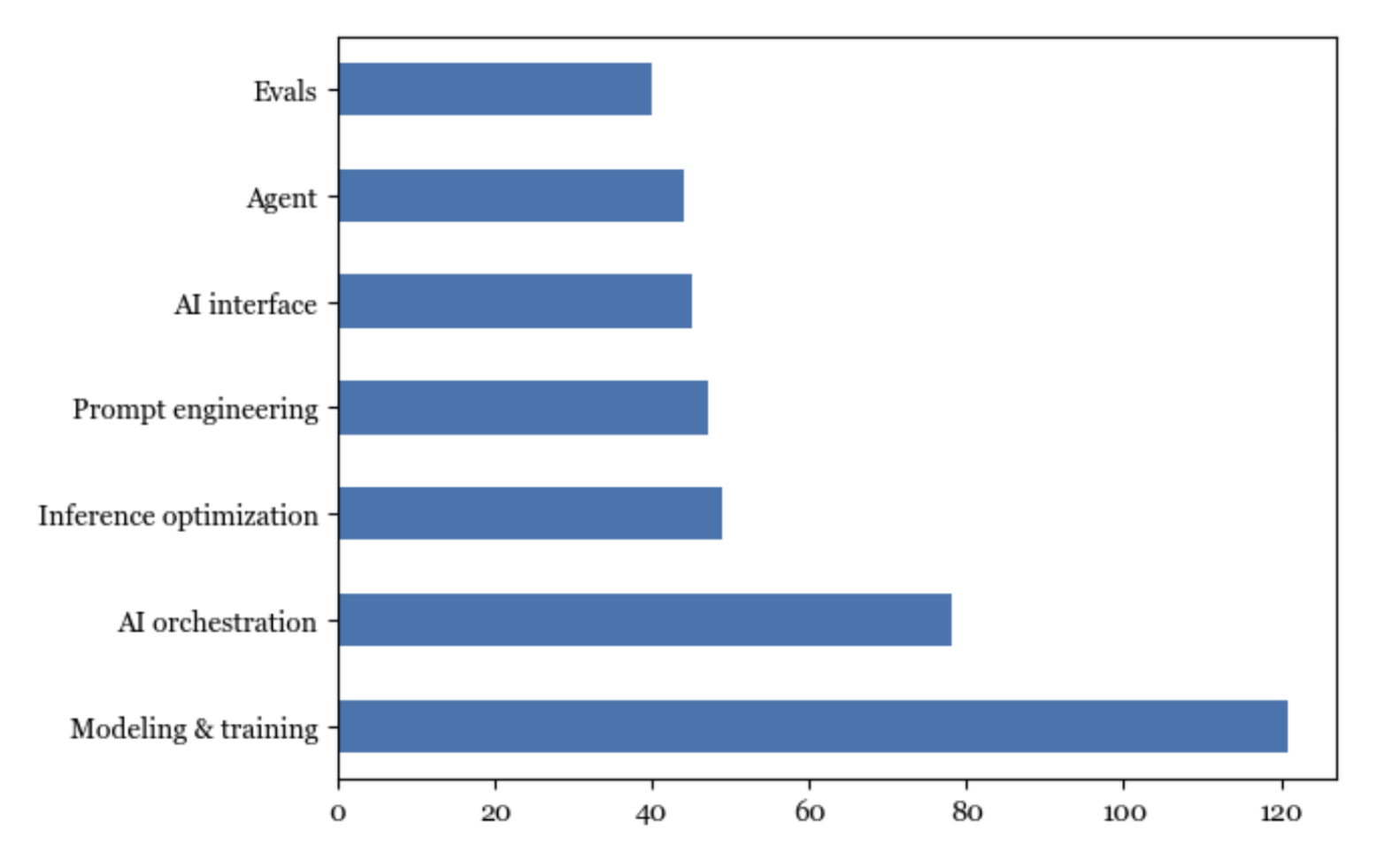
Baholashga qilingan sarmoya SI sohasidagi boshqa yo'nalishlardan qanchalik ortda qolayotganini yanada yaqqolroq ko'rsatish uchun, baholash uchun vositalar soni modellashtirish va o'qitish hamda SI orkestratsiyasi uchun vositalar soniga nisbatan ancha kam (3-3-rasm).
Sarmoyaning yetarli emasligi infratuzilmaning yetarli bo'lmasligiga olib keladi, bu esa odamlarga tizimli baholashni amalga oshirishni qiyinlashtiradi. O'zlarining SI ilovalarini qanday baholayotganliklari so'ralganda, ko'pchilik menga natijalarni shunchaki ko'z bilan chamalab ko'rishlarini aytishdi. Ko'pchilikda modellarni baholash uchun foydalanadigan kichik "navbatchi" promptlar to'plami bor. Ushbu promptlarni saralash jarayoni vaziyatga qarab amalga oshiriladi va odatda ilovaning ehtiyojlariga emas, balki saralovchining shaxsiy tajribasiga asoslanadi. Loyihani endi boshlayotganda bu "vaziyatga qarab" yondashuv bilan qutulib qolishingiz mumkin, ammo ilovani takomillashtirib borish uchun bu yetarli bo'lmaydi. Ushbu kitob baholashga tizimli yondashishga qaratilgan.
Izohlar
-
2024-yil sentabr oyida OpenAI'ning
GPT-o1modeli chiqqanda, Filds medali sohibi Terrens Tao bu model bilan ishlash tajribasini "o'rtamiyona, lekin butunlay qobiliyatsiz bo'lmagan aspirant" bilan ishlashga qiyosladi. Uning taxminicha, SI "qobiliyatli aspirant" darajasiga yetishi uchun yana bir yoki ikki takomillashtirish kifoya qilishi mumkin. Uning bahosiga javoban, ko'pchilik hazillashib, agar biz allaqachon SI modellarini baholash uchun eng yorqin insoniy aqllarga muhtoj bo'lgan nuqtaga kelgan bo'lsak, kelajakdagi modellarni baholashga malakali odamimiz qolmaydi, deyishdi. ↩ -
Men "LLM", "GPT", "generative" va "transformer" kalit so'zlari yordamida kamida 500 yulduzchaga ega bo'lgan barcha repozitoriylarni qidirdim. Shuningdek, o'z veb-saytim https://huyenchip.com orqali yetishmayotgan repozitoriylar uchun kraudsorsing qildim. ↩